






本专栏知识点是通过零声教育的线上课学习,进行梳理总结写下文章,对c/c++linux课程感兴趣的读者,可以点击链接https://xxetb.xetslk.com/s/12PH1r C/C++后台高级服务器课程介绍 详细查看课程的服务
dpdk中实现的协程
#include <vppinfra/clib.h>
#include <vppinfra/longjmp.h>
#include <vppinfra/format.h>
static void test_calljmp (unformat_input_t * input);
static int i;
static int verbose;
#define if_verbose(format,args...) \
if (verbose) { clib_warning(format, ## args); }
static never_inline void
f2 (clib_longjmp_t * env)
{
i++;
clib_longjmp (env, 1);
}
static never_inline void
f1 (clib_longjmp_t * env)
{
i++;
f2 (env);
}
int
test_longjmp_main (unformat_input_t * input)
{
clib_longjmp_t env;
i = 0;
if (clib_setjmp (&env, 0) == 0)
{
if_verbose ("calling long jumper %d", i);
f1 (&env);
}
if_verbose ("back from long jump %d", i);
test_calljmp (input);
return 0;
}
static uword
f3 (uword arg)
{
uword i, j, array[10];
for (i = 0; i < ARRAY_LEN (array); i++)
array[i] = arg + i;
j = 0;
for (i = 0; i < ARRAY_LEN (array); i++)
j ^= array[i];
return j;
}
static void
test_calljmp (unformat_input_t * input)
{
static u8 stack[32 * 1024] __attribute__ ((aligned (16)));
uword v;
v = clib_calljmp (f3, 0, stack + sizeof (stack));
ASSERT (v == f3 (0));
if_verbose ("calljump ok");
}
#ifdef CLIB_UNIX
int
main (int argc, char *argv[])
{
unformat_input_t i;
int res;
verbose = (argc > 1);
unformat_init_command_line (&i, argv);
res = test_longjmp_main (&i);
unformat_free (&i);
return res;
}
#endif
VPP运行时协程的实现
vlib_unix_main
vlib_unix_main函数中调用了clib_calljmp实现了协程,clib_calljmp函数会调用thread0做为入口函数:
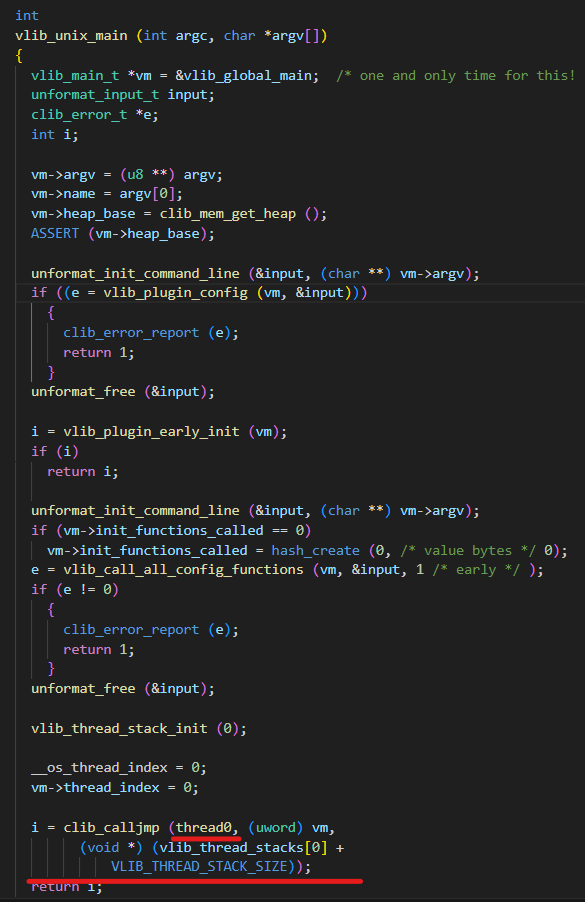
clib_calljmp在开启thread0的同时也向thread0这个线程传入了栈:
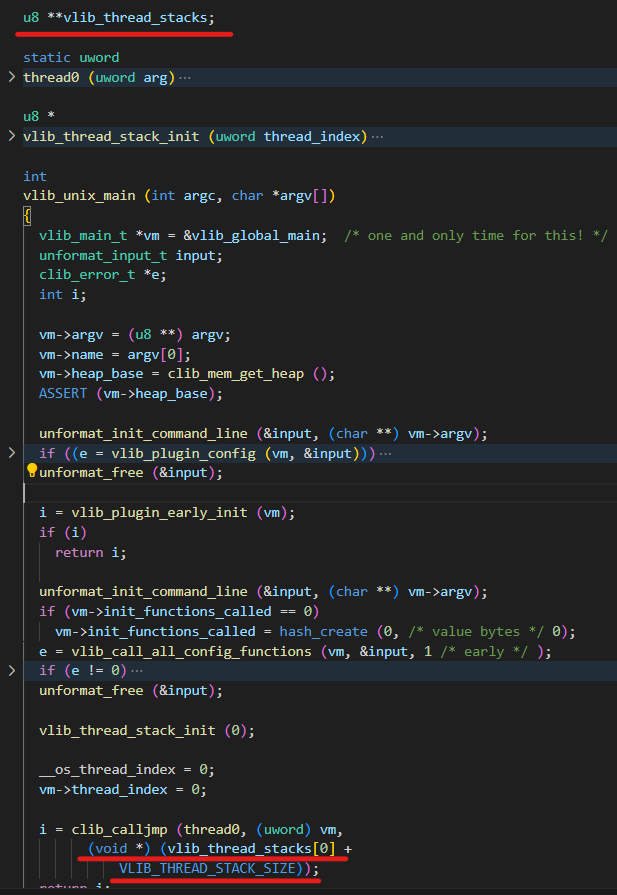
协程函数thread0
在协程函数thread0中调用了vlib_main:
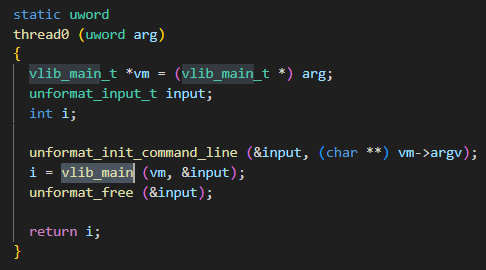
在vlib_main中就会调用vlib_main_loop,这时候整个进程就会阻塞在这个循环中
/* Main function. */
int
vlib_main (vlib_main_t * volatile vm, unformat_input_t * input)
{
clib_error_t *volatile error;
vlib_node_main_t *nm = &vm->node_main;
vm->queue_signal_callback = dummy_queue_signal_callback;
clib_time_init (&vm->clib_time);
/* Turn on event log. */
if (!vm->elog_main.event_ring_size)
vm->elog_main.event_ring_size = 128 << 10;
elog_init (&vm->elog_main, vm->elog_main.event_ring_size);
elog_enable_disable (&vm->elog_main, 1);
/* Default name. */
if (!vm->name)
vm->name = "VLIB";
if ((error = unix_physmem_init (vm)))
{
clib_error_report (error);
goto done;
}
if ((error = vlib_buffer_main_init (vm)))
{
clib_error_report (error);
goto done;
}
if ((error = vlib_thread_init (vm)))
{
clib_error_report (error);
goto done;
}
/* Register static nodes so that init functions may use them. */
vlib_register_all_static_nodes (vm);
/* Set seed for random number generator.
