






一 引言
玩过塞尔达的小伙伴都知道,要想救公主,要经历以下的步骤(当然也可以拿到滑翔伞直接打boss........),其中拔出大师之剑不光要解锁迷雾森林,还要解锁神庙增加心之容器,也就是说两个条件必须同时满足,之后再解放四神兽,击败盖侬救出公主
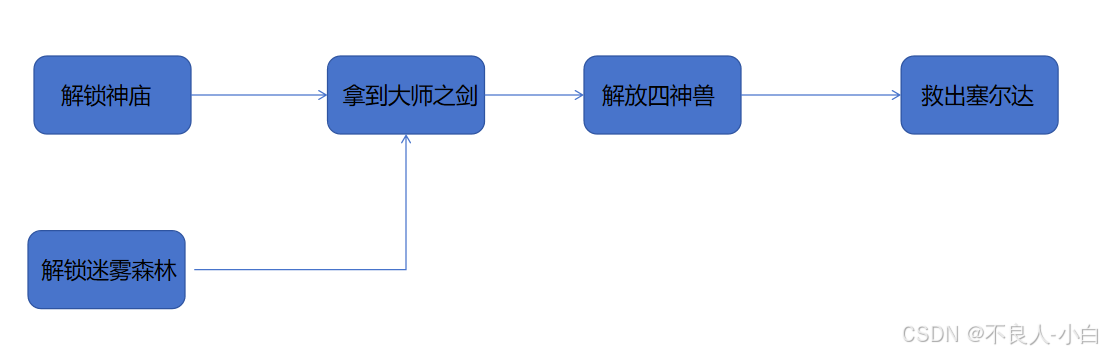
可以看出任务之间有先后顺序的,图中的任务有的难,有的简单,但是不重要,拓扑只考虑它们之间的先后依赖关系,而不考虑它们自身的属性,这也是为什么叫做拓扑排序的原因。拓扑排序是指对于一个有向无环图(DAG, Directed Acyclic Graph),找到一种线性排列的方式,使得对于每一条从顶点u到v的有向边(u, v),u在排序结果中都出现在v之前。换句话说,它是一种将图中的节点按某种顺序排列的方法,以确保所有的依赖关系都能得到满足。
为什么必须是无环图?
拓扑排序要求对于每条有向边 (u, v),顶点 u 必须出现在顶点 v 之前。如果图中存在环,则环内的所有顶点都相互依赖,没有一个明确的起点或终点可以开始排序。换句话说,在环内不存在任何一个顶点可以在另一个顶点之前处理。
二 应用
拓扑排序在许多领域都有广泛的应用,尤其是在处理依赖关系方面:
1 任务调度:例如项目管理、构建系统中的任务依赖解析。
2 编译器优化:确定代码模块或函数之间的调用顺序。
3 网络路由中的优先级处理等领域
4 包管理器中的依赖解析:如npm、Maven等工具中软件包安装顺序的确定。
5 课程安排:规划学习路径,确保先修课程被正确安排在后续课程之前。
6 数据库迁移脚本生成:保证表创建、修改等操作按照正确的依赖顺序执行。
7 游戏开发:比如资源加载顺序、关卡解锁条件、技能树等。
三 实现
Kahn算法
1 思路
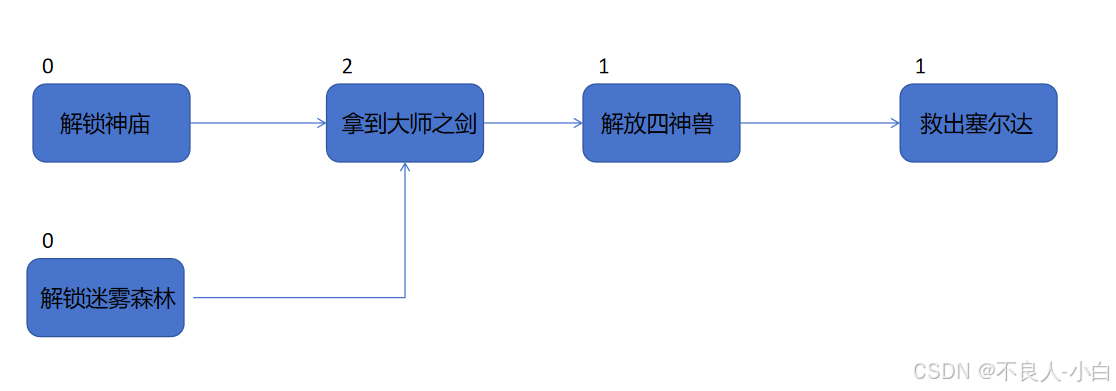
既然是处理依赖关系,那么就可以从入度为0的节点开始,像剥洋葱一样一层一层深入到最里层。比如对于开头说的塞尔达,
(1) 先找到所有入度(即指向该节点的边的数量)为0的任务,发现是解锁神庙和解锁迷雾森林
(2) 一个一个处理入度为0的任务,处理的方式就是将入度为0的任务和它的边删除,同时将它指向的任务的入度减去1
(3) 解锁神庙处理完以后,入度为0的任务只剩下解锁迷雾森林,同时拿到大师之剑的任务的入度变成1。再处理解锁迷雾森林后,拿到大师之剑的入度变成0,这时候就该处理拿到大师之剑的任务。
(4)依次类推,直到救出塞尔达的入度为0,处理完成。通过迭代地移除入度为0的节点来构建排序结果被称作Kahn算法。
2 步骤
1 计算每个节点的入度
2 初始化一个队列,包含所有入度为0的节点。
3 从队列中取出一个节点,将其加入拓扑排序的结果列表,并减少其所有邻接节点的入度。
4 如果某个邻接节点的入度变为0,则将其加入队列。
5 重复步骤3-4直到队列为空。
6 如果结果列表中的节点数量等于原始图中的节点数,则返回结果;否则,图中存在环。
3 代码
这里我们使用jgrapht提供的类
package jgrapht;
import org.jgrapht.Graphs;
import org.jgrapht.graph.DefaultWeightedEdge;
import org.jgrapht.graph.SimpleDirectedWeightedGraph;
import org.jgrapht.traverse.TopologicalOrderIterator;
import java.util.*;
public class TuoPu {
