







 本文介绍了使用Python的lxml库进行XML和HTML内容解析,包括XPath表达式提取节点信息,以及JSONPath对JSON数据的解析方法。示例展示了如何提取XML文档中的文本、HTML文档中的链接内容,以及从复杂JSON数据结构中筛选特定值。
本文介绍了使用Python的lxml库进行XML和HTML内容解析,包括XPath表达式提取节点信息,以及JSONPath对JSON数据的解析方法。示例展示了如何提取XML文档中的文本、HTML文档中的链接内容,以及从复杂JSON数据结构中筛选特定值。
path解析
安装xpath:pip install lxml
xpath是xml文档搜索中的语言,html是xml的一个子集,xpath通过节点的路径进行查找。
from lxml import etree
#xpath解析
xml = """
<book>
<id>1</id>
<name>book1_name</name>
<price>23.4</price>
<nick>nick1</nick>
<author>
<nick id="n1">author nick id="n1"</nick>
<nick id="n2">author nick id="n2"</nick>
<nick class="joy">author nick class="joy"</nick>
<nick class="jolin">author nick class="jolin"</nick>
<div>
<nick>author div nick1</nick>
</div>
<span>
<nick>author span nick2</nick>
<div>
<nick>author span div nick</nick>
</div>
</span>
</author>
<partner>
<nick id="n3">partner nick id="n3"</nick>
<nick id="n4">partner nick id="n4"</nick>
</partner>
</book>
"""
tree = etree.XML(xml) #把内容加载为etree的对象
# result = tree.xpath("/book/name") #/表示层级关系,第一个为根节点
# result = tree.xpath("/book/name/text()") #/text()表示拿节点里的内容
# result = tree.xpath("/book/author/nick/text()") #
# result = tree.xpath("/book/author//nick/text()") #//表示取所有后代
result = tree.xpath("/book/author/*/nick/text()") # *表示任意的节点,即通配符
# print(result)
htmlTree = etree.parse('xpath.html') #etree.parse()直接接受一个文档,按照文档结构解析(本地文件)
print("----------")
print(type(htmlTree))
# htmlResult = htmlTree.xpath('/html/body/ul/li[1]/a/text()') #xpath顺序从1开始,[]表示索引,即筛选li的1位置的值
htmlResult = htmlTree.xpath("/html/body/ol/li/a[@href='dapao']/text()") #[@href='dapao']表示搜索href属性值为dapao的值
# print(htmlResult)
ol_liList =htmlTree.xpath("/html/body/ol/li")
print(len(ol_liList))
for li in ol_liList:
liResult = li.xpath("./a/text()") # ./表示从当前节点出发,即相对路径
print(liResult)
liResult2 = li.xpath("./a/@href") # /@属性 表示取其属性值
print(liResult2)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Title</title>
</head>
<body>
<ul>
<li><a href="http://www.baidu.com">baidu</a> </li>
<li><a href="http://www.google.com">google</a> </li>
<li><a href="http://www.sogou.com">sogou</a> </li>
</ul>
<ol>
<li><a href="feiji">feiji</a> </li>
<li><a href="dapao">dapao</a> </li>
<li><a href="huojian">huojian</a> </li>
</ol>
<div class="man">lijiacheng</div>
<div class="food">qiaokeli</div>
</body>
</html>
例子:爬猪八戒网
import requests
from lxml import etree
url = "https://www.zbj.com/search/service/?kw=saas"
resp = requests.get(url)
resp.encoding = resp.apparent_encoding
# print(resp.text)
#解析
html = etree.HTML(resp.text) #etree.html()可以解析html文件:(服务器上返回的html数据)
resp.close()
# print(type(html))
divList = html.xpath("/html/body/div[1]/div/div/div[3]/div/div[4]/div[4]/div[1]/div")
print(len(divList))
for div in divList:
