







 本文详细记录了从准备环境到成功编译Spark2.3.0源码的全过程,包括所需工具、IDEA配置、常见问题及解决方案,为初次尝试者提供实用指导。
本文详细记录了从准备环境到成功编译Spark2.3.0源码的全过程,包括所需工具、IDEA配置、常见问题及解决方案,为初次尝试者提供实用指导。
编译spark 2.3.0源码
最近编译了spark 2.3.0。现在做一下总结。
最开始以为这不需要多久时间很快就完成了,真正操作时候才发现有各种坑,完全在意料之外,有些坑让人没有头绪,找不到方向,浪费大把时间,我花了将近一天才解决这个问题。
首先需要准备以下东西:
- spark源码 2,.3.0 没有的话去官网下载
- maven 3.X
- scala 2.11
编译方法有很多,可以用maven,可以用sbt,可以用spark自带编译工具,也可以用git。
IDEA编译spark
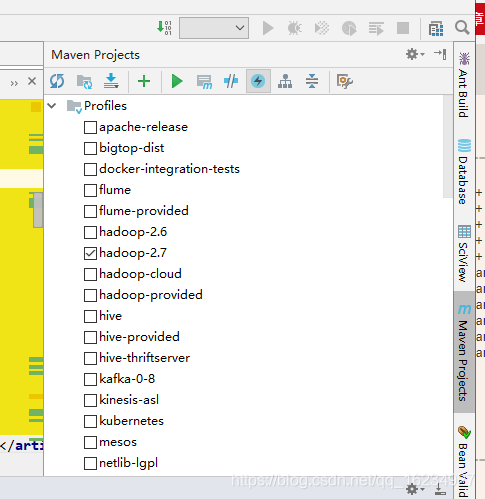
idea打开spark源码,在profile这里进行勾选,需要什么勾选什么,我们只需要勾选hadoop 2.7 ,scala 2.11,yarn即可。
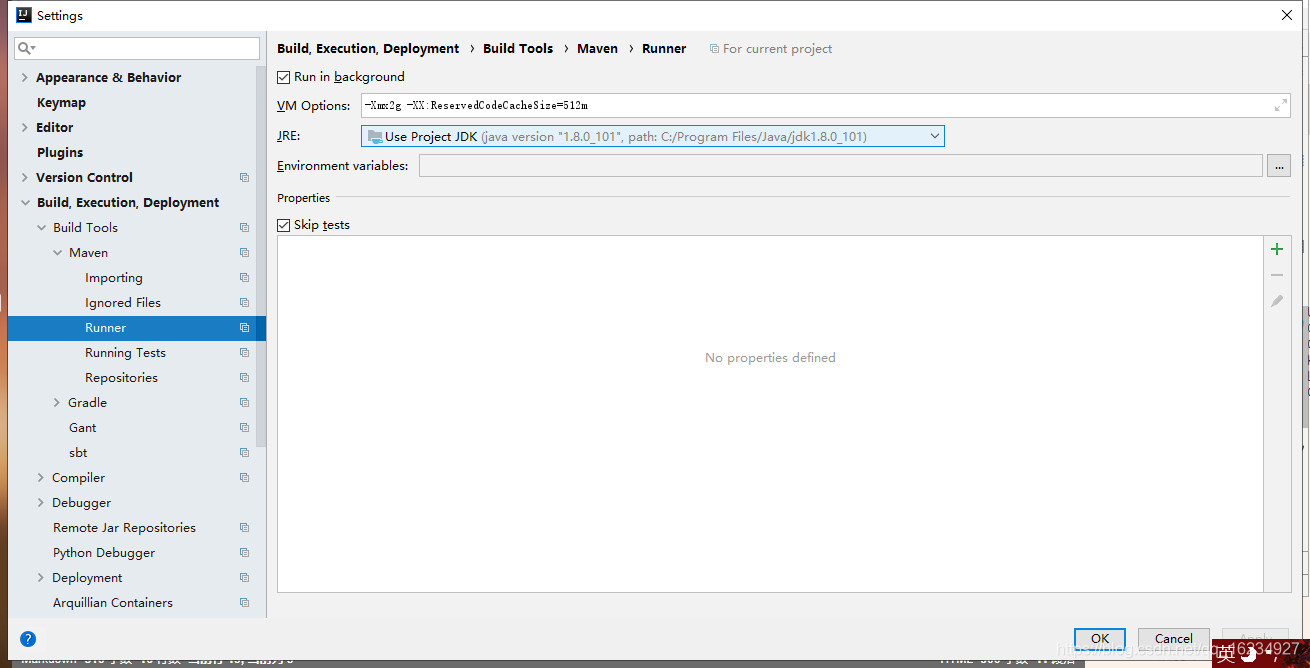
设置vm opthion,输入参数-Xmx2g -XX:ReservedCodeCacheSize=512m
然后点击build project
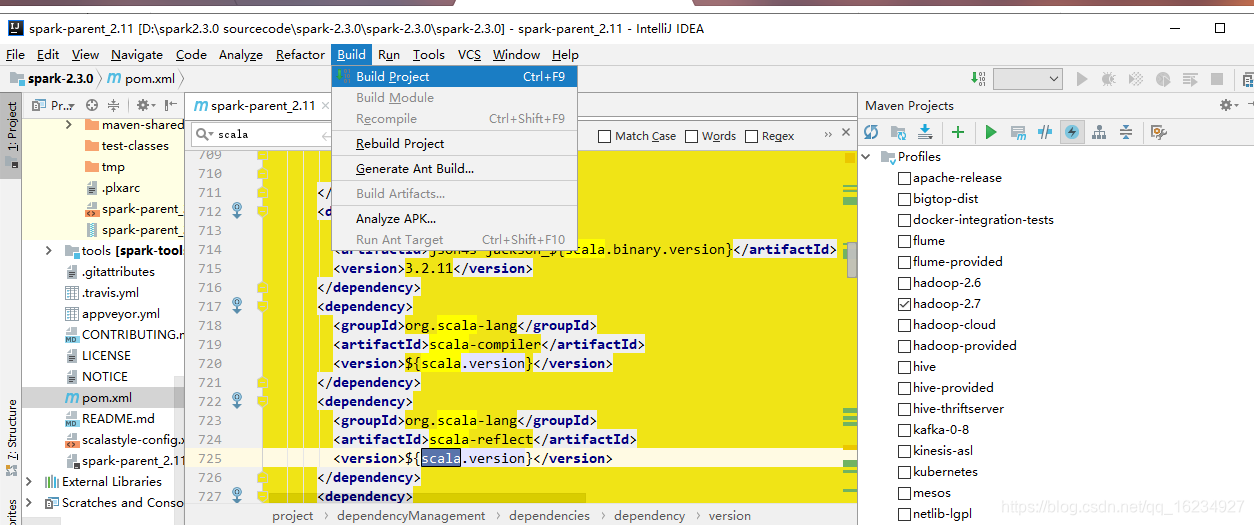 这里会提示一些信息,不用理会。
这里会提示一些信息,不用理会。
之后就开始编译源码了,点击clean+package,并且点击跳过测试这个按钮
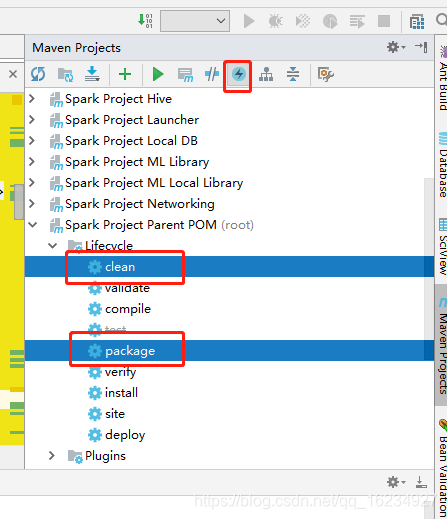 然后就慢慢等待,估计半小时左右,慢的话2小时也是有可能的。
然后就慢慢等待,估计半小时左右,慢的话2小时也是有可能的。
遇到的bug
源码导进来pom文件就报错,添加两行代码就可以了
<session.executionRootDirectory>executionRootDirectory</session.executionRootDirectory>
<test_classpath>test_classpath</test_classpath>
添加地方如图所示

