








 本文深入探讨了混淆矩阵在预测模型评估中的作用,解释了其如何帮助我们理解模型的分类性能,特别是在识别不同类别间易混淆的情况。通过具体实例,展示了如何利用混淆矩阵指导模型优化方向。
本文深入探讨了混淆矩阵在预测模型评估中的作用,解释了其如何帮助我们理解模型的分类性能,特别是在识别不同类别间易混淆的情况。通过具体实例,展示了如何利用混淆矩阵指导模型优化方向。
在预测模型生成结果之后,我们需要对得到的结果进行评估,进而修正预测模型,这时需要用到混淆矩阵(confusion matrix),也称为错误矩阵(error matrix)。之所以叫做‘混淆矩阵’,是因为能够直观的到有没有将样本的类别给混淆了。混淆矩阵是评判模型结果的指标,属于模型评估的一部分。
矩阵的每一行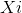 代表样本所属的真实类别,矩阵的每一列
代表样本所属的真实类别,矩阵的每一列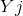 则表达了分类器对于样本的类别预测,而每个格子中的数值大小代表将类预测为类的样本个数。
则表达了分类器对于样本的类别预测,而每个格子中的数值大小代表将类预测为类的样本个数。
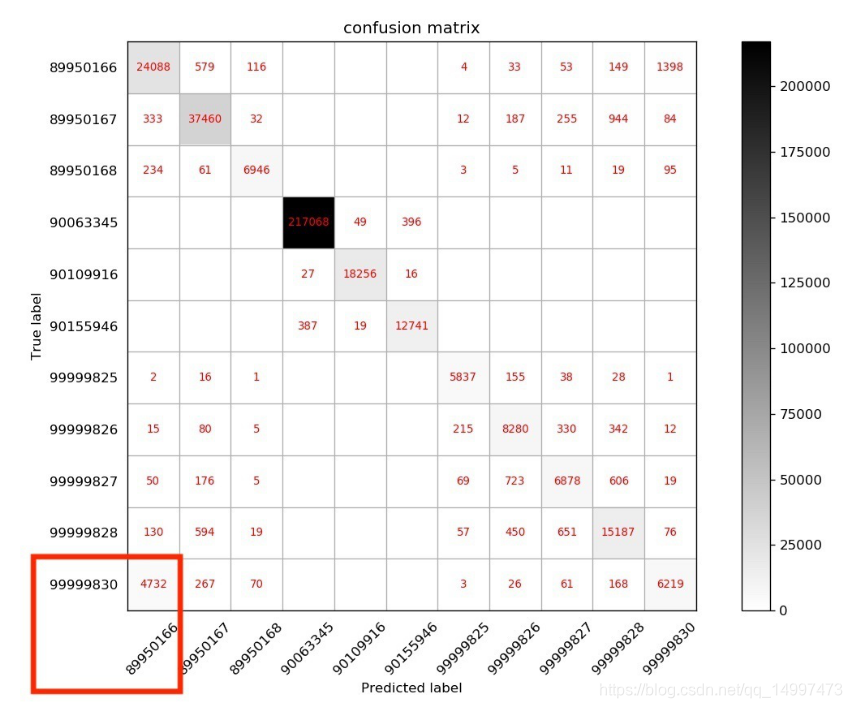
如下图所示是一个混淆矩阵,通过观察可以看到在预测的结果中,830类与166类容易出现混淆,于是可以对预测模型进行修正,训练一个二分类模型来提升830/166两类的预测精度。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