price = str(div.xpath("./div/div[3]/div[1]/span/text()")).strip("[]''")
title = "saas".join(div.xpath("./div/div[3]/div[2]/a/text()"))
comName = str(div.xpath("./div/a/div[2]/div[1]/div/text()")).strip("[]''")
print(title+price+comName)
jsonpath解析
data = { "store": {
"book": [
{ "category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{ "category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{ "category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
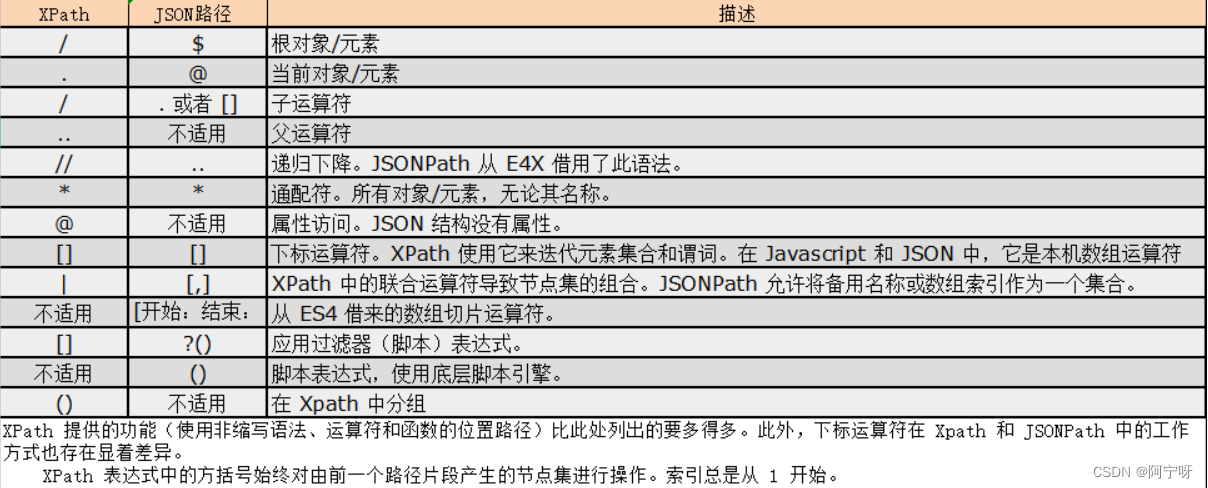
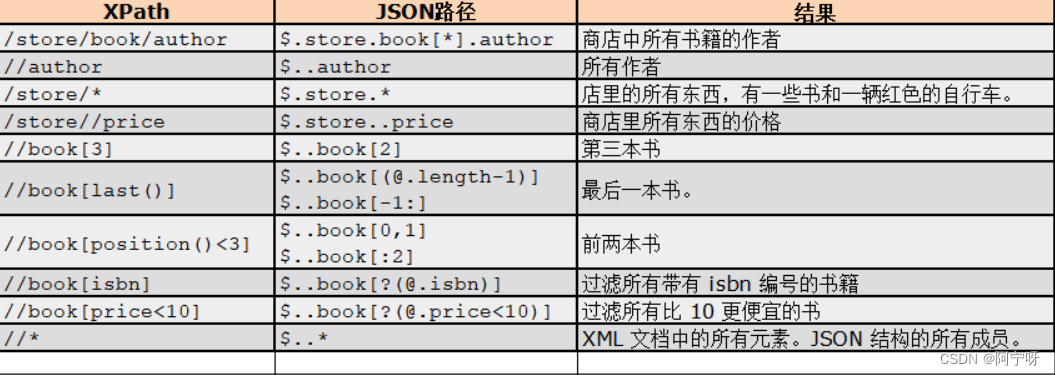
XPath解析和JSONPath解析的区别
import jsonpath
testdata = {
"code": 0,
"status": 1,
"data": {
"list": [
{
"stockOutId": "1467422726779043840",
"orderId": "1467422722362441728",
"id": "1467422722362441728",
"stockOutStatus": {
"name": "待出库",
"value": 0,
"description": "待出库"
},
"orderStatus": {
"name": "待付款",
"value": 0,
"description": "待付款"
},
"orderPayType": {
"name": "货到付款",
"value": 1,
"description": "货到付款"
},
"orderDeliveryWay": {
"name": "物流配送",
"value": 0,
"description": "物流配送"
},
"orderTradeType": {
"name": "即时到帐交易",
"value": 4,
"description": "即时到帐交易"
},
"stockOutType": {
"name": "制单出库",
"value": 1,
"description": "制单出库"
},
"creator": 9002257,
"reviser": 9002257,
"createTime": "2021-12-05 17:16:55",
"shippingFee": 0,
"totalAmount": 629,
"sumProductPayment": 629,
"currency": "RMB",
"toFullName": "张德天",
"toAddress": None,
"toFullAddress": "湖北省武汉市洪山区街道口",
"storageName": "初始仓库",
"orderTime": "2021-12-05 17:16:55",
"isSplit": 0,
"packageNum": "1/1",
"stockOutCreateTime": "2021-12-05 17:16:56",
"stockOutToFullName": "张德天",
"stockOutToFullAddress": "湖北省武汉市洪山区街道口",
"creatorName": "监狱账号联系人",
"stockOutTotalQuantity": 5,
"stockOutTotalAmount": 629,
"reviserName": "监狱账号联系人",
"outNo": "WB2;0211206171552638541",
"tenantId": 363635127,
"orderNo": "WD20211205622150001",
"stockOutOutNo": "WB20211206171552638541",
"toReceiveTime": "2021-12-05 17:16:55",
"stockOutBespeakTime": "2021-12-05 17:15:00",
"stockOutNo": "CK2021120562128001"
},
{
"stockOutId": "1467512423597473792",
"orderId": "1467512420523048960",
"id": "1467512420523048960",
"stockOutStatus": {
"name": "待出库",
"value": 0,
"description": "待出库"
},
"orderStatus": {
"name": "待发货",
"value": 1,
"description": "待发货"
},
"orderPayType": {
"name": "货到付款",
"value": 1,
"description": "货到付款"
},
"orderDeliveryWay": {
"name": "物流配送",
"value": 0,
"description": "物流配送"
},
"orderTradeType": {
"name": "即时到帐交易",
"value": 4,
"description": "即时到帐交易"
},
"stockOutType": {
"name": "销售出库",
"value": 0,
"description": "销售出库"
},
"creator": 9002257,
"reviser": 9002257,
"createTime": "2021-12-05 23:13:20",
"reviseTime": "2021-12-05 23:14:00",
"status": 0,
"storageId": 101888,
"no": "WD20211205836010001",
"sumProductPayment": 880.6,
"refundAmount": 0,
