






目录
前言:
AVX指令函数查询——Intel® Intrinsics Guide
Linux系统判断自己电脑CPU是否支持AVX和AVX2,可以用lscpu命令查询
Windows系统可以用CPU-Z工具进行查询
cpp文件需要加上头文件#include <immintrin.h>,在编译时需要添加后缀-mavx -mavx2 以启用AVX指令集:
g++ a.cpp -mavx -mavx2 a内存对齐
前提知识:
1 Byte = 8bit
1 int8 占用 1 Byte
1 int16 占用 2 Byte
1 int32 占用 4 Byte
//定义一个结构体
struct node
{
int8 a;
int32 b;
}
//观察一下他在内存中的储存内存对齐时:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| a | b | b | b | b |
此计算机内存读取的颗粒度为4
读取a(0号内存):计算机读取0-3这组内存,去掉1-3号内存,访问次数1次
读取b(4-7号内存):计算机读取4-7号这组内存,访问次数1次
内存没有对齐时:
此计算机内存读取的颗粒度为4
读取a(0号内存):计算机读取0-3这组内存,去掉1-3号内存,访问次数1次
读取b(1-4号内存):计算机读取0-3号这组内存,去掉0号内存,再读取4-7号内存,去掉5-7号内存,访问次数2次
内存对齐的目的:合理的内存对齐可以高效的利用硬件性能,减少处理器内存访问次数。
AVX编程
1、数据类型
| 数据类型 | 描述 |
|---|---|
| __m128 | 包含4个float类型数字的向量 |
| __m128d | 包含2个double类型数字的向量 |
| __m128i | 包含若干个整型数字的向量 |
| __m256 | 包含8个float类型数字的向量 |
| __m256d | 包含4个double类型数字的向量 |
| __m256i | 包含若干个整型数字的向量 |
由于char、short、int、long均可以表示为整数,所以_m128i/_m256i不仅仅可以表示int类型的数据,也可以表示char、short、int、long这些数据类型
例如__m256i就可以由32个char,或者16个short,或者8个int,又或者4个long构成,这些整型可以是有符号类型也可以是无符号类型。
2、函数命名
_mm<bit_width>_<name>_<data_type>- <bit_width> 表示向量的长度,对于128位的向量,这个参数为空,对于256位的向量,这个参数为256。
- <name>描述函数操作
- <data_type>表明函数主参数的数据类型
data_type:
1、ps:向量包含单精度float s(ps 代表压缩单精度)
2、pd:向量包含双精度doule s(pd 代表压缩双精度)
3、epi8/epi16/epi32/epi64:向量里每个数都是整型,一个整型8bit/16bit/32bit/64bit
4、epu8/epu16/epu32/epu64:向量里每个数都是无符号整型(unsigned),一个整型8bit/16bit/32bit/64bit
5、m128/m128i/m128d/m256/m256i/m256d:输入值与返回类型不同时会出现 ,例如__m256i_mm256_setr_m128i(__m128ilo,__m128ihi),输入两个__m128i向量 ,把他们拼在一起,变成一个__m256i返回 。
6、si128/si256 - unspecified 128-bit vector or 256-bit vector
3、常用函数
(1)初始化函数
1、初始化为0:
| __m256d _mm256_setzero_pd (void) |
| __m256 _mm256_setzero_ps (void) |
| __m256i _mm256_setzero_si256 (void) |
2、用1个标量初始化:
| __m256i _mm256_set1_epi16 (short a) |
| __m256i _mm256_set1_epi32 (int a) |
| __m256i _mm256_set1_epi64x (long long a) |
| __m256i _mm256_set1_epi8 (char a) |
| __m256d _mm256_set1_pd (double a) |
| __m256 _mm256_set1_ps (float a) |
3、用多个标量初始化:
| __m256i _mm256_set_epi16 (short e15,...,short e0) |
| __m256i _mm256_set_epi32 (int e7,..., int e0) |
| __m256i _mm256_set_epi64x (__int64 e3, ..., __int64 e0) |
| __m256d _mm256_set_pd (double e3, ..., double e0) |
| __m256 _mm256_set_ps (float e7, ..., float e0) |
| __m256i _mm256_set_epi8 (char e31, ..., char e0) |
| __m256(d) _mm256_setr_ps/pd (.......) 用八个浮点(ps)或四个双精度(pd)按相反顺序初始化向量 |
| __m256i _mm256_setr_epi8/16/32/64 (......) |
4、用128bit向量初始化:
| __m256 _mm256_set_m128 (__m128 a, __m128 b) |
| __m256d _mm256_set_m128d (__m128d a, __m128d b) |
| __m256i _mm256_set_m128i (__m128i a, __m128i b) |
(2)数据读取:
1、对齐读取:
| __m256d _mm256_load_pd (double const * mem_addr) |
| __m256 _mm256_load_ps (float const * mem_addr) |
| __m256i _mm256_load_si256 (__m256i const * mem_addr) |
float* aligned_floats = (float*)aligned_alloc(32, 64 * sizeof(float)); //这里使用了内存对齐
... Initialize data ...
