




在使用pandas时有很多赋值操作,并且出现了很多SettingWithCopyWarning警告。
首先先搞清楚视图和副本:
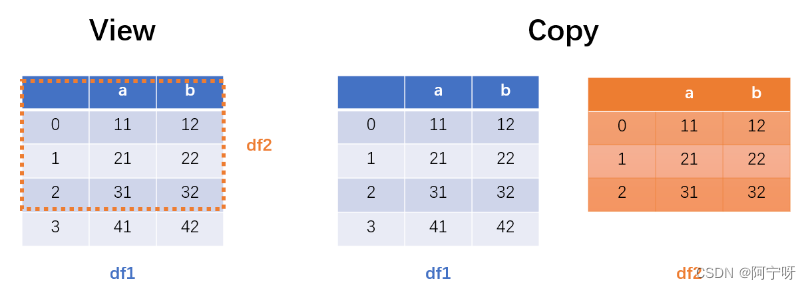
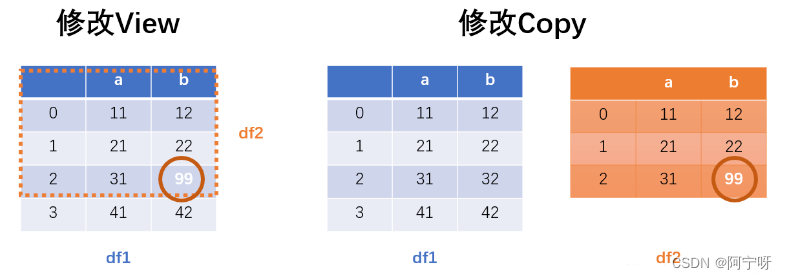
对于 df2 = df.head(3) 来说,df2 为视图,可以理解为截取 df1 的一部分来显示,实际上原数据都是指向 df1。当对视图 df2 进行修改时,会对原数据进行修改。
而对于 df2 = df.head(3).copy()来说,df2 为 df1 截取的一个副本,此处df1 和 df2是两个完全不同的 DataFrame,当对副本 df2 进行修改时,不会修改到 df1。即用 .copy() 实现了数据隔离。
第一种情况:如果不想在原df上进行修改,即对由原df得到的新df进行修改希望的同时不影响到原来df的数据,一般使用 .copy(),但是考虑数据量和性能,可以考虑使用 双loc即后面加.loc[:] 从原df获得新df,再对新df进行修改,并且同时不影响原df,实际上是隐式创建副本。
import pandas as pd
ids = [1, 2]
info = {
'C': 0.5}
df = pd.DataFrame({
'id': [1, 2, 3],
'A': [4, 5, 6],
'B': [7, 8, 9]
})
# 一、对于添加或修改df的列复现SettingWithCopyWarning
# 出现原因:操作DataFrame时,不小心创建了DataFrame的一个视图(view)而不是副本(copy)。这可能导致数据的修改未按预期生效。
# 一般使用 .loc 或 .iloc 进行明确的数据选择来避免
# 但是对于链式反应即使使用 .loc 或 .iloc 还是会出现SettingWithCopyWarning
exp_df = df.loc[df['id'].isin(ids)]
if not exp_df.empty:
exp_df.loc[:, 'C'] = info['C']
print(exp_df)
print('-------------')
print(df)
OUT:
id A B C
0 1 4 7 0.5
1 2 5 8 0.5
-------------
id A B
0 1 4 7
1 2 5 8
2 3 6 9
.../3558177221.py:14: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
exp_df.loc[:, 'C'] = info['C']
但是如果用.loc[:]
import pandas as pd
ids = [1, 2]
info = {
'C': 0.5}
df = pd. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1753
1753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









