1. 概述
- Map 方法之后,Reduce 方法之前的数据处理过程称之为 Shuffle。
2. Partition 分区
- 需求:要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照手机归属地,不同省份输出到不同文件中(分区)。
// 默认 Partitioner 分区
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
2.1 自定义 Partitioner 步骤
// 1. 自定义类继承 Partitioner, 重写 getPartition() 方法
public class CustomPartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
// 控制区代码逻辑
......
}
}
// 2. 在 Job 驱动中,设置自定义 Partitioner
job.setPartitionerClass(CustomPartitioner.class);
// 3. 自定义 Partition 后,要根据自定义 Partitioner 的逻辑设置相应数量的 ReduceTask
job.setNumReduceTasks(自定义的数量);
2.2 分区总结
- 如果 ReduceTask 的数量大于getPartition的结果数,则会多产生几个空的输出文件 part-r-000xx;
- 如果1<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会产生IOException;
- 如果ReduceTask的数量为1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件 part-r-00000;
- 分区号必须从零开始,逐一累加。
3. WritableComparable 排序
- MapTask 和 ReduceTask 均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
- 默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
3.1 排序概述
- MapTask:它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它回对磁盘上所有文件进行归并排序。
- ReduceTask:它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写到磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大的文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask 统一对内存和磁盘上的所有数据进行一次归并排序。
3.1 排序分类
- 部分排序
- MapReduce 根据输入记录的键对数据集排序。保证输出的每个文件内部有序。
- 全排序
- 最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
- 辅助排序(GroupingComparator 分组)
- 在Reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
- 二次排序
- 在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序。
3.2 Combiner 合并
- Combiner是MR程序中Mapper和Reducer之外的一种组件;
- Combiner组件的父类就是Reducer;
- Combiner和Reducer的区别在于运行的位置:
- Combiner是在每一个MapTask所在的节点运行;
- Reducer是接收全局所有Mapper的输出结果;
- Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减少网络传输量。
- Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出kv应该跟Reducer的输入kv类型要对应起来;
3.3 GroupingComparator 分组(辅助排序)
- 对Reduce阶段的数据根据某一个或几个字段进行分组。
// 分组排序步骤:
// 1. 自定义类继承 WritableComparator
// 2. 重写 compare()方法
// 3. 创建一个构造将比较对象的类传给父类
4. Shuffle 机制
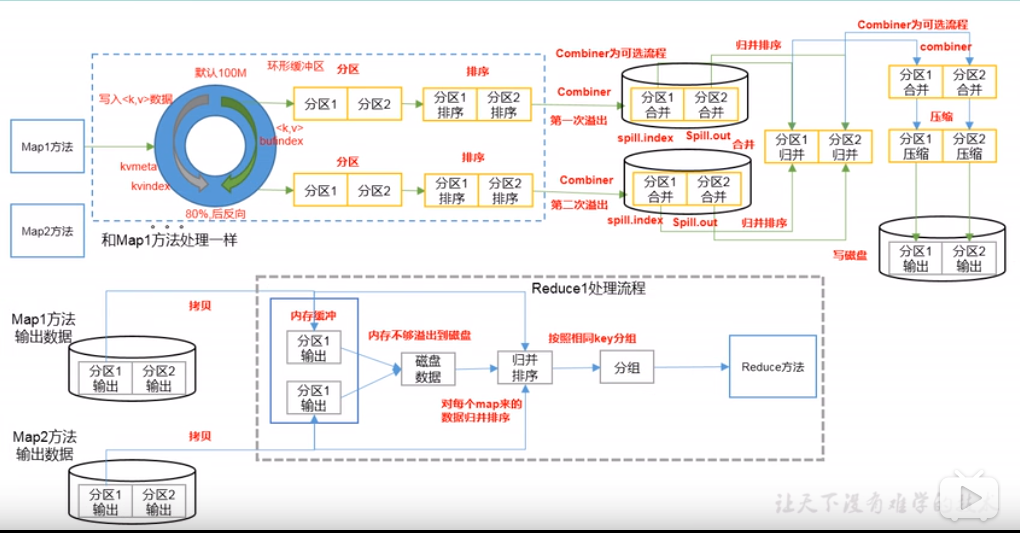







 本文围绕Hadoop中Map到Reduce间的Shuffle机制展开。介绍了Partition分区,包括自定义步骤和分区结果与ReduceTask数量的关系;阐述了WritableComparable排序,如排序概述、分类(部分排序、全排序等)、Combiner合并及GroupingComparator分组;还提及了Shuffle机制的相关内容。
本文围绕Hadoop中Map到Reduce间的Shuffle机制展开。介绍了Partition分区,包括自定义步骤和分区结果与ReduceTask数量的关系;阐述了WritableComparable排序,如排序概述、分类(部分排序、全排序等)、Combiner合并及GroupingComparator分组;还提及了Shuffle机制的相关内容。

















 2306
2306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