__m256 vec = _mm256_load_ps(aligned_floats);
2、未对齐读取:
| __m256d _mm256_loadu_pd (double const * mem_addr) |
| __m256 _mm256_loadu_ps (float const * mem_addr) |
| __m256i _mm256_loadu_si256 (__m256i const * mem_addr) |
float* unaligned_floats = (float*)malloc(64 * sizeof(float)); //未使用内存对齐
... Initialize data ...
__m256 vec = _mm256_loadu_ps(unaligned_floats);
假设你想用AVX向量处理一个浮点数组(float),但是数组的长度是11,不能被8(256÷8bit÷4byte)整除
| f | f | f | f | f | f | f | f | f | f | f |
在这种情况下,第二个__m256向量的最后五个浮点数需要设置为0[或者使用非向量计算手段],这样它们就不会影响计算。
| f | f | f | f | f | f | f | f | f | f | f | 0 | 0 | 0 | 0 | 0 |
这种选择性加载可以用下面的**_maskload_**函数来完成。
| __m256d _mm256_maskload_pd (double const*mem_addr , __m256d const* mask) |
| __m256 _mm256_maskload_ps (float const * mem_addr , __m256 constm* mask) |
| __m256i _mm256_maskload_epi32/64 (int const * mem_addr , __m256i const* mask) |
示例:
若mask对应的值≥0,则返回向量元素为0,若<0则返回array中对应元素的值
| int_array | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 |
|---|---|---|---|---|---|---|---|---|
| mask | -1 | -1 | -1 | -1 | -1 | 1 | 1 | 1 |
| result | 100 | 200 | 300 | 400 | 500 | 0 | 0 | 0 |
#include <immintrin.h>
#include <stdio.h>
int main() {
int i;
int int_array[8] = {100, 200, 300, 400, 500, 600, 700, 800};
/* Initialize the mask vector */
__m256i mask = _mm256_setr_epi32(-20, -72, -48, -9, -100, 3, 5, 8);
//可以像上述表格那样-1,-1,-1,-1,-1,1,1,1只要保证需要置零的位>=0就可以
/* Selectively load data into the vector */
__m256i result = _mm256_maskload_epi32(int_array, mask);
/* Display the elements of the result vector */
int* res = (int*)&result;
printf("%d %d %d %d %d %d %d %d\n",
res[0], res[1], res[2], res[3], res[4], res[5], res[6], res[7]);
return 0;
}
输出结果:100 200 300 400 500 0 0 0
【int型在计算机的存储是补码,正数的补码最高位为0,所以返回0,负数的补码最高位为1,所以返回的是内存中相应的元素】
(3)数据回写
对齐:
void _mm256_store_pd (double * mem_addr, __m256d a)
void _mm256_store_ps (float * mem_addr, __m256 a)
void _mm256_store_si256 (__m256i * mem_addr, __m256i a)未对齐:
void _mm256_storeu_pd (double * mem_addr, __m256d a)
void _mm256_storeu_ps (float * mem_addr, __m256 a)