"buyerFeedback": "发新鲜货,尽快发货",
"buyerLevel": "",
"sellerId": "3e703f8e28c54d86b3e67fecc1dbff67",
"sellerName": "监狱公司-2416",
"toDivisionCode": "长安区",
"toTownCode": "",
"shopName": "监狱公司-2416",
"toAddress": "火车站",
"toFullAddress": "河北省石家庄市长安区火车站",
"payStatus": "未支付",
"orderPayWay": 0,
"valetPayStatus": 0,
"storageName": "初始仓库",
"stockOutCreateTime": "2021-12-05 23:13:21",
"stockOutToFullName": "张德天",
"stockOutToFullAddress": "河北省石家庄市长安区火车站",
"creatorName": "监狱账号联系人",
"stockOutTotalQuantity": 7,
"stockOutTotalAmount": 880.6,
"orderNo": "WD20211205836010001",
"stockOutOutNo": "2112058359100014846",
"stockOutNo": "CK2021120583602001"
}
],
"pageIndex": 0,
"pageSize": 50,
"total": 2,
"pageCount": 1,
"data": {
"addRepairOrder": True,
"cancelOrder": True
}
},
"message": "操作成功。",
"isSuccessed": True
}
# 匹配message值
# 常规匹配:
print(testdata["message"])# jsonpath匹配(取出来是个列表)
print(jsonpath.jsonpath(testdata, '$..message'))# 去列表
print(jsonpath.jsonpath(testdata, '$..message')[0])
# 匹配list值
print(jsonpath.jsonpath(testdata, '$..list')[0])
# 匹配stockOutId值
print(jsonpath.jsonpath(testdata, '$..stockOutId'))
# 匹配stockOutStatus值
print(jsonpath.jsonpath(testdata, '$..stockOutStatus'))
# 匹配data下所有的元素
print(jsonpath.jsonpath(testdata, '$.data.*'))
# 匹配data下list所有的orderId值
print(jsonpath.jsonpath(testdata, '$.data.list[*].orderId'))
print(jsonpath.jsonpath(testdata, '$..orderId'))
# 匹配data下list中倒数第一个orderId值
print(jsonpath.jsonpath(testdata, '$.data.list[*].orderId')[-1])
# 匹配data--list下所有的stockOutType值
print(jsonpath.jsonpath(testdata, '$.data..stockOutType'))
print(jsonpath.jsonpath(testdata, '$..stockOutType'))
# 匹配data--list下第二个stockOutType中的description值
print(jsonpath.jsonpath(testdata, '$.data..stockOutType.description')[1])
# 匹配data--list下所有orderTradeType中所有的name值
print(jsonpath.jsonpath(testdata, '$..orderTradeType.name'))
# 匹配data--list中包含OutOutNo的所有列表值,并返回stockOutOutNo值
print(jsonpath.jsonpath(testdata, '$..list[?(@.stockOutOutNo)].stockOutOutNo'))
# 匹配data--list下sumProductPayment>800的所有值,是把list中满足条件的值列出来
print(jsonpath.jsonpath(testdata, '$..list[?(@.sumProductPayment>800)]'))
# 匹配data--list下sumProductPayment>800的所有值,并取出sumProductPayment的值
print(jsonpath.jsonpath(testdata, '$..list[?(@.sumProductPayment>800)].sumProductPayment'))
# 匹配orderPayType的所有值
print(jsonpath.jsonpath(testdata, '$..orderPayType'))
# 匹配orderPayType中所有的valve值
print(jsonpath.jsonpath(testdata, '$..orderPayType.*'))
# 匹配orderPayType返回的多个结果中的第一个
print(jsonpath.jsonpath(testdata, '$..orderPayType')[0])
# 匹配orderPayType中的description值
print(jsonpath.jsonpath(testdata, '$..orderPayType.description'))# 更多玩法姿势我也还在探索中,各位路过的大佬有新玩法可以留言,学习下,不胜感激!

















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









