







 本文通过实例详细介绍了Q-Learning的基本原理与实现步骤,包括Q-table的初始化与更新过程,并解释了Bellman方程在强化学习中的应用。
本文通过实例详细介绍了Q-Learning的基本原理与实现步骤,包括Q-table的初始化与更新过程,并解释了Bellman方程在强化学习中的应用。
本文转载,很经典:
Diving deeper into Reinforcement Learning with Q-Learning
1、Q-learning
Step 1: We init our
Q-table
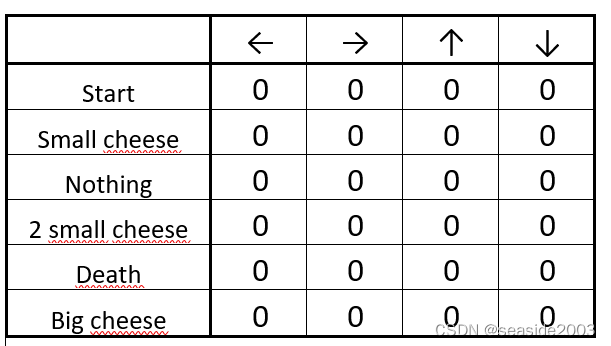
The initialized Q-table
Step 2: Choose an action
From the starting position, you can choose between going right or down. Because we have a big epsilon rate (since we don’t know anything about the environment yet), we choose randomly. For example… move right.

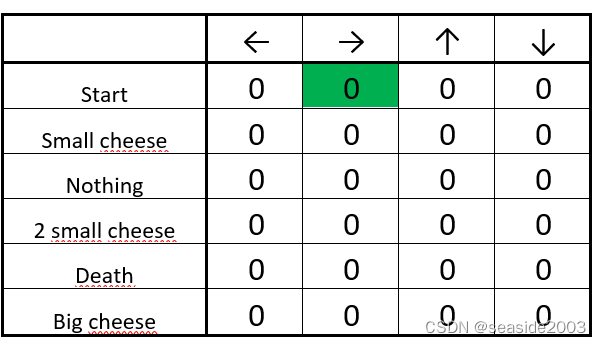
We move at random (for instance, right)
We found a piece of cheese (+1), and we can now update the Q-value of being at start and going right. We do this by using the Bellman equation.
Steps 4–5: Update the Q-function
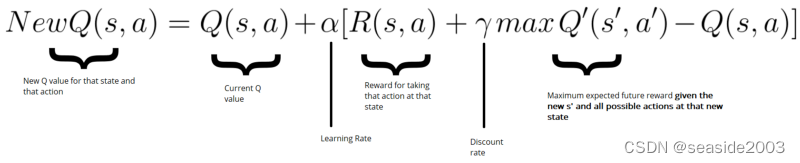

- First, we calculate the change in Q value ΔQ(start, right)
- Then we add the initial Q value to the ΔQ(start, right) multiplied by a learning rate.
Think of the learning rate as a way of how quickly a network abandons the former value for the new. If the learning rate is 1, the new estimate will be the new Q-value.
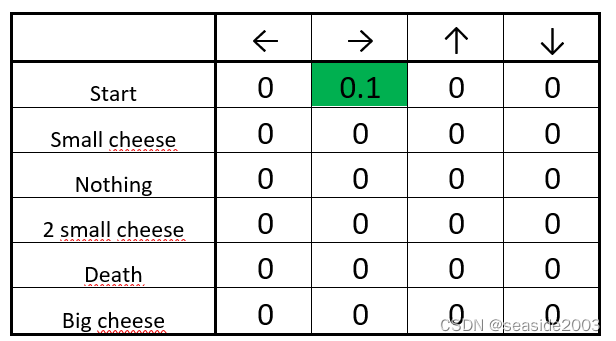
The updated Q-table
Good! We’ve just updated our first Q value. Now we need to do that again and again until the learning is stopped.
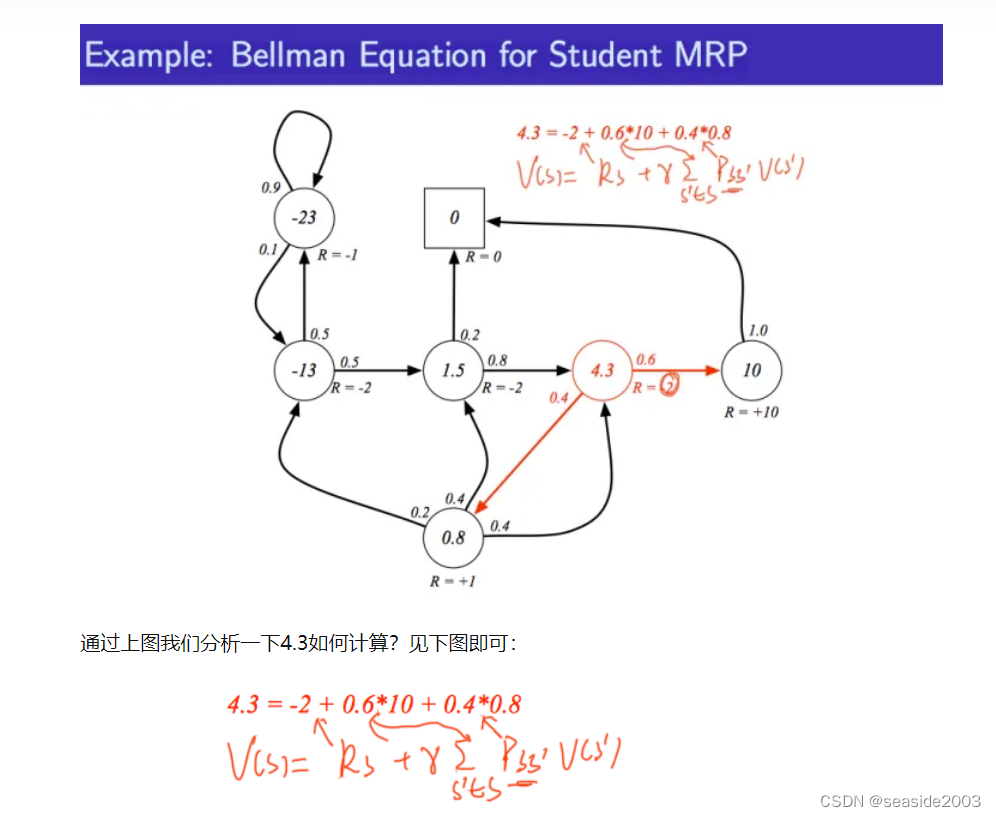
2、Bellman 方程的解释
马尔科夫决策过程之Bellman Equation(贝尔曼方程) - 知乎

















 1697
1697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