Allow user to specify seed to make random sequence deterministic. */
if (!unformat (input, "seed %wd", &vm->random_seed))
vm->random_seed = clib_cpu_time_now ();
clib_random_buffer_init (&vm->random_buffer, vm->random_seed);
/* Initialize node graph. */
if ((error = vlib_node_main_init (vm)))
{
/* Arrange for graph hook up error to not be fatal when debugging. */
if (CLIB_DEBUG > 0)
clib_error_report (error);
else
goto done;
}
/* See unix/main.c; most likely already set up */
if (vm->init_functions_called == 0)
vm->init_functions_called = hash_create (0, /* value bytes */ 0);
if ((error = vlib_call_all_init_functions (vm)))
goto done;
/* Create default buffer free list. */
vlib_buffer_get_or_create_free_list (vm,
VLIB_BUFFER_DEFAULT_FREE_LIST_BYTES,
"default");
nm->timing_wheel = clib_mem_alloc_aligned (sizeof (TWT (tw_timer_wheel)),
CLIB_CACHE_LINE_BYTES);
vec_validate (nm->data_from_advancing_timing_wheel, 10);
_vec_len (nm->data_from_advancing_timing_wheel) = 0;
/* Create the process timing wheel */
TW (tw_timer_wheel_init) ((TWT (tw_timer_wheel) *) nm->timing_wheel,
0 /* no callback */ ,
10e-6 /* timer period 10us */ ,
~0 /* max expirations per call */ );
vec_validate (vm->pending_rpc_requests, 0);
_vec_len (vm->pending_rpc_requests) = 0;
switch (clib_setjmp (&vm->main_loop_exit, VLIB_MAIN_LOOP_EXIT_NONE))
{
case VLIB_MAIN_LOOP_EXIT_NONE:
vm->main_loop_exit_set = 1;
break;
case VLIB_MAIN_LOOP_EXIT_CLI:
goto done;
default:
error = vm->main_loop_error;
goto done;
}
if ((error = vlib_call_all_config_functions (vm, input, 0 /* is_early */ )))
goto done;
/* Call all main loop enter functions. */
{
clib_error_t *sub_error;
sub_error = vlib_call_all_main_loop_enter_functions (vm);
if (sub_error)
clib_error_report (sub_error);
}
vlib_main_loop (vm);
done:
/* Call all exit functions. */
{
clib_error_t *sub_error;
sub_error = vlib_call_all_main_loop_exit_functions (vm);
if (sub_error)
clib_error_report (sub_error);
}
if (error)
clib_error_report (error);
return 0;
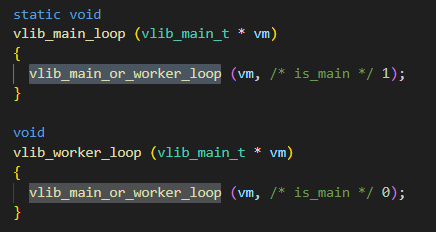
}vlib_main_loop循环
vlib_main_loop里面就是整个vpp的运行时的数据处理流程
static_always_inline void
vlib_main_or_worker_loop (vlib_main_t * vm, int is_main)
{
vlib_node_main_t *nm = &vm->node_main;
vlib_thread_main_t *tm = vlib_get_thread_main ();
uword i;
u64 cpu_time_now;
vlib_frame_queue_main_t *fqm;
u32 *last_node_runtime_indices = 0;
/* Initialize pending node vector. */
if (is_main)
{
vec_resize (nm->pending_frames, 32);
_vec_len (nm->pending_frames) = 0;
}
/* Mark time of main loop start. */
if (is_main)
{
cpu_time_now = vm->clib_time.last_cpu_time;
vm->cpu_time_main_loop_start = cpu_time_now;
}
else
cpu_time_now = clib_cpu_time_now ();
/* Pre-allocate interupt runtime indices and lock. */
vec_alloc (nm->pending_interrupt_node_runtime_indices, 32);
vec_alloc (last_node_runtime_indices, 32);
if (!is_main)
clib_spinlock_init (&nm->pending_interrupt_lock);
/* Pre-allocate expired nodes. */
if (!nm->polling_threshold_vector_length)
nm->polling_threshold_vector_length = 10;
if (!nm->interrupt_threshold_vector_length)
nm->interrupt_threshold_vector_length = 5;
/* Start all processes. */
if (is_main)
{
uword i;
nm->current_process_index = ~0;
for (i = 0; i < vec_len (nm->processes); i++)
cpu_time_now = dispatch_process (vm, nm->processes[i], /* frame */ 0,
cpu_time_now);
}
while (1)
{
vlib_node_runtime_t *n;
if (PREDICT_FALSE (_vec_len (vm->pending_rpc_requests) > 0))
vl_api_send_pending_rpc_requests (vm);
if (!is_main)
{
vlib_worker_thread_barrier_check ();
vec_foreach (fqm, tm->frame_queue_mains)
vlib_frame_queue_dequeue (vm, fqm);
}
/* Process pre-input nodes. */
if (is_main)
vec_foreach (n, nm->nodes_by_type[VLIB_NODE_TYPE_PRE_INPUT])
cpu_time_now = dispatch_node (vm, n,
VLIB_NODE_TYPE_PRE_INPUT,
VLIB_NODE_STATE_POLLING,
