




前言:为什么需要ROI Pooling?
在目标检测任务中,我们通常会遇到一个问题:如何将不同大小的候选框(Region of Interest, ROI)转换为固定大小的特征表示? 这是因为目标检测模型中的全连接层需要固定长度的输入。
想象一下,如果你有一堆不同大小的盒子(候选框),但需要一个标准大小的盒子来放入你的展示柜(全连接层),你会怎么做?这就是ROI Pooling要解决的问题!🎯
一、ROI是什么?
ROI(Region of Interest),中文称为"感兴趣区域",是指从原始图像中提取的可能包含目标的区域。在目标检测中,这些区域通常以边界框(bounding box)的形式表示。

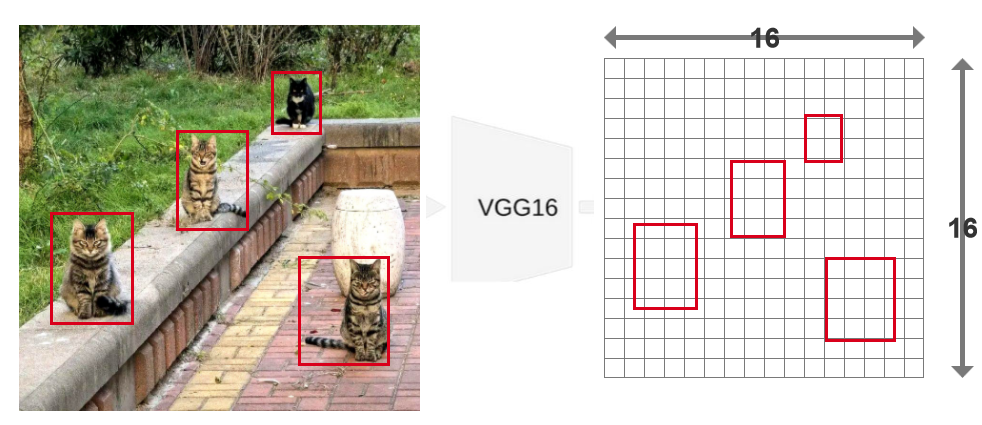
图中红色框就是ROI的示例
二、ROI Pooling的作用
ROI Pooling的主要作用是将不同大小的ROI转换为固定大小的特征图,以便后续的全连接层能够进行处理。它的核心思想可以概括为:
- 定位:将原始图像上的ROI映射到特征图上的对应区域
- 划分:将映射后的区域划分为固定数量的网格
- 池化:对每个网格执行最大池化操作,得到固定大小的输出
三、ROI Pooling具体步骤
步骤1:ROI映射到特征图
假设我们原图上面有4只猫被框出来,通过VGG转变成16*16的特征图。右边红框就是缩放后猫在特征图上的位置。我们可以看出特征图上每个猫框的大小都不一样。接下来我们就要进行坐标量化。
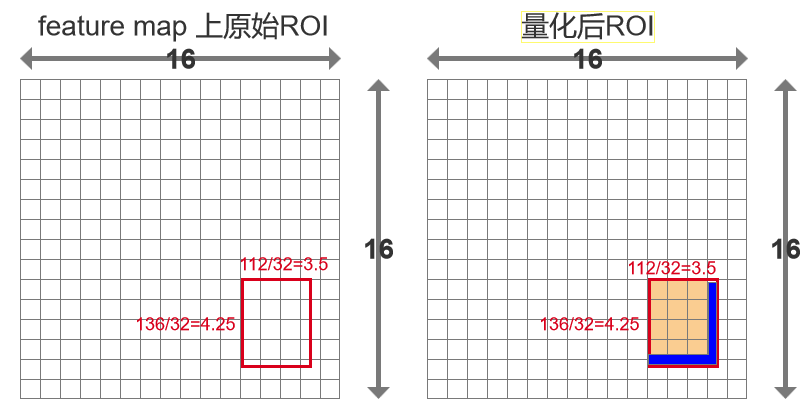
步骤2:坐标量化(取整操作)
由于特征图上的坐标必须是整数,我们需要对浮点坐标进行量化(即取整操作):

