







 本文探讨了线程池的原理与应用,包括池化技术的优势与局限性,线程池参数设置策略,以及如何根据任务类型选择合适的线程数。此外,还介绍了Spring的线程池组件ThreadPoolTaskExecutor的特点。
本文探讨了线程池的原理与应用,包括池化技术的优势与局限性,线程池参数设置策略,以及如何根据任务类型选择合适的线程数。此外,还介绍了Spring的线程池组件ThreadPoolTaskExecutor的特点。
线程池の优雅使用
“池化”技术
池化技术是一种常见的软件设计思想,它的核心思想是空间换时间。你会发现Java的线程池跟数据库的连接池有异曲同工之妙——它们所管理的对象,无论是连接还是线程,它们的创建过程都比较耗时,也比较消耗系统资源。所以,我们把它们放在一个池子里统一管理起来,以达到提升性能和资源复用的目的。
优点:
- 期望使用预先创建好的对象来减少频繁创建对象的性能开销
- 对对象进行统一的管理,也便于并发访问控制
- 降低了对象的使用的成本
缺点:
- 存储池子中的对象肯定需要消耗多余的内存,如果对象没有被频繁使用,就会造成内存上的浪费。
- 池子中的对象需要在系统启动的时候就预先创建完成,这在一定程度上增加了系统启动时间。
只要我们确认要使用的对象在创建时确实比较耗时或者消耗资源,并且这些对象也确实会被频繁地创建和销毁,我们就可以使用池化技术来优化。
不过我们本篇还是重点研究Java的线程池,源码JDK1.8
线程池の应用
实际上,线程池的应用随处可见。
Tomcat线程池
Tomcat接受请求之后会转交给线程池处理,这样可以有效提高处理的能力与并发度。Tomcat采用的并不是JDK提供的线程池,而是实现了自己的TaskQueue,更改了JDK线程池的线程创建逻辑:先让线程池中的线程到达最大线程数量,再让请求入队等候。
个人觉得Tomcat的线程池设计的原因是,tomcat线程池希望的就是处理尽可能多的请求,实在处理不了再去队列排队等候,而不是核心线程数满了先入队再扩充,显然降低这些请求总体处理速度。
SpringCloud的Hystrix的线程池隔离
Hystrix组件的核心功能就是提供服务容错保护,并且防止任何单一依赖使用掉整个容器(如Tomcat)的全部用户线程。Hystrix是通过舱壁隔离模式来实现对资源的隔离,防止微服务的雪崩效应。它为每个命令的执行提供一个小的线程池/信号量,当线程池/信号已满,就会立即拒绝执行该命令,直接转入服务降级处理。所以,Hystrix不仅会保护我们的服务,防止请求资源失败造成整个系统垮掉,同时也会对我们的服务进行限流保护,防止过多的请求冲垮我们的服务。
Spring的@Async注解