/* frame */ 0,
cpu_time_now);
/* Next process input nodes. */
vec_foreach (n, nm->nodes_by_type[VLIB_NODE_TYPE_INPUT])
cpu_time_now = dispatch_node (vm, n,
VLIB_NODE_TYPE_INPUT,
VLIB_NODE_STATE_POLLING,
/* frame */ 0,
cpu_time_now);
if (PREDICT_TRUE (is_main && vm->queue_signal_pending == 0))
vm->queue_signal_callback (vm);
/* Next handle interrupts. */
{
uword l = _vec_len (nm->pending_interrupt_node_runtime_indices);
uword i;
if (l > 0)
{
u32 *tmp;
if (!is_main)
clib_spinlock_lock (&nm->pending_interrupt_lock);
tmp = nm->pending_interrupt_node_runtime_indices;
nm->pending_interrupt_node_runtime_indices =
last_node_runtime_indices;
last_node_runtime_indices = tmp;
_vec_len (last_node_runtime_indices) = 0;
if (!is_main)
clib_spinlock_unlock (&nm->pending_interrupt_lock);
for (i = 0; i < l; i++)
{
n = vec_elt_at_index (nm->nodes_by_type[VLIB_NODE_TYPE_INPUT],
last_node_runtime_indices[i]);
cpu_time_now =
dispatch_node (vm, n, VLIB_NODE_TYPE_INPUT,
VLIB_NODE_STATE_INTERRUPT,
/* frame */ 0,
cpu_time_now);
}
}
}
if (is_main)
{
/* Check if process nodes have expired from timing wheel. */
ASSERT (nm->data_from_advancing_timing_wheel != 0);
nm->data_from_advancing_timing_wheel =
TW (tw_timer_expire_timers_vec)
((TWT (tw_timer_wheel) *) nm->timing_wheel, vlib_time_now (vm),
nm->data_from_advancing_timing_wheel);
ASSERT (nm->data_from_advancing_timing_wheel != 0);
if (PREDICT_FALSE
(_vec_len (nm->data_from_advancing_timing_wheel) > 0))
{
uword i;
processes_timing_wheel_data:
for (i = 0; i < _vec_len (nm->data_from_advancing_timing_wheel);
i++)
{
u32 d = nm->data_from_advancing_timing_wheel[i];
u32 di = vlib_timing_wheel_data_get_index (d);
if (vlib_timing_wheel_data_is_timed_event (d))
{
vlib_signal_timed_event_data_t *te =
pool_elt_at_index (nm->signal_timed_event_data_pool,
di);
vlib_node_t *n =
vlib_get_node (vm, te->process_node_index);
vlib_process_t *p =
vec_elt (nm->processes, n->runtime_index);
void *data;
//
data =
vlib_process_signal_event_helper (nm, n, p,
te->event_type_index,
te->n_data_elts,
te->n_data_elt_bytes);
if (te->n_data_bytes < sizeof (te->inline_event_data))
clib_memcpy (data, te->inline_event_data,
te->n_data_bytes);
else
{
clib_memcpy (data, te->event_data_as_vector,
te->n_data_bytes);
vec_free (te->event_data_as_vector);
}
pool_put (nm->signal_timed_event_data_pool, te);
}
else
{
cpu_time_now = clib_cpu_time_now ();
cpu_time_now =
dispatch_suspended_process (vm, di, cpu_time_now);
}
}
_vec_len (nm->data_from_advancing_timing_wheel) = 0;
}
}
/* Input nodes may have added work to the pending vector.
Process pending vector until there is nothing left.
All pending vectors will be processed from input -> output. */
for (i = 0; i < _vec_len (nm->pending_frames); i++)
cpu_time_now = dispatch_pending_node (vm, i, cpu_time_now);
/* Reset pending vector for next iteration. */
_vec_len (nm->pending_frames) = 0;
/* Pending internal nodes may resume processes. */
if (is_main && _vec_len (nm->data_from_advancing_timing_wheel) > 0)
goto processes_timing_wheel_data;
vlib_increment_main_loop_counter (vm);
/* Record time stamp in case there are no enabled nodes and above
calls do not update time stamp. */
cpu_time_now = clib_cpu_time_now ();
}
}vlib_main_loop中就调用了dispatch_process函数
dispatch_process
static u64
dispatch_process (vlib_main_t * vm,
vlib_process_t * p, vlib_frame_t * f, u64 last_time_stamp)
{
vlib_node_main_t *nm = &vm->node_main;
vlib_node_runtime_t *node_runtime = &p->node_runtime;
vlib_node_t *node = vlib_get_node (vm, node_runtime->node_index);//获取node
u64 t;
uword n_vectors, is_suspend;
if (node->state != VLIB_NODE_STATE_POLLING
|| (p->flags & (VLIB_PROCESS_IS_SUSPENDED_WAITING_FOR_CLOCK
| VLIB_PROCESS_IS_SUSPENDED_WAITING_FOR_EVENT)))
return last_time_stamp;
p->flags |= VLIB_PROCESS_IS_RUNNING;