每个ROI都有他的原始坐标和大小,我们以一个框为例,假设原始大小为112*136。左上角坐标(296,192)假设我们把这张图进行VGG 32倍下采样,下采样之后:
width:112/32=3.5
height:136/32=4.25
x:296/32=9.25
y:192/32=6
我们保留整数部分,小数部分舍弃掉,所以可以看出ROI Pooling量化过程中,会有数据丢失(蓝色区域),也会获得新的数据(橙色区域)。
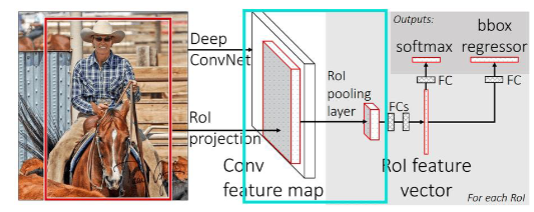
步骤3:最大池化操作
以Fast RCC网络为例,在ROI池化层后是一个固定大小的全连接层,但是我们量化后的ROI大小不统一,所以我们要将他们池化为相同大小。
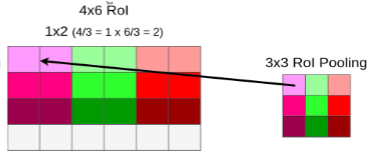
假设我们将大小为4×6×512的ROI映射成可被全连接接受的统一尺寸,假设统一尺寸为3*3,我们用1×2的大小做池化,保留最大值,这样就得到了对感兴趣区域的池化,由于量化,我们失去了最底下的那行。
四、ROI Pooling的局限性
ROI Pooling虽然有效,但也存在明显的局限性:量化误差。
在两次取整操作中(坐标映射和网格划分),都会导致信息损失和定位偏差。这种误差在大目标或需要精确定位的任务中尤为明显,可能导致检测精度下降(约10% mAP损失)。
五、改进方法:ROI Align
为了解决ROI Pooling的量化误差问题,Mask R-CNN提出了ROI Align方法。
ROI Align的改进点:
- 取消量化操作:保留浮点坐标,不进行取整
- 双线性插值:在每个网格内采样多个点,通过插值计算特征值
- 连续池化:避免特征图与ROI之间的空间错位
ROI Align工作流程:
- 将RO区域划分为固定数量的网格(如2×2)
- 在每个网格中采样多个点(通常为4个)
- 使用双线性插值计算每个采样点的值
- 对每个网格内的采样值进行聚合(最大池化或平均池化)
ROI Align通过避免量化误差,显著提高了目标检测和实例分割的精度,尤其是在需要精确定位的任务中。
六、总结与对比
|
特性 |
ROI Pooling |
ROI Align |
|---|---|---|
|
坐标处理 |
两次量化(取整) |
保留浮点数 |
|
精度 |
有误差(~10% mAP损失) |
高精度 |
|
计算复杂度 |
低 |
较高(需要插值) |
|
典型应用 |
Fast R-CNN, Faster R-CNN |
Mask R-CNN |
|
数据利用 |
部分数据丢失 |
利用所有数据 |
七、代码实现示例
以下是ROI Pooling的简化伪代码实现:
def roi_pooling(feature_map, rois, output_size):
"""
feature_map: 输入特征图
rois: ROI列表,每个ROI包含[x1, y1, x2, y2]
output_size: 输出尺寸,如(2, 2)
"""
outputs = []
for roi in rois:
# 1. 将ROI映射到特征图
x1 = round(roi[0] * spatial_scale)
y1 = round(roi[1] * spatial_scale)
x2 = round(roi[2] * spatial_scale)
y2 = round(roi[3] * spatial_scale)
# 2. 计算ROI尺寸
roi_height = y2 - y1 + 1
roi_width = x2 - x1 + 1
# 3. 划分网格
bin_size_h = roi_height / output_size[0]
bin_size_w = roi_width / output_size[1]
# 4. 最大池化
pool_result = []
for i in range(output_size[0]):
for j in range(output_size[1]):
# 计算每个网格的边界
h_start = floor(i * bin_size_h)
w_start = floor(j * bin_size_w)
h_end = ceil((i + 1) * bin_size_h)
w_end = ceil((j + 1) * bin_size_w)
# 提取网格区域并应用最大池化
grid_region = feature_map[y1+h_start:y1+h_end,
x1+w_start:x1+w_end]
pool_result.append(np.max(grid_region))
outputs.append(reshape(pool_result, output_size))
return outputs
结语
ROI Pooling是目标检测中一项关键技术,它通过巧妙的量化和池化操作,解决了不同大小区域生成固定大小特征的难题。虽然它有量化误差的局限性,但其思想为后续的ROI Align等改进方法奠定了基础。
希望这篇博客能帮助你理解ROI Pooling的原理和实现!如果你有任何问题或建议,欢迎在评论区留言交流~💬


















 85
85

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