public static void main(String[] args) {
SimpleDirectedWeightedGraph<String, DefaultWeightedEdge> graph = new SimpleDirectedWeightedGraph<>(DefaultWeightedEdge.class);
// 添加顶点
String v1 = "解锁神庙";
String v2 = "解锁迷雾森林";
String v3 = "拿到大师之剑";
String v4 = "解放四神兽";
String v5 = "救出塞尔达";
graph.addVertex(v1);
graph.addVertex(v2);
graph.addVertex(v3);
graph.addVertex(v4);
graph.addVertex(v5);
// 添加边
DefaultWeightedEdge edge13 = graph.addEdge(v1, v3);
graph.setEdgeWeight(edge13, 1.0);
DefaultWeightedEdge edge23 = graph.addEdge(v2, v3);
graph.setEdgeWeight(edge23, 10.0);
DefaultWeightedEdge edge34 = graph.addEdge(v3, v4);
graph.setEdgeWeight(edge34, 1.0);
DefaultWeightedEdge edge45 = graph.addEdge(v4, v5);
graph.setEdgeWeight(edge45, 1.0);
List<String> strings = topoSort(graph);
System.out.println(strings);
}
public static List<String> topoSort(SimpleDirectedWeightedGraph<String, DefaultWeightedEdge> graph){
// 存放排序结果
List<String> result = new ArrayList<>();
// 存放顶点的入度
Map<String, Integer> inDegree = new HashMap<>();
// 存放入度为0的顶点
Queue<String> queue = new LinkedList<>();
// 初始化入度表
for (String vertex : graph.vertexSet()) {
inDegree.put(vertex, graph.inDegreeOf(vertex));
// 将入度为0的顶点加入队列
if (inDegree.get(vertex) == 0) {
queue.add(vertex);
}
}
// 记录访问过的节点数
int count = 0;
while (!queue.isEmpty()) {
String vertex = queue.poll();
result.add(vertex);
count++;
// 对于当前节点的所有邻接节点,减少其入度
for (String neighbor : Graphs.successorListOf(graph, vertex)) {
inDegree.put(neighbor, inDegree.get(neighbor) - 1);
if (inDegree.get(neighbor) == 0) {