t = last_time_stamp;
vlib_elog_main_loop_event (vm, node_runtime->node_index, t,
f ? f->n_vectors : 0, /* is_after */ 0);
/* Save away current process for suspend. */
nm->current_process_index = node->runtime_index;
n_vectors = vlib_process_startup (vm, p, f);
nm->current_process_index = ~0;
ASSERT (n_vectors != VLIB_PROCESS_RETURN_LONGJMP_RETURN);
is_suspend = n_vectors == VLIB_PROCESS_RETURN_LONGJMP_SUSPEND;
if (is_suspend)
{
vlib_pending_frame_t *pf;
n_vectors = 0;
pool_get (nm->suspended_process_frames, pf);
pf->node_runtime_index = node->runtime_index;
pf->frame_index = f ? vlib_frame_index (vm, f) : ~0;
pf->next_frame_index = ~0;
p->n_suspends += 1;
p->suspended_process_frame_index = pf - nm->suspended_process_frames;
if (p->flags & VLIB_PROCESS_IS_SUSPENDED_WAITING_FOR_CLOCK)
{
TWT (tw_timer_wheel) * tw =
(TWT (tw_timer_wheel) *) nm->timing_wheel;
p->stop_timer_handle =
TW (tw_timer_start) (tw,
vlib_timing_wheel_data_set_suspended_process
(node->runtime_index) /* [sic] pool idex */ ,
0 /* timer_id */ ,
p->resume_clock_interval);
}
}
else
p->flags &= ~VLIB_PROCESS_IS_RUNNING;
t = clib_cpu_time_now ();
vlib_elog_main_loop_event (vm, node_runtime->node_index, t, is_suspend,
/* is_after */ 1);
vlib_process_update_stats (vm, p,
/* n_calls */ !is_suspend,
/* n_vectors */ n_vectors,
/* n_clocks */ t - last_time_stamp);
return t;
}dispatch_process通过vlib_get_node获取到了一个node,随后调用了vlib_process_startup函数去启动这个获取到的node
vlib_process_startup
/* Called in main stack. */
static_always_inline uword
vlib_process_startup (vlib_main_t * vm, vlib_process_t * p, vlib_frame_t * f)
{
vlib_process_bootstrap_args_t a;
uword r;
a.vm = vm;
a.process = p;
a.frame = f;
//vlib_process_bootstrap函数的返回值再跳到clib_setjmp(&p->return_longjmp..)中;
//随后又去判断clib_setjmp的返回值r
//自定义的node就是通过clib_setjmp函数启动一个新的协程去处理node中的数据
r = clib_setjmp (&p->return_longjmp, VLIB_PROCESS_RETURN_LONGJMP_RETURN);
if (r == VLIB_PROCESS_RETURN_LONGJMP_RETURN)//设置长跳转
r = clib_calljmp (vlib_process_bootstrap, pointer_to_uword (&a),
(void *) p->stack + (1 << p->log2_n_stack_bytes));
return r;
}在vlib_process_startup函数中调用了clib_setjmp以及clib_calljmp函数。随后clib_calljmp就会进入到vlib_process_bootstrap这个函数
vlib_process_bootstrap
vlib_process_bootstrap中就会去执行注册node中的function函数
/* Called in process stack. */
static uword
vlib_process_bootstrap (uword _a)
{
vlib_process_bootstrap_args_t *a;
vlib_main_t *vm;
vlib_node_runtime_t *node;
vlib_frame_t *f;
vlib_process_t *p;
uword n;
a = uword_to_pointer (_a, vlib_process_bootstrap_args_t *);
vm = a->vm;
p = a->process;
f = a->frame;
node = &p->node_runtime;
n = node->function (vm, node, f);//执行注册node中的function函数
ASSERT (vlib_process_stack_is_valid (p));
clib_longjmp (&p->return_longjmp, n);
return n;//这里的n返回的就是我们下一个需要处理的node
}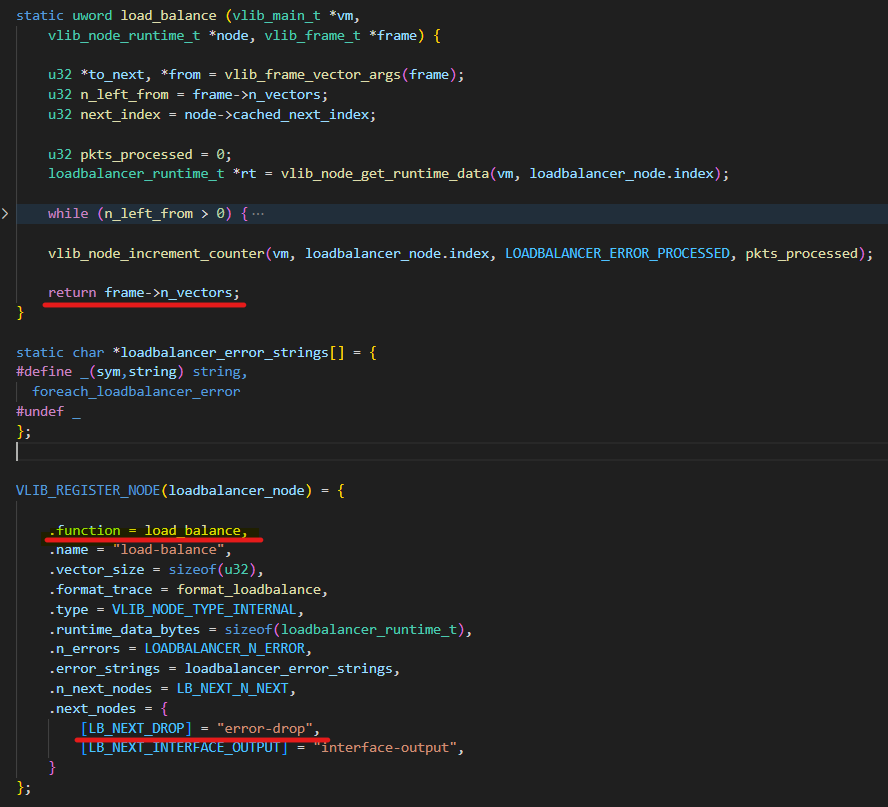
如上图所示,如果load_balance函数返回的frame->n_vectors的值为0,那么下一个需要执行的node为error-drop;如果load_balance函数返回的frame->n_vectors的值为1,那么下一个需要执行的node为interface-output。
运行时的node
node的四种类型
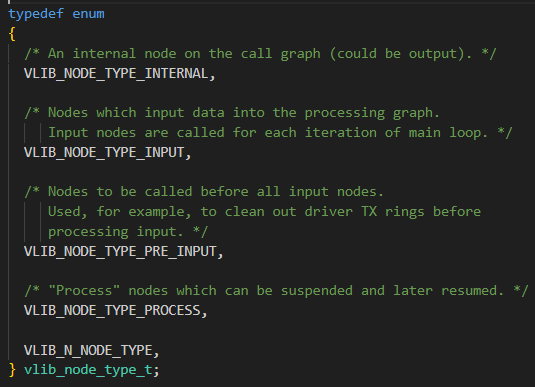
VLIB_NODE_TYPE_PRE_INPUT类型
VLIB_NODE_TYPE_PRE_INPUT在vpp中的应用:
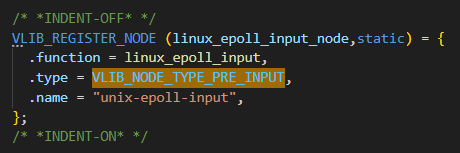
linux_epoll_input这个function的实现
static uword
linux_epoll_input (vlib_main_t * vm,
vlib_node_runtime_t * node, vlib_frame_t * frame)
{
unix_main_t *um = &unix_main;
clib_file_main_t *fm = &file_main;
linux_epoll_main_t *em = &linux_epoll_main;
struct epoll_event *e;
int n_fds_ready;
{
vlib_node_main_t *nm = &vm->node_main;
u32 ticks_until_expiration;
f64 timeout;
int timeout_ms = 0, max_timeout_ms = 10;
f64 vector_rate = vlib_last_vectors_per_main_loop (vm);
/* If we're not working very hard, decide how long to sleep */
if (vector_rate < 2 && vm->api_queue_nonempty == 0
&& nm->input_node_counts_by_state[VLIB_NODE_STATE_POLLING] == 0)
{