@Async是Spring提供的一个异步执行方法注解,它默认使用Spring创建的线程去执行任务。
项目中的应用
动态扩展线程池
稍后再补
线程池の使用
JDK的线程池ThreadPoolExecutor
在之前的博客里有阅读过ThreadPoolExecutor类的源码,创建线程池有几个主要参数:
-
corePoolSize:核心线程数(线程池中要保留的线程数,哪怕它们处于空闲状态也不会被回收)
-
maximumPoolSize:最大线程池容量
-
keepAliveTime:空闲的非核心线程的最大空闲时间
-
unit:keepAliveTime的单位
-
workQueue:任务队列
-
threadFactory:创建线程的线程工厂
-
handler:任务的拒绝策略
后面我发现其实还有一个参数和方法:
private volatile boolean allowCoreThreadTimeOut;
public void allowCoreThreadTimeOut(boolean value)
通过这个参数,你就可以设置线程池的核心线程超时时间,也就是说,你可以按照你的业务需求选择是否保留几个核心线程。
关于线程池参数的思考
线程池容量相关共有三个参数:核心线程数、任务队列、最大线程数。
创建线程的逻辑之前阅读源码后得出:
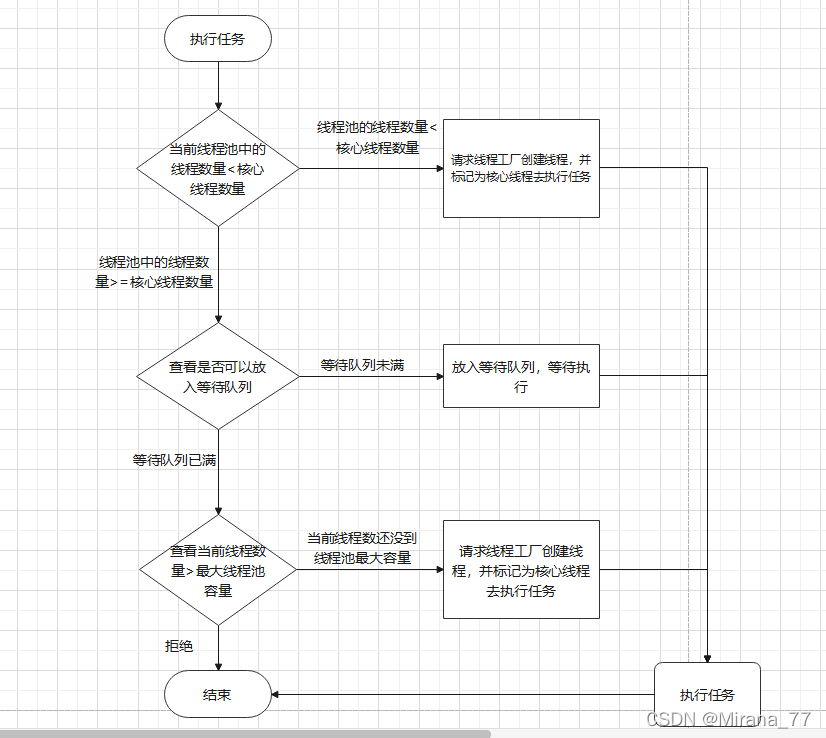
关于线程池设计的一点思考:
Q:为什么是核心线程数->入队->最大线程数这样的设计思路,而不是核心线程数->最大线程数->入队这样呢?
A:个人认为有两个原因:
假设线程池的配置是:核心线程数为n+有界队列+最大线程数m,n<m
-
这种设计思路更适用于执行 CPU 密集型的任务,因为执行 CPU 密集型的任务时 CPU 比较繁忙,因此只需要创建和 CPU 核数相当的线程就好了,多了反而会造成线程上下文切换,降低任务执行效率。所以当当前线程数超过核心线程数时,线程池不会增加线程,而是放在队列里等待核心线程空闲下来;
如果是IO密集型任务,比方说查询数据库、查询缓存等等。任务在执行 IO 操作的时候 CPU 就空闲了下来,这时如果增加执行任务的线程数而不是把任务暂存在队列中,就可以在单位时间内执行更多的任务,大大提高了任务执行的吞吐量,所以Tomcat 使用的线程池就选择优先创建到线程池最大容量再入队。
-
核心线程数->入队->最大线程数这种设计的扩展性更高;假设你经过一段时间的监控,发现你们的系统的平均并发量恰巧就是你们服务器的最大承受线程数,也就是根本不需要队列去做缓冲,那你可以直接将线程池的队列设置为容量为0,参考CachedThreadPool
Q:如果我就是想核心线程数->最大线程数->入队,要怎么实现呢?
