







实战学习第二课
1.偏度,峰值 skew_dummies(BaseEstimator, TransformerMixin)
https://blog.youkuaiyun.com/qq_14815661/article/details/93378840
2.数据挖掘竞赛利器-Stacking和Blending方式
https://blog.youkuaiyun.com/maqunfi/article/details/82220115
stacing
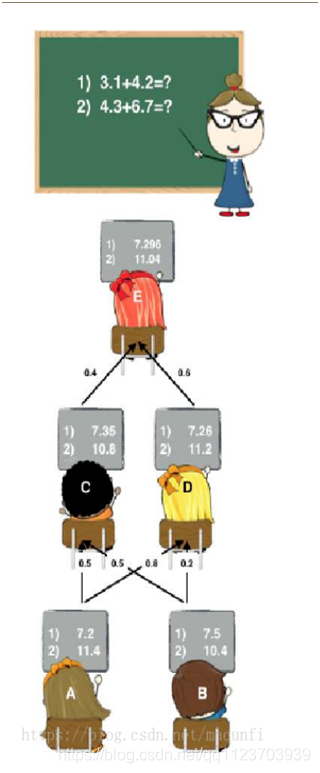
A、B是学习器,C、D、E是进行答案再组织的次学习器(加权平均值)
1.首先将所有数据集生成训练集 的5折交叉验证(8000作训练集,2000作校正集)和 测试集为2500
2. 可以得到52000条验证集的结果(相当于每条数据的预测结果),52500条测试集的预测结果。
3. 预测结果拼接成10000行长的矩阵,标记为A1。而对于5*2500行的测试集的预测结果进行加权平均,得到一个2500一列的矩阵,标记为B1。
4.对3个基模型进行集成的话,相于得到了A1、A2、A3、B1、B2、B3六个矩阵。
5.A1、A2、A3并列在一起成10000行3列的矩阵作为training data,B1、B2、B3合并在一起成2500行3列的矩阵作为testing data,让下层学习器基于这样的数据进行再训练
6.再训练是基于每个基础模型的预测结果作为特征(三个特征),次学习器会学习训练如果往这样的基学习的预测结果上赋予权重w,来使得最后的预测最为准确。。。。最终得到最后答案回到算数题从最下面的A,B一直到最上面的答案


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