ticks_until_expiration = TW (tw_timer_first_expires_in_ticks)
((TWT (tw_timer_wheel) *) nm->timing_wheel);
/* Nothing on the fast wheel, sleep 10ms */
if (ticks_until_expiration == TW_SLOTS_PER_RING)
{
timeout = 10e-3;
timeout_ms = max_timeout_ms;
}
else
{
timeout = (f64) ticks_until_expiration *1e-5;
if (timeout < 1e-3)
timeout_ms = 0;
else
{
timeout_ms = timeout * 1e3;
/* Must be between 1 and 10 ms. */
timeout_ms = clib_max (1, timeout_ms);
timeout_ms = clib_min (max_timeout_ms, timeout_ms);
}
}
node->input_main_loops_per_call = 0;
}
else /* busy */
{
/* Don't come back for a respectable number of dispatch cycles */
node->input_main_loops_per_call = 1024;
}
/* Allow any signal to wakeup our sleep. */
{
static sigset_t unblock_all_signals;
n_fds_ready = epoll_pwait (em->epoll_fd,
em->epoll_events,
vec_len (em->epoll_events),
timeout_ms, &unblock_all_signals);
/* This kludge is necessary to run over absurdly old kernels */
if (n_fds_ready < 0 && errno == ENOSYS)
{
n_fds_ready = epoll_wait (em->epoll_fd,
em->epoll_events,
vec_len (em->epoll_events), timeout_ms);
}
}
}
if (n_fds_ready < 0)
{
if (unix_error_is_fatal (errno))
vlib_panic_with_error (vm, clib_error_return_unix (0, "epoll_wait"));
/* non fatal error (e.g. EINTR). */
return 0;
}
em->epoll_waits += 1;
em->epoll_files_ready += n_fds_ready;
for (e = em->epoll_events; e < em->epoll_events + n_fds_ready; e++)
{
u32 i = e->data.u32;
clib_file_t *f = pool_elt_at_index (fm->file_pool, i);
clib_error_t *errors[4];
int n_errors = 0;
if (PREDICT_TRUE (!(e->events & EPOLLERR)))
{
if (e->events & EPOLLIN)
{
errors[n_errors] = f->read_function (f);
n_errors += errors[n_errors] != 0;
}
if (e->events & EPOLLOUT)
{
errors[n_errors] = f->write_function (f);
n_errors += errors[n_errors] != 0;
}
}
else
{
if (f->error_function)
{
errors[n_errors] = f->error_function (f);
n_errors += errors[n_errors] != 0;
}
else
close (f->file_descriptor);
}
ASSERT (n_errors < ARRAY_LEN (errors));
for (i = 0; i < n_errors; i++)
{
unix_save_error (um, errors[i]);
}
}
return 0;
}VLIB_NODE_TYPE_INPUT类型
这种类型node的作用主要是用来初始化网络数据抓取这一层的。以dpdk为例:
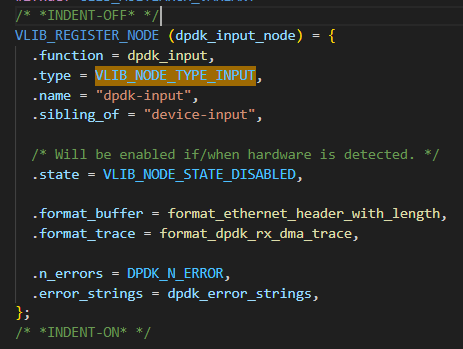
uword
CLIB_MULTIARCH_FN (dpdk_input) (vlib_main_t * vm, vlib_node_runtime_t * node,
vlib_frame_t * f)
{
dpdk_main_t *dm = &dpdk_main;
dpdk_device_t *xd;
uword n_rx_packets = 0;
vnet_device_input_runtime_t *rt = (void *) node->runtime_data;
vnet_device_and_queue_t *dq;
u32 thread_index = node->thread_index;
/*
* Poll all devices on this cpu for input/interrupts.
*/
/* *INDENT-OFF* 这里是对dpdk多队列中每一个端口进行数据的抓取*/
foreach_device_and_queue (dq, rt->devices_and_queues)
{
xd = vec_elt_at_index(dm->devices, dq->dev_instance);
if (PREDICT_FALSE (xd->flags & DPDK_DEVICE_FLAG_BOND_SLAVE))
continue; /* Do not poll slave to a bonded interface */
if (xd->flags & DPDK_DEVICE_FLAG_MAYBE_MULTISEG)
n_rx_packets += dpdk_device_input (dm, xd, node, thread_index, dq->queue_id, /* maybe_multiseg */ 1);
else
n_rx_packets += dpdk_device_input (dm, xd, node, thread_index, dq->queue_id, /* maybe_multiseg */ 0);
}
/* *INDENT-ON* */
poll_rate_limit (dm);
return n_rx_packets;
}在dpdk_device_input函数中就实现了对网卡数据的抓取以及处理操作:
static inline u32
dpdk_rx_burst (dpdk_main_t * dm, dpdk_device_t * xd, u16 queue_id)
{
u32 n_buffers;
u32 n_left;
u32 n_this_chunk;
n_left = VLIB_FRAME_SIZE;
n_buffers = 0;
if (PREDICT_TRUE (xd->flags & DPDK_DEVICE_FLAG_PMD))
{
while (n_left)
{
n_this_chunk = rte_eth_rx_burst (xd->device_index, queue_id,
xd->rx_vectors[queue_id] +
n_buffers, n_left);
n_buffers += n_this_chunk;
n_left -= n_this_chunk;
/* Empirically, DPDK r1.8 produces vectors w/ 32 or fewer elts */
if (n_this_chunk < 32)
break;
}
}
else
{
ASSERT (0);
}
return n_buffers;
}
/*
* This function is used when there are no worker threads.
* The main thread performs IO and forwards the packets.
