




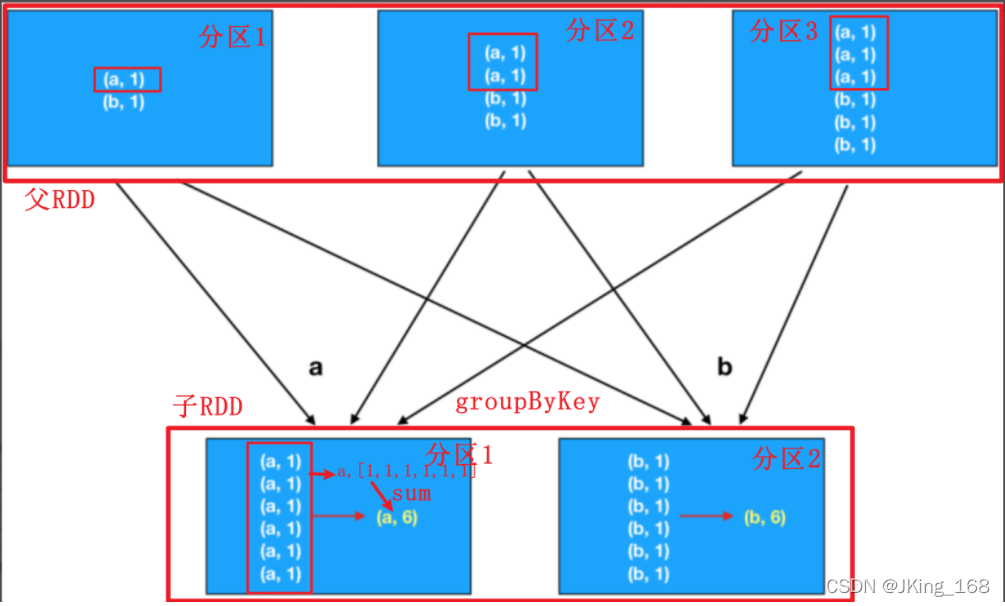
- groupByKey 的 shuffle 的数据量大,容易造成子RDD的分区的内存溢出。如果做 wordcount 词频统计,那么需要继续手动 mapValues 才能得到结果。
- reduceByKey 有 2 阶段的聚合,性能快。在父RDD分区内做了预聚合,在子RDD的分区内再次聚合。
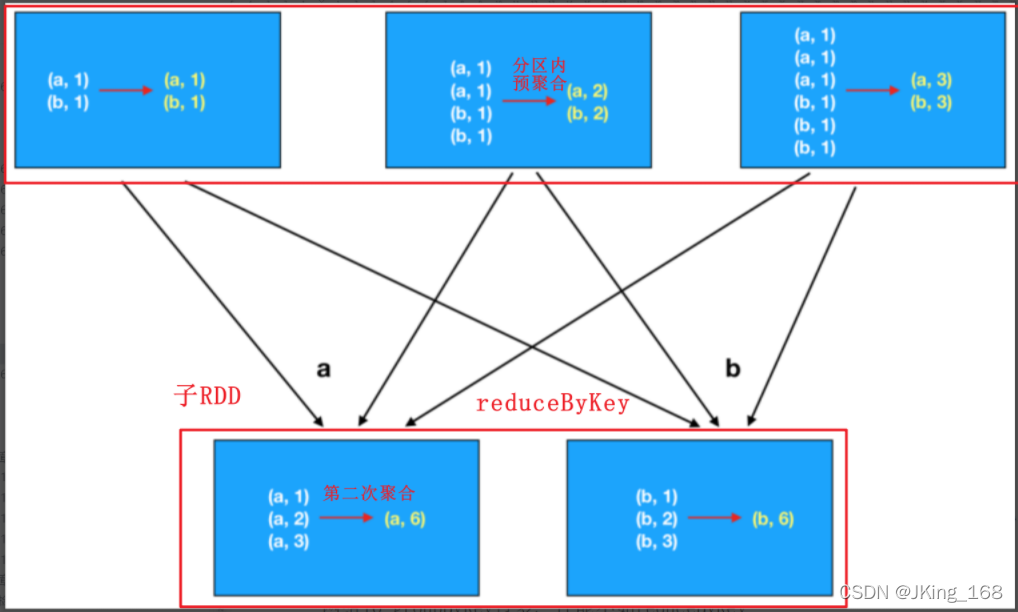
 博客讨论了在Apache Spark中,groupByKey和reduceByKey两种聚合操作的区别与性能影响。groupByKey可能导致大量数据shuffle,增加内存溢出风险,适合直接需要所有键值对的情况。而reduceByKey在父RDD内部先进行局部聚合,再在子RDD间聚合,减少数据传输,提高效率。对于词频统计等场景,需要先使用mapValues处理groupByKey的结果。
博客讨论了在Apache Spark中,groupByKey和reduceByKey两种聚合操作的区别与性能影响。groupByKey可能导致大量数据shuffle,增加内存溢出风险,适合直接需要所有键值对的情况。而reduceByKey在父RDD内部先进行局部聚合,再在子RDD间聚合,减少数据传输,提高效率。对于词频统计等场景,需要先使用mapValues处理groupByKey的结果。
 791
791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























