







 本文介绍了如何使用Python爬虫爬取BOSS直聘上关于产品经理岗位的信息,包括分析网站结构,获取城市主页的岗位ID,构造完整URL,爬取并解析岗位详情,以及将数据保存到CSV文件。通过城市编码和岗位编码规律,实现批量爬取和解析。
本文介绍了如何使用Python爬虫爬取BOSS直聘上关于产品经理岗位的信息,包括分析网站结构,获取城市主页的岗位ID,构造完整URL,爬取并解析岗位详情,以及将数据保存到CSV文件。通过城市编码和岗位编码规律,实现批量爬取和解析。
爬虫心得
爬虫步骤:
- html网页源代码获取
- 目标数据解析
- 数据保存
在写解析部分的代码时,为了避免频繁访问url,我们可以将HTML代码保存到txt文件,后面只需要对txt文件中的html代码进行解析,当解析成功后,我们就可以直接对url进行解析了。
with open(file_path, 'a', encoding='utf-8') as f:
f.write(data)
一、网站分析
本次实验目的是爬取BOSS直聘网上关于【产品经理】岗位的相关信息。
城市主页
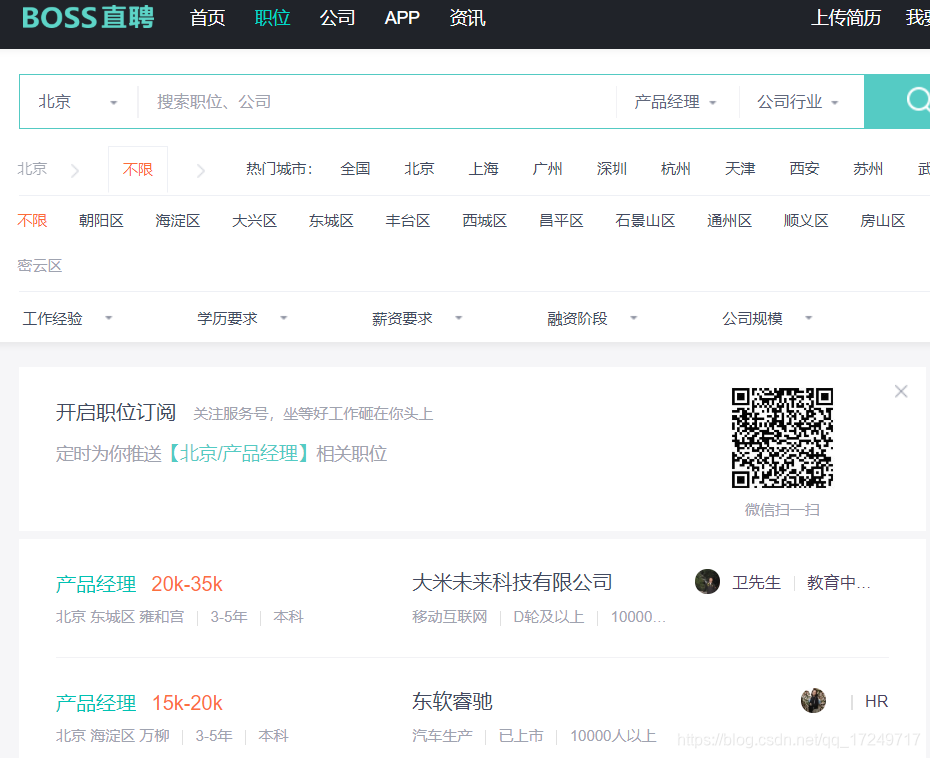
城市主页包括了该城市所有公司关于【产品经理】的招聘简要信息,如下图所示:
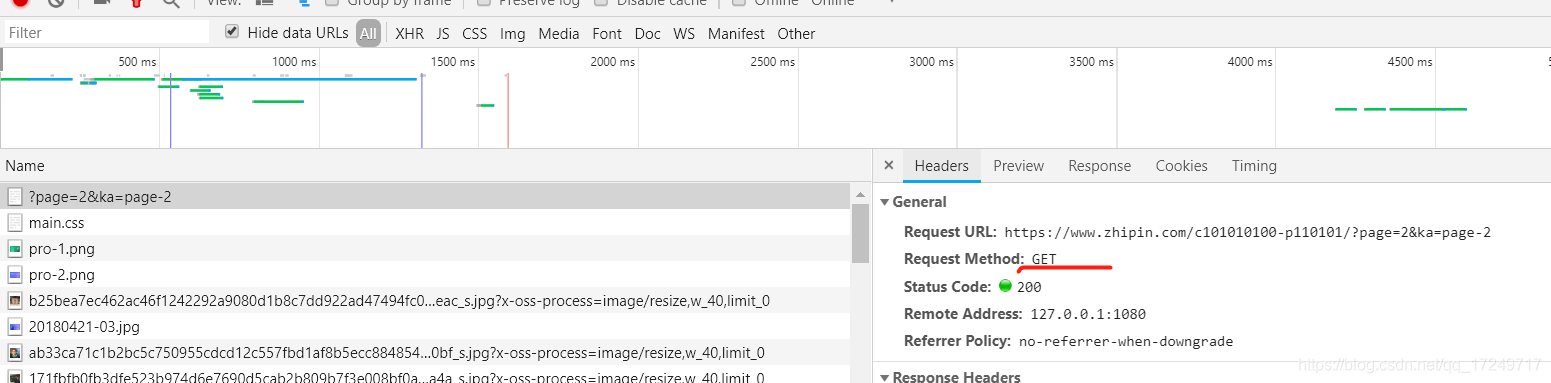
首先观察网页的headers信息,发现网站属于GET请求,参数为page和ka,示例图如下所示:
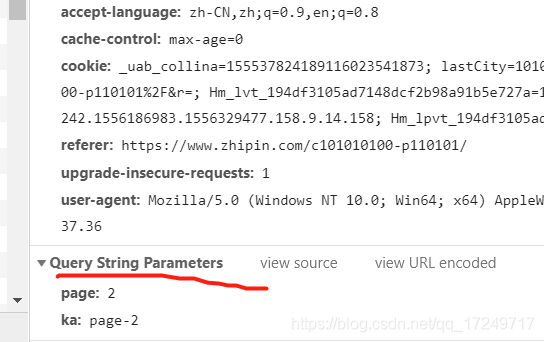
我们观察到该网站的URL链接为https://www.zhipin.com/c101010100-p110101/?page=2&ka=page-2,进一步分析该URL结构,剔除无关参数,最后发现URL的构成为https://www.zhipin.com/c城市编码-p岗位编码/?page=页数。
