




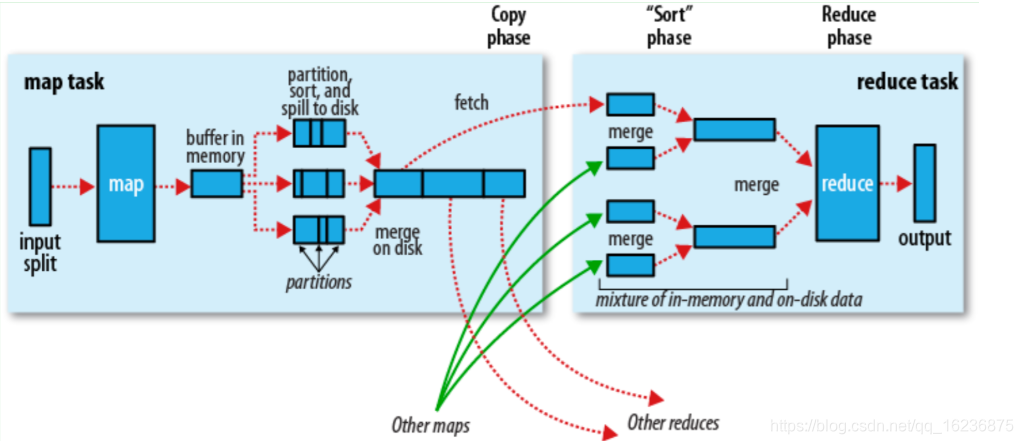
对Map的结果进行排序并传输到Reduce 进行处理,Map的结果并不是直接存放到硬盘,而是利用缓存做一些预排序处理Map 会调用Combiner ,压缩,按key 进行分区,排序等,尽量减少结果的大小,每个Map 完成后都会通知Task,然后Reduce 就可以进行排序。
Map 端
当Map 程序开始产生结果的时候,并不是直接写到文件的,而是·利用缓存做一些排序方面的预处理
每个Map 任务都有一个循环内存缓冲区(默认100MB),当缓存的内容达到80%时,后台线程开始将内容写到文件,此时Map 任务可以继续输出结果,但如果缓冲区满了,Map 任务则需要等待。
写文件使用round-robin 方式。在写入文件之前,先将数据按照Reduce进行区分,对于每一个分区,都会在内存中根据key 进行排序,如果配置了Combiner,则排序后执行Combiner(Combine 之后可以减少写入文件和传输的数据)
每次结果达到缓冲区的阈值时,都会创建一个文件,在Map 结束时,可能会产生大量的文件,在Map完成前,会将这些文件进行合并和排序,如果文件的数量超过3个,则合并后会再次运行Combiner(1,2 个文件就没有必要了)
如何配置了压缩,则最终写入的文件会先进行压缩,这样可以减少写入和传输的数据。
一旦Map 完成,则通知任务管理器,此时Reduce 就可以开始复制结果数据。
Reduce 端
Map 的结果文件都存放到运行Map 任务的机器的本地硬盘中
如果Mao的结果很少,则直接放到内存,否则写入文件中
同时后台程序将这些文件进行合并和排序到一个更大的文件中(如果文件是压缩的,则需要先解压)
当所有的Map结果都被复制和合并后,就会调用Reduce方法
Reduce 结果会写入到HDFS中
调优
一般的原则是给shuffle 分配尽可能多的内存,但前提是要保证Map,Reduce 任务有足够的内存。
对于Map,主要就是避免把文件写入磁盘,例如使用Combiner,增大io.sort.mb 的值
对于Reduce,主要是把Map的结果尽可能的保存到内存中,同样也是要避免把中间结果写入磁盘,默认情况下,所有内存都是分配给Reduce 方法的,如果Reduce方法不怎么消耗内存,可以mapred.inmem.merge.threshold 设置为0,mapred.job.reduce.input.buffer.percent 设成1.0
在任务监控中可以通过Spilled records counter 来监控写入磁盘的数,但这个值是包括map和reduce的。
对于IO方面,可以Map的结果可以使用压缩,同时增大buffer size。

















 1367
1367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









