 Hive工作原理与实战:建表、分区、分桶与数据操作
Hive工作原理与实战:建表、分区、分桶与数据操作








 超级会员免费看
超级会员免费看
 本文详细介绍了Hive的工作原理,包括SQL查询如何转换为MapReduce作业,元数据信息的管理,以及Hive的建表方式、文件格式、内外部表、分区和分桶的使用。此外,还讨论了Hive中的数据加载、导出、删除和表属性修改等操作,展示了如何高效管理和操作Hive数据。
本文详细介绍了Hive的工作原理,包括SQL查询如何转换为MapReduce作业,元数据信息的管理,以及Hive的建表方式、文件格式、内外部表、分区和分桶的使用。此外,还讨论了Hive中的数据加载、导出、删除和表属性修改等操作,展示了如何高效管理和操作Hive数据。
一、Hive系统架构
Hive 底层执行架构
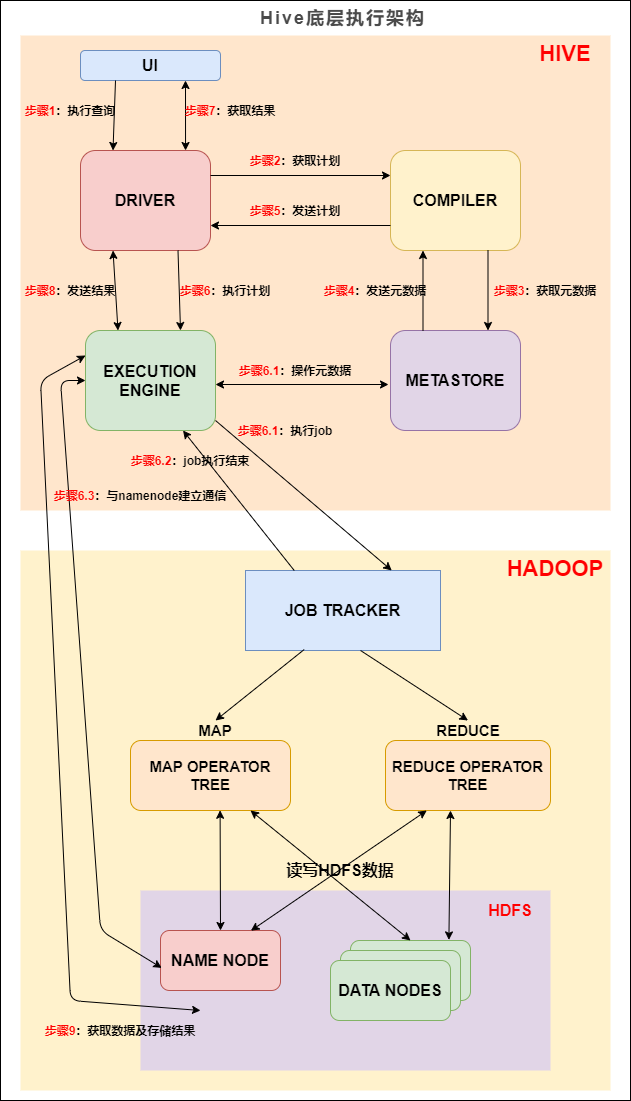
在 Hive 这一侧,总共有五个组件:
- UI:用户界面。可看作我们提交SQL语句的命令行界面。
- DRIVER:驱动程序。接收查询的组件。该组件实现了会话句柄的概念。
- COMPILER:编译器。负责将 SQL 转化为平台可执行的执行计划。对不同的查询块和查询表达式进行语义分析,并最终借助表和从 metastore 查找的分区元数据来生成执行计划.
- METASTORE:元数据库。存储 Hive 中各种表和分区的所有结构信息。
- EXECUTION ENGINE:执行引擎。负责提交 COMPILER 阶段编译好的执行计划到不同的平台上。
上图的基本流程是:
- 步骤1:UI 调用 DRIVER 的接口;
- 步骤2:DRIVER 为查询创建会话句柄,并将查询发送到 COMPILER(编译器)生成执行计划;
- 步骤3和4:编译器从元数据存储中获取本次查询所需要的元数据,该元数据用于对查询树中的表达式进行类型检查,以及基于查询谓词修建分区;
- 步骤5:编译器生成的计划是分阶段的DAG,每个阶段要么是 map/reduce 作业,要么是一个元数据或者HDFS上的操作。将生

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