page最多有10页。
城市编码举例:
beijing: 101010100
shanghai: 101020100
macao: 101330100
岗位编码举例:
产品经理:110101
web前端:100901
岗位主页
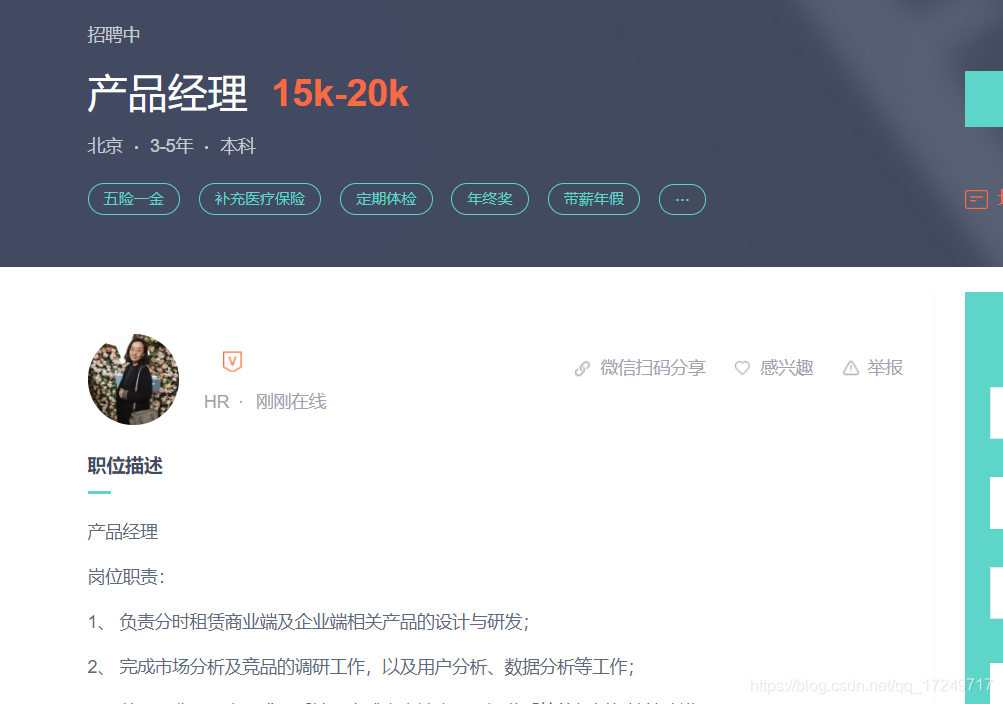
我们点进一个岗位,会有新的链接打开,这就是该公司的产品经理具体的招聘要求,如下图所示:
同样的方法,我们观察到该网站是GET请求,分析URL结构https://www.zhipin.com/job_detail/197253928b563bbd1XFz29q-EFs~.html?ka=search_list_2
,其中ka参数无关,一串代码197253928b563bbd1XFz29q-EFs可以把它看作是岗位的id是我们需要找到的,只要找到这部分的id,我们就可以构造所有岗位的URL。因此,具体岗位的URL链接为https://www.zhipin.com/job_detail/代码~.html。
二、获取城市主页关于岗位的id并构造完整url
这部分我们获取城市主页关于【产品经理】岗位的id,并构造完整url。
导入相关包
本实验采用pyquery和re模块对数据进行提取。
import requests
import re
import time
from pyquery import PyQuery as pq
import csv
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1398
1398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









