







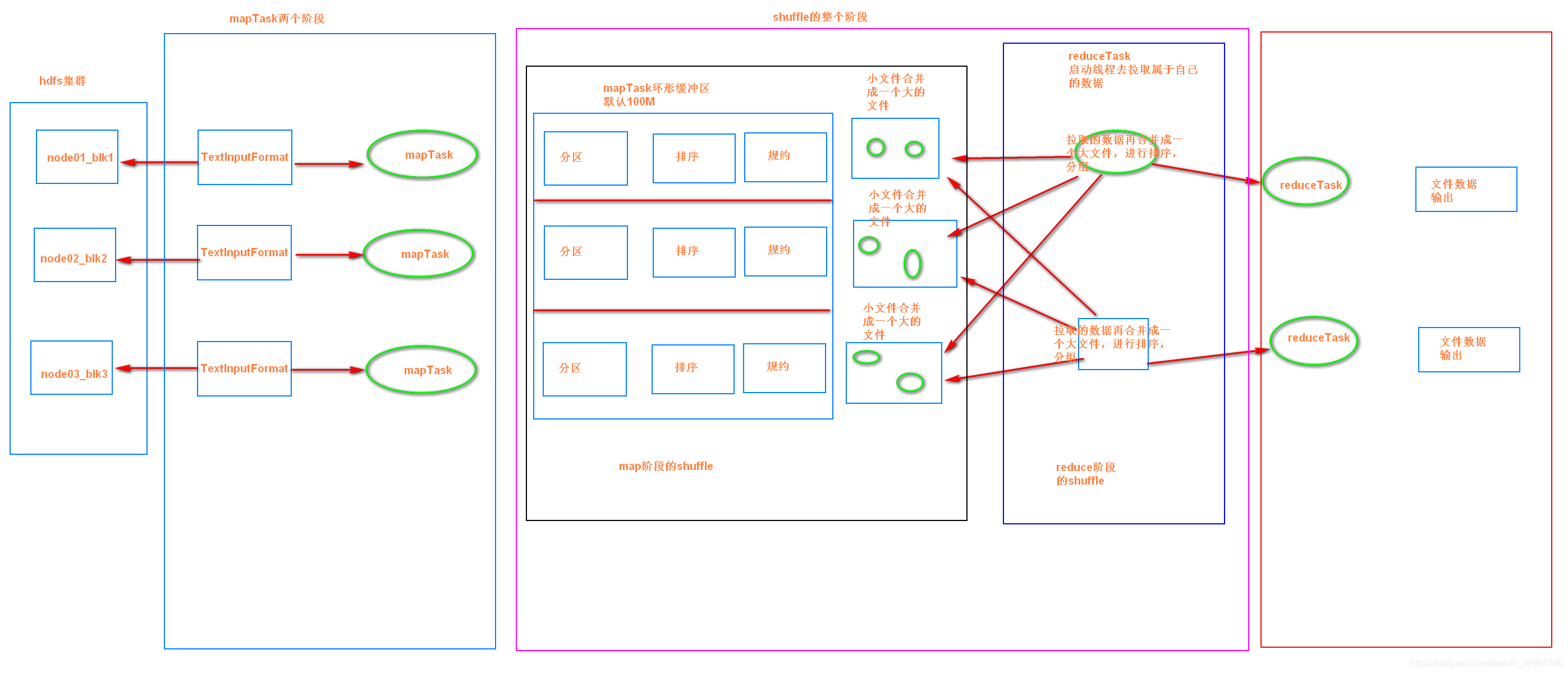
map端:
1、读取数据源
2、将数据切片(每片128M),切分成一个个的split
3、启动mapTask,mapTask个数和split个数一样,开始执行任务
4、mapTask将数据读入内存,存在一个内存环形缓冲区(mapreduce.task.io.sort.mb=100,可自定义);当该区域中的容量到达80%(默认mapreduce.map.sort.spill.percent=0.8,可自定义)的时候,启动一个线程,进行溢写操作,将数据持久化到磁盘。整个任务完成后,溢写的一个个小文件合并成一个临时大文件,等待reduceTask拉取。并且在此过程中,每一个mapTask的数据已经进行了分区(默认HashPartitioner)、排序、规约等操作。
reduce端:
1、每个reduceTask拉取mapTask端自己对应的的数据(reduceTask个数, 通过Job.setNumReduceTasks(int)设置)
2、将相同key的数据进行聚合,value形成一个集合
3、对形成数据进行排序和分组,然后调用reduce方法
4、输出

















 1381
1381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