*/
static_always_inline u32
dpdk_device_input (dpdk_main_t * dm, dpdk_device_t * xd,
vlib_node_runtime_t * node, u32 thread_index, u16 queue_id,
int maybe_multiseg)
{
u32 n_buffers;
u32 next_index = VNET_DEVICE_INPUT_NEXT_ETHERNET_INPUT;
u32 n_left_to_next, *to_next;
u32 mb_index;
vlib_main_t *vm = vlib_get_main ();
uword n_rx_bytes = 0;
u32 n_trace, trace_cnt __attribute__ ((unused));
vlib_buffer_free_list_t *fl;
vlib_buffer_t *bt = vec_elt_at_index (dm->buffer_templates, thread_index);
if ((xd->flags & DPDK_DEVICE_FLAG_ADMIN_UP) == 0)
return 0;
//dpdk_rx_burst函数中就调用了rte_eth_rx_burst函数
//获取到的数据被保存在了xd中
n_buffers = dpdk_rx_burst (dm, xd, queue_id);
if (n_buffers == 0)
{
return 0;
}
vec_reset_length (xd->d_trace_buffers[thread_index]);
trace_cnt = n_trace = vlib_get_trace_count (vm, node);
if (n_trace > 0)
{
u32 n = clib_min (n_trace, n_buffers);
mb_index = 0;
while (n--)
{
//获取到从dpdk网卡多队列中获取到的数据
struct rte_mbuf *mb = xd->rx_vectors[queue_id][mb_index++];
//将mbuf转换称为vlib_buffer
//#define rte_mbuf_from_vlib_buffer(x) (((struct rte_mbuf *)x) - 1)
//#define vlib_buffer_from_rte_mbuf(x) ((vlib_buffer_t *)(x+1))
//数据包格式:rte_mbuf + vlib buffer
vlib_buffer_t *b = vlib_buffer_from_rte_mbuf (mb);
//将接收到的数据存入vec中
vec_add1 (xd->d_trace_buffers[thread_index],
vlib_get_buffer_index (vm, b));
}
}
fl = vlib_buffer_get_free_list (vm, VLIB_BUFFER_DEFAULT_FREE_LIST_INDEX);
/* Update buffer template */
vnet_buffer (bt)->sw_if_index[VLIB_RX] = xd->vlib_sw_if_index;
bt->error = node->errors[DPDK_ERROR_NONE];
/* as DPDK is allocating empty buffers from mempool provided before interface
start for each queue, it is safe to store this in the template */
bt->buffer_pool_index = xd->buffer_pool_for_queue[queue_id];
mb_index = 0;
while (n_buffers > 0)
{
vlib_buffer_t *b0, *b1, *b2, *b3;
u32 bi0, next0;
u32 bi1, next1;
u32 bi2, next2;
u32 bi3, next3;
u8 error0, error1, error2, error3;
i16 offset0, offset1, offset2, offset3;
u64 or_ol_flags;
//对网卡数据包的处理操作,一次性就会处理4个数据包
vlib_get_next_frame (vm, node, next_index, to_next, n_left_to_next);
while (n_buffers >= 12 && n_left_to_next >= 4)
{
struct rte_mbuf *mb0, *mb1, *mb2, *mb3;
/* prefetches are interleaved with the rest of the code to reduce
pressure on L1 cache */
dpdk_prefetch_buffer (xd->rx_vectors[queue_id][mb_index + 8]);
dpdk_prefetch_ethertype (xd->rx_vectors[queue_id][mb_index + 4]);
mb0 = xd->rx_vectors[queue_id][mb_index];
mb1 = xd->rx_vectors[queue_id][mb_index + 1];
mb2 = xd->rx_vectors[queue_id][mb_index + 2];
mb3 = xd->rx_vectors[queue_id][mb_index + 3];
ASSERT (mb0);
ASSERT (mb1);
ASSERT (mb2);
ASSERT (mb3);
if (maybe_multiseg)
{
if (PREDICT_FALSE (mb0->nb_segs > 1))
dpdk_prefetch_buffer (mb0->next);
if (PREDICT_FALSE (mb1->nb_segs > 1))
dpdk_prefetch_buffer (mb1->next);
if (PREDICT_FALSE (mb2->nb_segs > 1))
dpdk_prefetch_buffer (mb2->next);
if (PREDICT_FALSE (mb3->nb_segs > 1))
dpdk_prefetch_buffer (mb3->next);
}
b0 = vlib_buffer_from_rte_mbuf (mb0);
b1 = vlib_buffer_from_rte_mbuf (mb1);
b2 = vlib_buffer_from_rte_mbuf (mb2);
b3 = vlib_buffer_from_rte_mbuf (mb3);
dpdk_prefetch_buffer (xd->rx_vectors[queue_id][mb_index + 9]);
dpdk_prefetch_ethertype (xd->rx_vectors[queue_id][mb_index + 5]);
clib_memcpy64_x4 (b0, b1, b2, b3, bt);
dpdk_prefetch_buffer (xd->rx_vectors[queue_id][mb_index + 10]);
dpdk_prefetch_ethertype (xd->rx_vectors[queue_id][mb_index + 7]);
bi0 = vlib_get_buffer_index (vm, b0);
bi1 = vlib_get_buffer_index (vm, b1);
bi2 = vlib_get_buffer_index (vm, b2);
bi3 = vlib_get_buffer_index (vm, b3);
to_next[0] = bi0;
to_next[1] = bi1;
to_next[2] = bi2;
to_next[3] = bi3;
to_next += 4;
n_left_to_next -= 4;
if (PREDICT_FALSE (xd->per_interface_next_index != ~0))
{
next0 = next1 = next2 = next3 = xd->per_interface_next_index;
}
else
{
next0 = dpdk_rx_next_from_etype (mb0);
next1 = dpdk_rx_next_from_etype (mb1);
next2 = dpdk_rx_next_from_etype (mb2);
next3 = dpdk_rx_next_from_etype (mb3);
}
dpdk_prefetch_buffer (xd->rx_vectors[queue_id][mb_index + 11]);
dpdk_prefetch_ethertype (xd->rx_vectors[queue_id][mb_index + 6]);
or_ol_flags = (mb0->ol_flags | mb1->ol_flags |
mb2->ol_flags | mb3->ol_flags);
if (PREDICT_FALSE (or_ol_flags & PKT_RX_IP_CKSUM_BAD))
{
dpdk_rx_error_from_mb (mb0, &next0, &error0);
dpdk_rx_error_from_mb (mb1, &next1, &error1);
dpdk_rx_error_from_mb (mb2, &next2, &error2);
dpdk_rx_error_from_mb (mb3, &next3, &error3);
b0->error = node->errors[error0];
b1->error = node->errors[error1];
b2->error = node->errors[error2];
b3->error = node->errors[error3];
}
offset0 = device_input_next_node_advance[next0];
b0->current_data = mb0->data_off + offset0 - RTE_PKTMBUF_HEADROOM;
b0->flags |= device_input_next_node_flags[next0];
vnet_buffer (b0)->l3_hdr_offset = b0->current_data;
vnet_buffer (b0)->l2_hdr_offset =
mb0->data_off - RTE_PKTMBUF_HEADROOM;
b0->current_length = mb0->data_len - offset0;
n_rx_bytes += mb0->pkt_len;
offset1 = device_input_next_node_advance[next1];
b1->current_data = mb1->data_off + offset1 - RTE_PKTMBUF_HEADROOM;
b1->flags |= device_input_next_node_flags[next1];
vnet_buffer (b1)->l3_hdr_offset = b1->current_data;
vnet_buffer (b1)->l2_hdr_offset =
mb1->data_off - RTE_PKTMBUF_HEADROOM;
b1->current_length = mb1->data_len - offset1;
n_rx_bytes += mb1->pkt_len;
offset2 = device_input_next_node_advance[next2];
b2->current_data = mb2->data_off + offset2 - RTE_PKTMBUF_HEADROOM;
b2->flags |= device_input_next_node_flags[next2];
vnet_buffer (b2)->l3_hdr_offset = b2->current_data;
vnet_buffer (b2)->l2_hdr_offset =
mb2->data_off - RTE_PKTMBUF_HEADROOM;
b2->current_length = mb2->data_len - offset2;
n_rx_bytes += mb2->pkt_len;
offset3 = device_input_next_node_advance[next3];
b3->current_data = mb3->data_off + offset3 - RTE_PKTMBUF_HEADROOM;
b3->flags |= device_input_next_node_flags[next3];
vnet_buffer (b3)->l3_hdr_offset = b3->current_data;
vnet_buffer (b3)->l2_hdr_offset =
mb3->data_off - RTE_PKTMBUF_HEADROOM;
b3->current_length = mb3->data_len - offset3;
n_rx_bytes += mb3->pkt_len;
/* Process subsequent segments of multi-segment packets */
if (maybe_multiseg)
{
dpdk_process_subseq_segs (vm, b0, mb0, fl);
dpdk_process_subseq_segs (vm, b1, mb1, fl);
dpdk_process_subseq_segs (vm, b2, mb2, fl);
dpdk_process_subseq_segs (vm, b3, mb3, fl);
}
/*
* Turn this on if you run into
* "bad monkey" contexts, and you want to know exactly
* which nodes they've visited... See main.c...
