




 本文介绍了Python爬虫库Requests的易用性和核心功能,包括简洁的网络请求、自动URL参数处理、响应内容的自动解码和手动处理。通过实例展示了GET和POST请求的发送、自动URL编码、响应内容的自动解码与手动指定编码,以及JSON响应内容的处理。
本文介绍了Python爬虫库Requests的易用性和核心功能,包括简洁的网络请求、自动URL参数处理、响应内容的自动解码和手动处理。通过实例展示了GET和POST请求的发送、自动URL编码、响应内容的自动解码与手动指定编码,以及JSON响应内容的处理。
前边三个章节我们学习了Python内置的爬虫请求库urllib的使用。说起urllib,它也算是挺强大了,可定制程度很高。
但是它有一个最大的问题,那就是使用起来还是不够方便,在处理一些复杂的功能比如会话、验证等时会比较复杂,甚至为了给URL添加一些请求参数,我们还得专门将这些参数进行编码。
于是有了Requests。
再优美的语言都无法形容Requests的强大和好用。它的语法非常简洁,哪怕实现非常复杂的功能,往往也仅需要短短的一行或几行代码,实在是爬虫新手甚至老手的福音。
简洁优雅的API并不能掩盖Requests的强大,易用的会话功能、优雅的Key-Value Cookie、SSL证书验证、各种身份验证……毫不夸张地说,掌握了Requests,面对绝大多数的网站你都不需要再发怵。
那么接下来的几个章节,我就带大家学习一下如何使用Requests。
首先我们需要保证我们的Python环境中已经安装了Requests包,如果没有安装的话,我们可以在命令行中通过pip install requests或者conda install requests等命令直接安装,非常简单。
一、一行代码发送网络请求
在Requests中,发送网络请求简单得就像喝水。我们知道,常见的网络请求有八种:
| 类型 | 注释 |
|---|---|
GET | 一般来说,我们要从服务器读取文档时,使用的最多的方法就是GET。使用GET方法时,请求参数会附加在URL后方,以?开始,其能接受的参数是有限的,因为大多数浏览器会对URL的长度做限制。当我们打开百度首页时,就是完成了一次GET请求。 |
POST | POST方法将请求参数封装在HTTP请求数据中,以名称/值的形式出现,可以传输大量数据,这样POST方式对传送的数据大小没有限制,而且也不会显示在URL中。我们经常用POST方法向服务器提交资源,比如表单数据、文件等。 |