queue.add(neighbor);
}
}
}
// 检查是否所有的节点都被处理了,即是否存在环
return count == graph.vertexSet().size() ? result : Collections.emptyList();
}
}
当然我们实际使用时不必自己实现,jgrapht提供了拓扑排序的方法
// 创建拓扑排序迭代器
TopologicalOrderIterator<String, DefaultWeightedEdge> topoIterator = new TopologicalOrderIterator<>(graph);
// 遍历并打印拓扑排序结果
while (topoIterator.hasNext()) {
String vertex = topoIterator.next();
System.out.println(vertex);
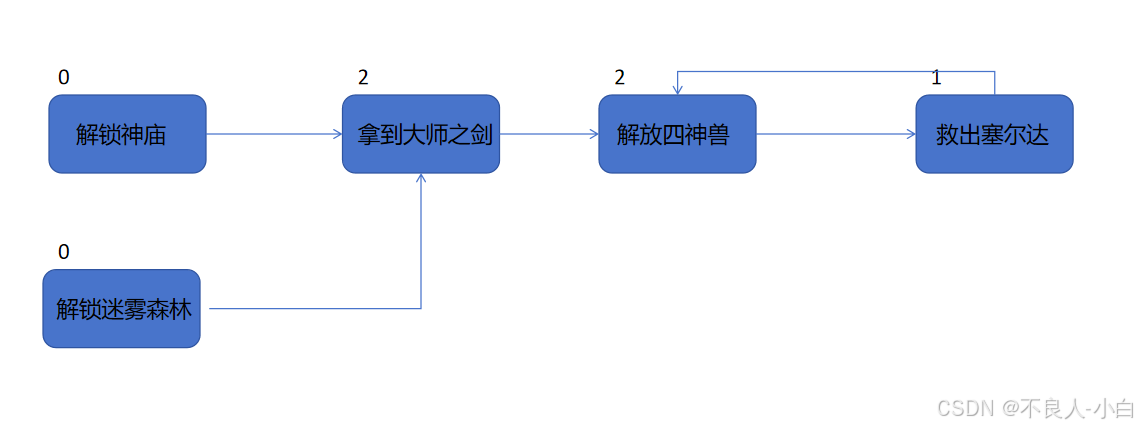
}可以看出来kahn算法还是比较简单的,同时它还能判断是否有环的存在,因为一旦出现环,比如下面这样,那么由于解放四神兽的入度无法更新为0,导致处理的节点数量少于图中的节点数量,无法排序
DFS算法
1 思路
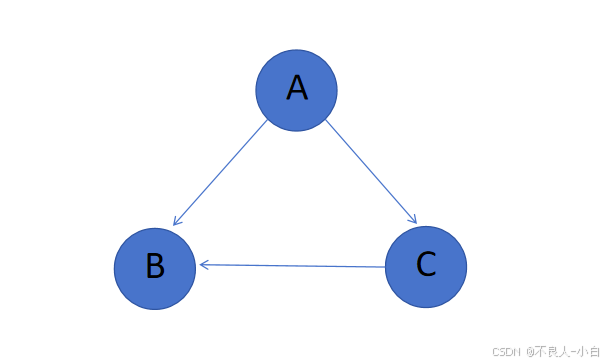
前序访问与后序访问
前序访问:指的是在递归地访问一个节点的所有邻接节点之前先访问该节点本身
比如上图中前序遍历的结果为A, B,C或者是A,C,B
后序访问:指的是在递归地访问并处理完一个节点的所有邻接节点之后再访问该节点
比如上图中后序遍历的结果为B,C,A
DFS 遍历与后续遍历:
在标准的 DFS 中,我们从某个起始节点开始,尽可能深入地探索该节点的所有子节点。使用后续访问,当我们回溯到一个节点并准备离开它时,该节点的所有邻接节点已经被访问过。
比如图中B没有子节点,B加入结果列表,C的子节点B被处理以后,C没有子节点,C加入结果列表,最后将A加入结果列表。可以看到这个结果是从最里层向外的顺序,如果我们直接使用这个顺序,它并不符合拓扑排序的要求(即父节点应在子节点之前)。因此,我们需要对这个顺序进行反转。通过反转后续遍历得到的结果,我们可以确保对于每条有向边 (u, v),顶点 u 总是出现在顶点 v 之前,从而满足拓扑排序的条件。
2 步骤
(1)初始化:
创建一个布尔型映射 visited 来跟踪每个节点的访问状态。
创建一个栈来存储最终的拓扑排序结果。
(2)递归 DFS 函数:
对于每个未访问的节点启动一次 DFS。
在每次递归调用中,标记当前节点为已访问,并递归地访问其所有未访问过的邻接节点。
关键点:当从一个节点及其所有邻接节点返回时(即在后续访问阶段),将该节点压入栈中或添加到结果列表的末尾。
(3)处理所有节点:
确保对图中的每一个节点都进行了检查和可能的 DFS 调用,因为可能存在不连通的子图。
(4)逆转顺序:
由于使用的是栈,则可以直接弹出元素作为排序结果,因为栈的特性(后进先出)正好满足我们需要的逆序。
(5)环检测(可选):
在 DFS 的过程中,可以通过引入额外的状态(如“正在访问”)来检测环的存在。如果遇到一个已经标记为“正在访问”的节点,则说明存在环,此时应停止排序过程并报告错误。可以参考这篇博客:有向图检测环(DFS思路分析)-优快云博客。
3 代码
package jgrapht;
import org.jgrapht.Graphs;
import org.jgrapht.graph.DefaultWeightedEdge;