*/
VLIB_BUFFER_TRACE_TRAJECTORY_INIT (b0);
VLIB_BUFFER_TRACE_TRAJECTORY_INIT (b1);
VLIB_BUFFER_TRACE_TRAJECTORY_INIT (b2);
VLIB_BUFFER_TRACE_TRAJECTORY_INIT (b3);
/* Do we have any driver RX features configured on the interface? */
vnet_feature_start_device_input_x4 (xd->vlib_sw_if_index,
&next0, &next1, &next2, &next3,
b0, b1, b2, b3);
vlib_validate_buffer_enqueue_x4 (vm, node, next_index,
to_next, n_left_to_next,
bi0, bi1, bi2, bi3,
next0, next1, next2, next3);
n_buffers -= 4;
mb_index += 4;
}
while (n_buffers > 0 && n_left_to_next > 0)
{
struct rte_mbuf *mb0 = xd->rx_vectors[queue_id][mb_index];
if (PREDICT_TRUE (n_buffers > 3))
{
dpdk_prefetch_buffer (xd->rx_vectors[queue_id][mb_index + 2]);
dpdk_prefetch_ethertype (xd->rx_vectors[queue_id]
[mb_index + 1]);
}
ASSERT (mb0);
b0 = vlib_buffer_from_rte_mbuf (mb0);
/* Prefetch one next segment if it exists. */
if (PREDICT_FALSE (mb0->nb_segs > 1))
dpdk_prefetch_buffer (mb0->next);
clib_memcpy (b0, bt, CLIB_CACHE_LINE_BYTES);
bi0 = vlib_get_buffer_index (vm, b0);
to_next[0] = bi0;
to_next++;
n_left_to_next--;
if (PREDICT_FALSE (xd->per_interface_next_index != ~0))
next0 = xd->per_interface_next_index;
else
next0 = dpdk_rx_next_from_etype (mb0);
dpdk_rx_error_from_mb (mb0, &next0, &error0);
b0->error = node->errors[error0];
offset0 = device_input_next_node_advance[next0];
b0->current_data = mb0->data_off + offset0 - RTE_PKTMBUF_HEADROOM;
b0->flags |= device_input_next_node_flags[next0];
vnet_buffer (b0)->l3_hdr_offset = b0->current_data;
vnet_buffer (b0)->l2_hdr_offset =
mb0->data_off - RTE_PKTMBUF_HEADROOM;
b0->current_length = mb0->data_len - offset0;
n_rx_bytes += mb0->pkt_len;
/* Process subsequent segments of multi-segment packets */
dpdk_process_subseq_segs (vm, b0, mb0, fl);
/*
* Turn this on if you run into
* "bad monkey" contexts, and you want to know exactly
* which nodes they've visited... See main.c...
*/
VLIB_BUFFER_TRACE_TRAJECTORY_INIT (b0);
/* Do we have any driver RX features configured on the interface? */
vnet_feature_start_device_input_x1 (xd->vlib_sw_if_index, &next0,
b0);
vlib_validate_buffer_enqueue_x1 (vm, node, next_index,
to_next, n_left_to_next,
bi0, next0);
n_buffers--;
mb_index++;
}
vlib_put_next_frame (vm, node, next_index, n_left_to_next);
}
if (PREDICT_FALSE (vec_len (xd->d_trace_buffers[thread_index]) > 0))
{
dpdk_rx_trace (dm, node, xd, queue_id,
xd->d_trace_buffers[thread_index],
vec_len (xd->d_trace_buffers[thread_index]));
vlib_set_trace_count (vm, node,
n_trace -
vec_len (xd->d_trace_buffers[thread_index]));
}
vlib_increment_combined_counter
(vnet_get_main ()->interface_main.combined_sw_if_counters
+ VNET_INTERFACE_COUNTER_RX,
thread_index, xd->vlib_sw_if_index, mb_index, n_rx_bytes);
vnet_device_increment_rx_packets (thread_index, mb_index);
return mb_index;
}dispatch_node
对于VLIB_NODE_TYPE_PRE_INPUT或者VLIB_NODE_TYPE_INPUT类型的node,那么就走dispatch_node的处理流程
static_always_inline u64
dispatch_node (vlib_main_t * vm,
vlib_node_runtime_t * node,
vlib_node_type_t type,
vlib_node_state_t dispatch_state,
vlib_frame_t * frame, u64 last_time_stamp)
{
uword n, v;
u64 t;
vlib_node_main_t *nm = &vm->node_main;
vlib_next_frame_t *nf;
if (CLIB_DEBUG > 0)
{
vlib_node_t *n = vlib_get_node (vm, node->node_index);
ASSERT (n->type == type);
}
/* Only non-internal nodes may be disabled. */
if (type != VLIB_NODE_TYPE_INTERNAL && node->state != dispatch_state)
{
ASSERT (type != VLIB_NODE_TYPE_INTERNAL);
return last_time_stamp;
}
if ((type == VLIB_NODE_TYPE_PRE_INPUT || type == VLIB_NODE_TYPE_INPUT)
&& dispatch_state != VLIB_NODE_STATE_INTERRUPT)
{
u32 c = node->input_main_loops_per_call;
/* Only call node when count reaches zero. */
if (c)
{
node->input_main_loops_per_call = c - 1;
return last_time_stamp;
}
}
/* Speculatively prefetch next frames. */
if (node->n_next_nodes > 0)
{
nf = vec_elt_at_index (nm->next_frames, node->next_frame_index);
CLIB_PREFETCH (nf, 4 * sizeof (nf[0]), WRITE);
}
vm->cpu_time_last_node_dispatch = last_time_stamp;
if (1 /* || vm->thread_index == node->thread_index */ )
{
vlib_main_t *stat_vm;
stat_vm = /* vlib_mains ? vlib_mains[0] : */ vm;
vlib_elog_main_loop_event (vm, node->node_index,
last_time_stamp,
frame ? frame->n_vectors : 0,
/* is_after */ 0);
/*
* Turn this on if you run into
* "bad monkey" contexts, and you want to know exactly
* which nodes they've visited... See ixge.c...