HEAD | HEAD和GET比较像,但是服务端接受请求后仅返回响应头,而不返回响应体。如果我们的目的只是查看某个页面的状态或者页面是否被篡改、更新,那么使用HEAD方法是很高效的,毕竟我们节省了响应体的传输过程。 |
PUT | PUT方法用于向指定资源位置上传内容。PUT和POST的区别主要在于PUT被定义为idempotent方法,而POST不是。换言之,如果两个PUT请求相同,那么后一个请求会把第一个请求覆盖掉(所以PUT可以用来改资源);如果两个POST请求相同,后一个请求不会把第一个请求覆盖掉(所以POST可以用来增加资源)。 |
DELETE | DELETE方法用于请求服务器删除某资源。 |
CONNECT | CONNECT是HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
TRACE | TRACE用于回显服务器收到的请求,主要用于测试或诊断。 |
OPTIONS | OPTIONS用于查看服务器的性能。一般来说,使用它主要是为了获取服务器支持的请求类型或者查看服务器类型,以确保接下来发送的请求足够安全。 |
在这之中,最常用的就是GET和POST方法了。事实上,我们在写爬虫的过程中,绝大多数的请求都是这两种。下面可以看两个简单的例子:
import requests
# 发起GET请求
response = requests.get('https://www.baidu.com')
# 发起POST请求
response = requests.post('http://httpbin.org/post', data={'name': 'oldq'})
发起DELETE、HEAD等请求也是一样的简单,这里就不赘述了。
二、不需要额外编码的URL参数
我们知道,在使用urllib传递参数时,我们还需要对参数进行编码。而在Requests中,我们完全不需要执行这样繁琐的操作。
params= {'name': '老Q在折腾'}
r = requests.get("http://httpbin.org/get", params=params)
r = requests.get(url, params=params)
print(r.url)
输出为:
http://httpbin.org/get?name=%E8%80%81Q%E5%9C%A8%E6%8A%98%E8%85%BE
可以看到,我们直接把包含中文的字典传递进去以后,它自动就将其进行了URL编码,不需要我们做额外的处理。
三、响应内容的自动解码和手动处理
