



本文作者系360奇舞团前端开发工程师
随着AI的发展,模型能力越来越强大,“氛围编程”等新的开发逻辑正在逐步的渗透到了编程领域。
相信在不久的将来,一定是某几个agent配合就可以完成大部分的软件研发工作。
曾经所谓的自动化流程也会被真正的AI自动化流程所取代。 以前的自动化更多的是处理庞大的边界case,使得程序能够顺利运行。
而AI的自动化流程更像趋近于人的思维模式,产品经理需要设计产品原型,之后设计师需要去完成设计,那么下一步就是交由研发来去实现原型,最后再由测试去验证。

当用户抛出一个问题的时候,程序也能快速的知道应该是哪一个角色去处理这个问题,以及后续流程是否需要继续来保证完成用户真正的需求。
当然这些还都是对未来的美好的憧憬,多agent未来可能是会做到很完美的配合工作,但现在还很难。
agent流程目前看还做不到完全的自动化,或者说它的自动化还是需要一个系统级别的编排处理。同时假如某个agent在处理时发生了错误,或者产出了意想不到的结果,那往往后续的产出会跟随这个错误去接下来处理,那么最终结果与自己的期望可能会大相径庭。
这个跟模型能力有关。未来模型足够强的时候,也许会产生完全自洽的处理能力。那如果我们要设计多agent的系统,该如何保证其尽量不出问题呢?
其实方法很简单,就是人工干预,用工程化的能力来解决大模型的不确定性。
通过人工配置和prompt工程来完成多agent的流转问题。 现在好多现有的平台已经有了这种能力了,可以用不同的agent来模拟一个软件研发流程,通过系统级的调度,来完成多agent之间的配合。
针对agent的稳定性问题,可以从以下几点总结:
确定流程节点
做任何的多agent的流转,先要确定当没有agent的时候,这件事的正常流转是什么样的,每一个步骤应该都不能省略。
以下面的一个代码研发流程为例:
这些步骤应该都不能省略,每一步都应该一个agent,或者是一个agent的工具能力。这样才能尽可能的保证代码生成的稳定性。
在此过程中,注意哪些部分感觉重复或机械化。这些是可以交给模型去处理的。
我们产品或产物可能会有。
如果模型即使经过调整也始终无法取得进展,那么这个任务可能不适合代理。但如果它有效,或者甚至接近有效,就值得继续。
像上面说的多步骤实现会有资源浪费问题。
比如一个简单的问题,需要流转到好几个agent,调用几次甚至数十次的LLM无疑是巨大的浪费,这需要我们的工程有明确的逻辑能力,模型去做判断角色(下面会介绍的第二点就是这个)。
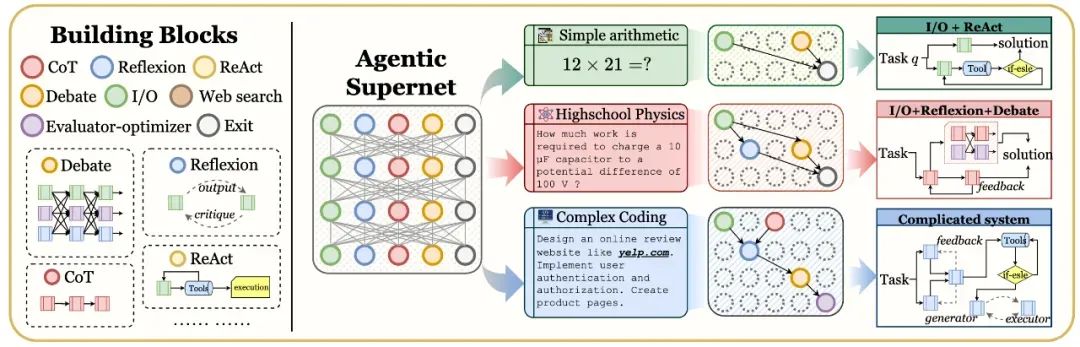
还有一种解决方案最近在网上看到的,叫做 “智能体超网”(Agentic Supernet)。与现在的选择agent方式不同,它是自动选择的,不会出现过度浪费问题
确定输入输出
一旦确定了上面的执行流程步骤,我们就可以来确定每一个字agent,或者细化到每一个工具的输入和输出。
把上下文逻辑梳理好后,将整个过程构建成一个循环或简单的状态机。要让我们的工程能力来保证输出的稳定性,在需要逻辑或判断时调用模型,基于结果,决定是继续还是退出。
我们一定要保证一些关键的步骤是我们手写代码来完成的,大模型的发散性使得它很不可控,这也是我们之前项目遇到的最大问题,所以我们才考虑用工程化的能力来解决这个问题。
当然现在即使大模型也会有一些发散的情况,但我们已经努力把它降到最低了。
写一些if else我觉得没有什么不好。现在还没到AI解决一切问题的时候。
优化功能
1.关键步骤产出的check
对于大语言模型的产出,举个例子是XML结构化的产出能让大模型产出的更准确。因为它们在训练时就学习了大量结构化的数据,对这种结构更加敏感。
那么我们检测的时候,就可以判断结构是否完整,如果没有开闭合,那么大概率是不符合预期的,就需要我们再次调整或者降级策略。
2. 工具调用的准确性
我们要描述的足够清楚,每个工具或者agent的能力是什么,它应该在什么条件下触发,让模型可以清楚的知道理解这些工具对整个系统的产出也是很重要的。
其实总结起来,多agent或者AI时代的开发和传统开发还是有好多的逻辑相通的地方。
比如清晰的逻辑、结构和准确的输入输出,这些都是编程领域需要的。生产力的提升也未必会全面替代,就像低代码平台的出现也没有减少前端的岗位。
未来的前端工程师,将更注重逻辑思维、产品意识与协作能力。我们需要理解业务、定义问题、设计系统,并与AI协同工作,而不是被AI替代。这是一次角色的重塑,也是一次能力的跃迁。
-END -
如果您关注前端+AI 相关领域可以扫码进群交流

添加小编微信进群😊
关于奇舞团
奇舞团是 360 集团最大的大前端团队,非常重视人才培养,有工程师、讲师、翻译官、业务接口人、团队 Leader 等多种发展方向供员工选择,并辅以提供相应的技术力、专业力、通用力、领导力等培训课程。奇舞团以开放和求贤的心态欢迎各种优秀人才关注和加入奇舞团。


















 862
862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