void _mm256_storeu_si256 (__m256i * mem_addr, __m256i a)(4)算数运算
1、加法
__m256i _mm256_add_epi16 (__m256i a, __m256i b)
__m256i _mm256_add_epi32 (__m256i a, __m256i b)
__m256i _mm256_add_epi64 (__m256i a, __m256i b)
__m256i _mm256_add_epi8 (__m256i a, __m256i b)
__m256d _mm256_add_pd (__m256d a, __m256d b)
__m256 _mm256_add_ps (__m256 a, __m256 b)2、减法
__m256i _mm256_sub_epi16 (__m256i a, __m256i b)
__m256i _mm256_sub_epi32 (__m256i a, __m256i b)
__m256i _mm256_sub_epi64 (__m256i a, __m256i b)
__m256i _mm256_sub_epi8 (__m256i a, __m256i b)
__m256d _mm256_sub_pd (__m256d a, __m256d b)
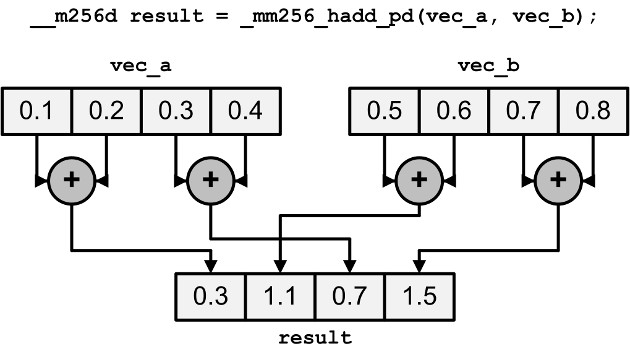
__m256 _mm256_sub_ps (__m256 a, __m256 b)3、水平加法
__m256i _mm256_hadd_epi16 (__m256i a, __m256i b)
__m256i _mm256_hadd_epi32 (__m256i a, __m256i b)
__m256d _mm256_hadd_pd (__m256d a, __m256d b)
__m256 _mm256_hadd_ps (__m256 a, __m256 b)
__m256i _mm256_madd_epi16 (__m256i a, __m256i b)4、水平减法
__m256i _mm256_hsub_epi16 (__m256i a, __m256i b)
__m256i _mm256_hsub_epi32 (__m256i a, __m256i b)
__m256d _mm256_hsub_pd (__m256d a, __m256d b)
__m256 _mm256_hsub_ps (__m256 a, __m256 b)
__m256i _mm256_hsubs_epi16 (__m256i a, __m256i b)水平加减法图示:
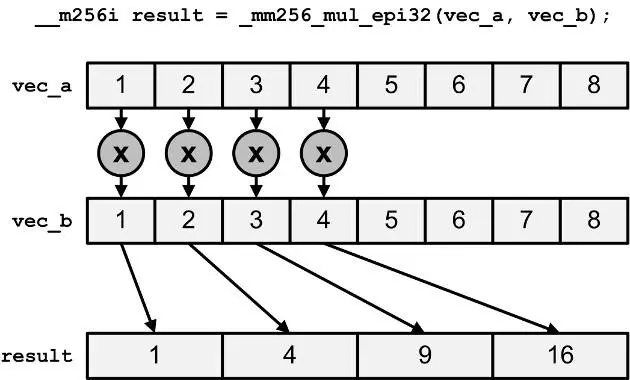
5、乘法
__m256i _mm256_mul_epi32 (__m256i a, __m256i b)
__m256i _mm256_mul_epu32 (__m256i a, __m256i b)
__m256d _mm256_mul_pd (__m256d a, __m256d b)
__m256 _mm256_mul_ps (__m256 a, __m256 b)mul对epi32的运算只针对最低的4个元素,得到的结果是64位整数
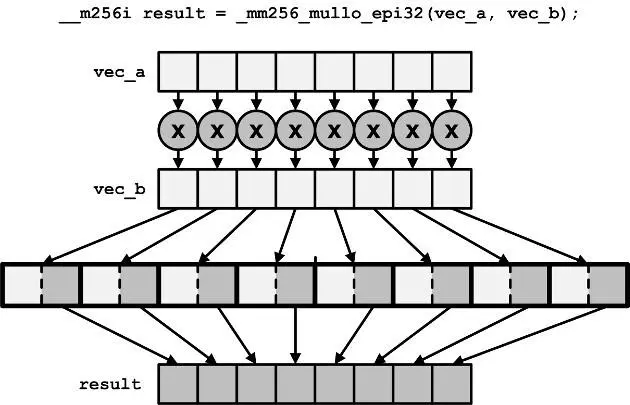
__m256i _mm256_mulhi_epi16 (__m256i a, __m256i b)
__m256i _mm256_mulhi_epu16 (__m256i a, __m256i b)
__m256i _mm256_mullo_epi16 (__m256i a, __m256i b)
__m256i _mm256_mullo_epi32 (__m256i a, __m256i b)mulhi、mullo的运算会针对所有元素,然后分别取运算结果的高/低位
6、除法
__m256d _mm256_div_pd (__m256d a, __m256d b)
__m256 _mm256_div_ps (__m256 a, __m256 b)只能进行浮点计算
7、更多
| madd | 乘加 |
| abs | 绝对值 |
| floor/ceil/round | 取整 |
| unpack | 间接读取 |
| insert | 插入元素 |
(5)数据类型转换
|
|

















 2324
2324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









