







DQN改进
DQN算法存在过估计问题,可以采用Double DQN方法来进行补偿。两种方法只在下图不同,其他地方一致。下图公式为 q_target 的输出值,
DQN:
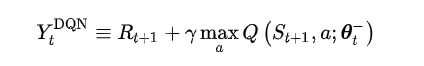
Double DQN:
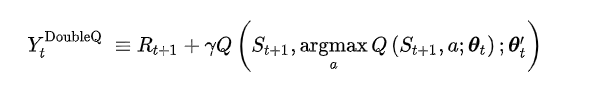
Policy Gradient
Policy gradient是基于策略的强化学习,该方法是存储每一轮的s,a,r值,用以计算梯度。

这里面, π θ \pi_{\theta} πθ表示选择对应动作的概率,后面的 v t v_{t} vt表示对应的时刻 t t t的 r r r加上未来衰减的 r r r。一个基于policy gradient的pytorch程序如下:
import torch
import gym
import torch.nn as nn
import torch.nn 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