A:有两种实现方式。low一点点自定义实现ThreadPoolExecutor,改写excute方法,将判断maxSize跟入队的逻辑颠倒过来,但是缺点是ThreadPoolExecutor类中的关键方法大部分都是私有的,你要原封不动的照搬。
优雅一点的方法:自己实现队列,更改入队判断逻辑,先判断线程池数量是否到达最大值,没到达返回false直接让线程池创建新线程;如果线程池已到达最大容量,再入队。
稍后晚点再自己写demo实现下先线程池满再入队的线程池以及对Tomcat线程池源码进行分析。
总结
- 核心线程数与最大线程数与任务队列,这三个参数的各种组合基本上可以满足了线程池的大部分使用场景,让我们得线程池有一定的扩展能力并可以按照我们的设定去执行任务
核心线程数与最大线程数+keepAliveTime与allowCoreThreadTimeOut可以保证我们的线程具有伸缩能力,在流量峰值情况下能够及时响应,在流量低谷的时候也不至于有太多waiting空闲等待的线程,不设置allowCoreThreadTimeOut可以保证核心线程不会被回收,在面临流量波峰的时候,线程数不需要从0增加到maxSize
任务队列可以让我们指定在资源有限的场景下,通过什么样的排队方式来削峰或者干脆限流,队列的堆积量是需要监控的重要指标,对于实时性要求比较高的任务来说,这个指标尤为关键。
- 通过自定义拒绝策略我们可以按照业务需求,制定当线程池中没有空闲线程时到底如何拒绝后面的请求——直接丢弃还是抛个异常还是阻塞还是写个日志等等;
- 通过实现ThreadFactory,我们可以指定线程池中使用的线程到底有什么特性:优先级,有意义的线程名称,或者是守护线程等等。
Spring的线程池ThreadPoolTaskExecutor
ThreadPoolTaskExecutor是Spring为我们提供的线程池,它的内部持有一个ThreadPoolExecutor,相比JDK提供的ThreadPoolExecutor,它有几个优点:
- ThreadPoolTaskExecutor是作为一个bean受到Spring管理的,这意味着我们可以省去很多麻烦,不需要操心它的生命周期,关闭线程池的时候也会简单很多
- 可以动态调整corePoolSize、maxPoolSize、keepAliveSeconds等参数
ThreadPoolTaskExecutor有几个默认设置的参数:
- 默认核心线程数corePoolSize是1
- 默认最大线程数maxPoolSize是无上限的,也就是Integer.MAX_VALUE
- 默认非核心线程空闲存活时间keepAliveSeconds是60
- 默认任务队列是无界的也就是Integer.MAX_VALUE
- 默认队列是LinkedBlockingQueue,如果设置队列容量为0则是SynchronousQueue
- 默认核心线程超时回收allowCoreThreadTimeOut为false
如何优雅的关闭线程池
见下篇
线程池の几个小建议
1.线程池创建的线程最好起有意义的名字,可以通过实现我们自己的ThreadFactory接口来给每个创建的线程加上有意义的名字
2.如果使用默认的拒绝策略也需要注意,因为抛出的RejectedExecutionException异常是运行时异常,编译器并不会强制去处理。而使用excute方法提交任务时,如果任务执行的过程中出现运行时异常,执行任务的线程也会终止,但是如果不加处理也不会收到任何通知。所以,最好参考下面的方法处理:
try{
//业务
}catch (RuntimeException runtimeException){
//按需处理
}catch (Throwable e){
//按需处理
}
3.自定义线程池,创建多少线程合适呢?
这时可以根据我们要执行的是CPU密集型任务还是耗时IO型任务,当然最终还是要根据压测结果来决定。
CPU密集型任务:
如加密、计算hash等
最佳线程数设置为CPU数量的1-2倍即可
耗时IO型任务:
如读写数据库、文件、网络读写等
此时最佳线程数一般会大于cpu核心数很多倍,以JVM线程监控显示繁忙情况为依据,保证线程空闲可以接上,参考Brain Goetz推荐的计算方法:
线程数=CPU核心数*(1+平均等待时间/平均工作时间)
4.使用线程池传递ThreadLocal变量的时候要注意,需要包装下Runnable,具体可以参考我之前写过的:
https://blog.youkuaiyun.com/qq_20952591/article/details/121457107
5.池化技术核心是一种空间换时间优化方法的实践,所以要关注空间占用情况,避免出现空间过度使用出现内存泄露或者频繁垃圾回收等问题。
6.尽量不要把队列设为无界队列,大量的任务堆积会占用大量的内存空间,一旦内存空间被占满就会频繁地触发 Full GC,造成服务不可用
相关博客:
https://blog.youkuaiyun.com/qq_20952591/article/details/121457107
https://blog.youkuaiyun.com/qq_20952591/article/details/121383152
相关文档参考:
https://docs.spring.io/spring-framework/docs/4.3.23.RELEASE/spring-framework-reference/htmlsingle/

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