1. 自动解码
在urllib中,如果响应体的内容中包含了一些Unicode编码的内容,我们需要对其做解码操作。而在Requests中,我们已不再需要此步骤。
url = 'https://www.oldq.top'
r = requests.get(url)
print(r.encoding)
print(r.text)
输出为:
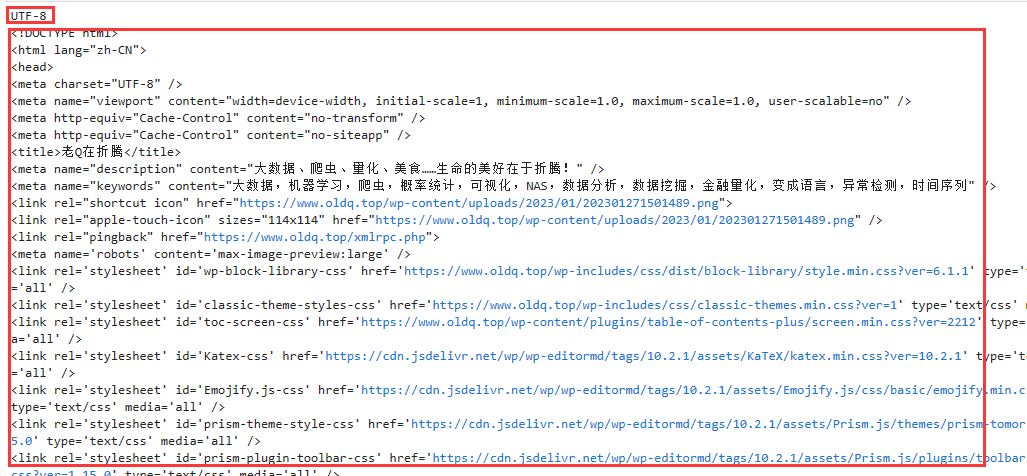
2. 指定编码格式
如果Requests检测的编码错误,我们还可以手动改正。以百度首页为例:
url = 'https://www.baidu.com'
r = requests.get(url)
print(r.encoding)
print(r.text)
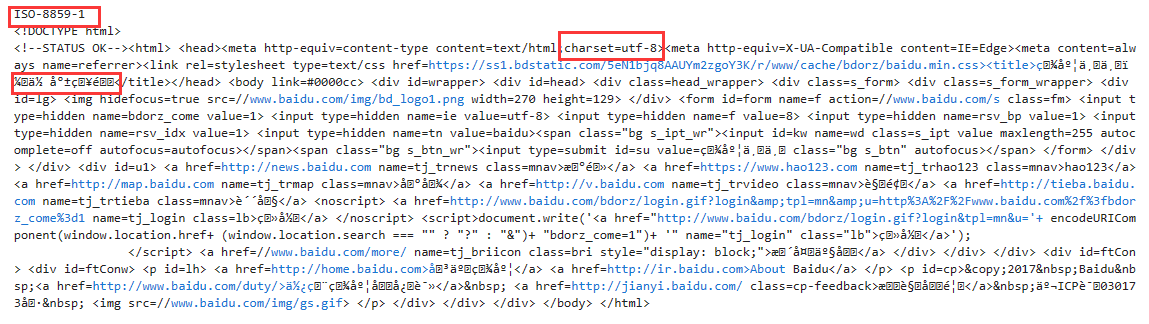
我们看到,百度声明了响应的内容编码为UTF-8,但是Requests错误地将其识别为ISO-8859-1,导致解码出来的内容变成了乱码。我们来手动改正一下。
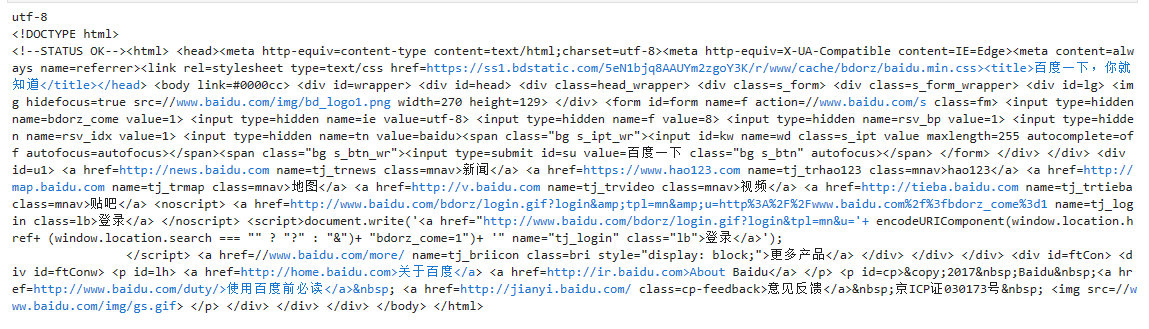
r.encoding = 'utf-8'
print(r.encoding)
print(r.text)
看,一切恢复了正常。
3. 接收并处理Bytes数据
当然,我们也可以直接以Bytes的格式查看数据。并对Bytes格式的数据进行我们期望的处理。
print('Bytes:', r.content, '\n'*3)
print('Decoded:', r.content.decode('utf-8'))
如果我们以这样的方式解码数据,那跟urllib就比较像了。

4. JSON响应内容
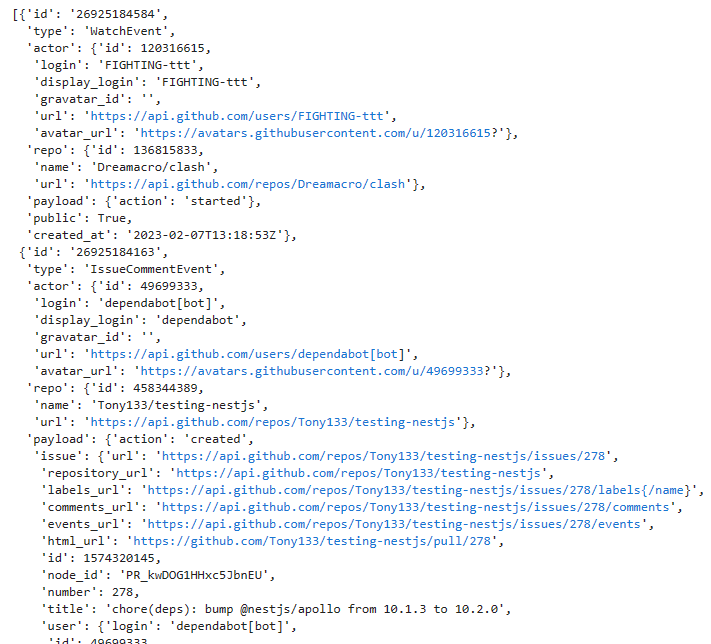
当响应内容是JSON格式时,我们还可以使用Requests内置的JSON解码器来处理它。
r = requests.get('https://api.github.com/events')
r.json()
可以看到,我们拿到了JSON格式的数据,我们可以直接通过索引、KEY来访问其中的元素。
好了,这节课我们就到这里,下节课我们会学习在Requests中定制请求头、发送更复杂的请求等,欢迎大家关注老Q或者购买专栏!



















 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