import org.jgrapht.graph.SimpleDirectedWeightedGraph;
import java.util.*;
public class TuoPu {
public static void main(String[] args) {
SimpleDirectedWeightedGraph<String, DefaultWeightedEdge> graph = new SimpleDirectedWeightedGraph<>(DefaultWeightedEdge.class);
// 添加顶点
String v1 = "A";
String v2 = "B";
String v3 = "C";
graph.addVertex(v1);
graph.addVertex(v2);
graph.addVertex(v3);
// 添加边
DefaultWeightedEdge edgeAB = graph.addEdge(v1, v2);
graph.setEdgeWeight(edgeAB, 1.0);
DefaultWeightedEdge edgeAC = graph.addEdge(v1, v3);
graph.setEdgeWeight(edgeAC, 1.0);
DefaultWeightedEdge edgeCB = graph.addEdge(v3, v2);
graph.setEdgeWeight(edgeCB, 1.0);
// 初始化访问状态
Map<String, Boolean> visited = new HashMap<>();
for (String vertex : graph.vertexSet()) {
visited.put(vertex, false);
}
// 存放后续遍历结果
Stack<String> stack = new Stack<>();
for (String vertex : graph.vertexSet()) {
if (!visited.get(vertex)) {
dfsRecursive(graph, vertex, visited, stack);
}
}
System.out.println("递归DFS遍历结果:");
for (String s : stack) {
System.out.println(s + " ");
}
}
private static void dfsRecursive(SimpleDirectedWeightedGraph<String, DefaultWeightedEdge> graph, String vertex, Map<String, Boolean> visited, Stack<String> stack) {
// 标记当前节点为已访问并打印它
visited.put(vertex, true);
// 遍历邻接节点
for (String neighbor : Graphs.successorListOf(graph, vertex)) {
if (!visited.get(neighbor)) {
dfsRecursive(graph, neighbor, visited, stack);
}
}
// 后续访问节点入栈
stack.push(vertex);
}
}
四 思考
这两种排序的区别是什么?哪种方式更好?


















 579
579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