build project 时候报错
这是因为依赖包没有加载完毕,点击这个按钮就可以了
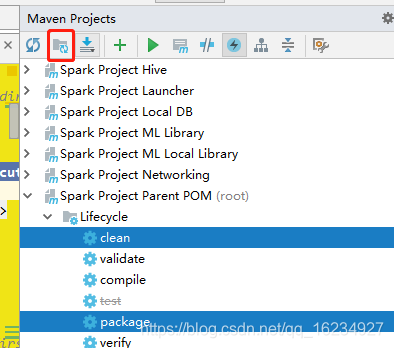
打包时候报错
提示Cannot run program “bash” (in directory “D:\spark\spark-2.3.3\core”): CreateProcess error=2, 系统找不到指定的文件。
这是因为没有配置git环境变量,配置完环境变量后重启IDEA。重新打包就可以了。
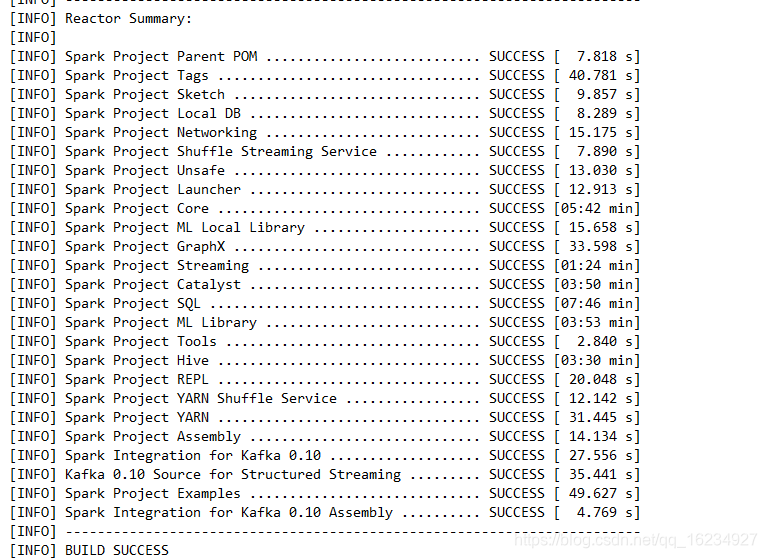
好了,大功告成。

















 3589
3589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