*/
if (VLIB_BUFFER_TRACE_TRAJECTORY && frame)
{
int i;
u32 *from;
from = vlib_frame_vector_args (frame);
for (i = 0; i < frame->n_vectors; i++)
{
vlib_buffer_t *b = vlib_get_buffer (vm, from[i]);
add_trajectory_trace (b, node->node_index);
}
n = node->function (vm, node, frame);
}
else
n = node->function (vm, node, frame);
t = clib_cpu_time_now ();
vlib_elog_main_loop_event (vm, node->node_index, t, n, /* is_after */
1);
vm->main_loop_vectors_processed += n;
vm->main_loop_nodes_processed += n > 0;
v = vlib_node_runtime_update_stats (stat_vm, node,
/* n_calls */ 1,
/* n_vectors */ n,
/* n_clocks */ t - last_time_stamp);
/* When in interrupt mode and vector rate crosses threshold switch to
polling mode. */
if ((dispatch_state == VLIB_NODE_STATE_INTERRUPT)
|| (dispatch_state == VLIB_NODE_STATE_POLLING
&& (node->flags
& VLIB_NODE_FLAG_SWITCH_FROM_INTERRUPT_TO_POLLING_MODE)))
{
#ifdef DISPATCH_NODE_ELOG_REQUIRED
ELOG_TYPE_DECLARE (e) =
{
.function = (char *) __FUNCTION__,.format =
"%s vector length %d, switching to %s",.format_args =
"T4i4t4",.n_enum_strings = 2,.enum_strings =
{
"interrupt", "polling",},};
struct
{
u32 node_name, vector_length, is_polling;
} *ed;
vlib_worker_thread_t *w = vlib_worker_threads + vm->thread_index;
#endif
if ((dispatch_state == VLIB_NODE_STATE_INTERRUPT
&& v >= nm->polling_threshold_vector_length) &&
!(node->flags &
VLIB_NODE_FLAG_SWITCH_FROM_INTERRUPT_TO_POLLING_MODE))
{
vlib_node_t *n = vlib_get_node (vm, node->node_index);
n->state = VLIB_NODE_STATE_POLLING;
node->state = VLIB_NODE_STATE_POLLING;
node->flags &=
~VLIB_NODE_FLAG_SWITCH_FROM_POLLING_TO_INTERRUPT_MODE;
node->flags |=
VLIB_NODE_FLAG_SWITCH_FROM_INTERRUPT_TO_POLLING_MODE;
nm->input_node_counts_by_state[VLIB_NODE_STATE_INTERRUPT] -= 1;
nm->input_node_counts_by_state[VLIB_NODE_STATE_POLLING] += 1;
#ifdef DISPATCH_NODE_ELOG_REQUIRED
ed = ELOG_TRACK_DATA (&vlib_global_main.elog_main, e,
w->elog_track);
ed->node_name = n->name_elog_string;
ed->vector_length = v;
ed->is_polling = 1;
#endif
}
else if (dispatch_state == VLIB_NODE_STATE_POLLING
&& v <= nm->interrupt_threshold_vector_length)
{
vlib_node_t *n = vlib_get_node (vm, node->node_index);
if (node->flags &
VLIB_NODE_FLAG_SWITCH_FROM_POLLING_TO_INTERRUPT_MODE)
{
/* Switch to interrupt mode after dispatch in polling one more time.
This allows driver to re-enable interrupts. */
n->state = VLIB_NODE_STATE_INTERRUPT;
node->state = VLIB_NODE_STATE_INTERRUPT;
node->flags &=
~VLIB_NODE_FLAG_SWITCH_FROM_INTERRUPT_TO_POLLING_MODE;
nm->input_node_counts_by_state[VLIB_NODE_STATE_POLLING] -=
1;
nm->input_node_counts_by_state[VLIB_NODE_STATE_INTERRUPT] +=
1;
}
else
{
node->flags |=
VLIB_NODE_FLAG_SWITCH_FROM_POLLING_TO_INTERRUPT_MODE;
#ifdef DISPATCH_NODE_ELOG_REQUIRED
ed = ELOG_TRACK_DATA (&vlib_global_main.elog_main, e,
w->elog_track);
ed->node_name = n->name_elog_string;
ed->vector_length = v;
ed->is_polling = 0;
#endif
}
}
}
}
return t;
}dispatch_node这个函数的核心是调用了注册node的function函数:
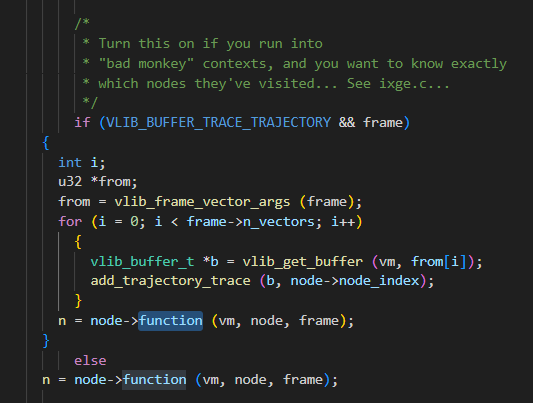
需要注意语句n = node->function (vm, node, frame)中的返回值n对于我们来讲没有用。因为在vpp中定义的VLIB_NODE_TYPE_PRE_INPUT类型的node在注册的时候没有定义next_nodes:
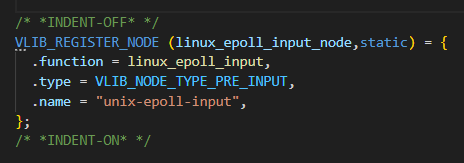
这里总结下dispatch_node这个函数的核心作用就是执行了一个epoll。

















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









