




前言:目标检测的"革命性"思路
在YOLO(You Only Look Once)问世之前,目标检测算法就像是一个人拿着放大镜在图片上一点点寻找目标:先找可能包含物体的区域,再对这些区域进行分类。这种方法准确但速度慢,难以实时处理。
2016年,Joseph Redmon等人提出YOLO V1,带来了一种革命性的思路:为什么不把目标检测当作一个回归问题,只需"看一眼"图片就能直接输出所有检测结果呢? 这就是YOLO名称的由来——You Only Look Once。
一、YOLO V1的核心思想 🧠
1.1 直观理解:网格划分思维
YOLO V1的核心思想非常直观:
-
将输入图像划分为S×S的网格(论文中S=7,即7×7=49个网格)。
-
物体bbox中心落在哪个网格上,就由该网格对应锚框负责检测该物体。
-
每个网格预测B个边界框(Bounding Box)以及这些框的置信度(论文中B=2)。
-
每个网格还预测物体的类别概率。
举个例子🌰:假如我们要检测图像中狗。狗的中心点在右下角网格内,就由那个网格负责预测狗。可以理解给给定了98个框画在一张图上,图像分类的同时对框的大小进行调解,调解到框的大小和标注大小雷同。
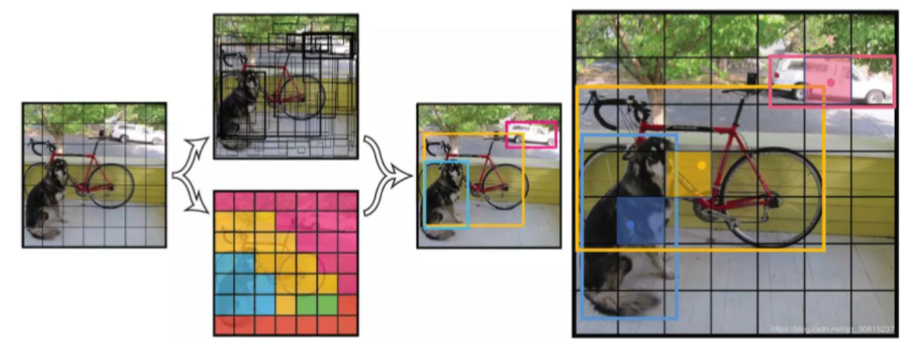
1.2 YOLO V1方法 vs传统方法对比
为了更好地理解YOLO的创新性,我们对比一下传统方法和YOLO方法的不同之处:
| 特性 | YOLO V1 | R-CNN系列 |
|---|---|---|
| 检测阶段 | 单阶段(端到端) | 两阶段(Proposal+分类) |
| 速度 | 45-155 FPS | 7-20 FPS |
| 背景误检率 | 低 | 高 |
| 小目标检测 | 较弱 | 较强 |
| 泛化能力 | 强(跨领域适用) | 较弱 |
二、YOLO V1网络结构详解 🏗️
2.1 整体架构
YOLO V1的网络结构受GoogLeNet启发,包含24个卷积层和2个全连接层。其整体架构和流程可概括为以下步骤:
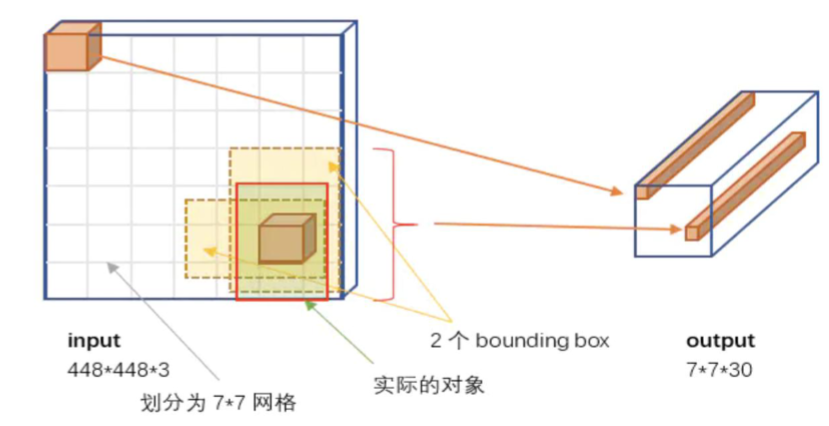
输入图片(448×448×3) → 卷积神经网络(CNN)特征提取 → 全连接层 → 输出张量(7×7×30)
其网络结构如下表所示:
|
网络层类型 |
参数设置 |
输出尺寸 |
说明 |
|---|---|---|---|
|
卷积层 |
7×7×64, stride=2 |
224×224×64 |
提取大范围纹理特征 |
|
最大池化 |
2×2, stride=2 |
112×112×64 |
下采样 |
|
卷积层 |
3×3×192 |
112×112×192 |
特征增强 |
|
最大池化 |
2×2, stride=2 |
56×56×192 |
下采样 |
|
卷积层 |
1×1×128, 3×3×256 |
56×56×256 |
特征提取 |
|
...(更多卷积层) |
... |
... |
... |
|
最终卷积输出 |
- |
7×7×1024 |
高层语义特征 |
|
全连接层 |
4096个节点 |
4096 |
连接所有特征 |
|
输出层 |
1470个节点 |
7×7×30 |
检测结果 |
2.2 输出张量的含义
YOLO V1最巧妙的设计在于其输出张量的设计。输出为7×7×30的张量,这到底代表什么呢?
-
7×7:表示将输入图像划分成的网格数量
-
30:每个网格预测的信息维度,具体包含:
-
2个边界框的预测:每个框预测5个值(x, y, w, h, confidence)
-
20个类别的概率预测(针对PASCAL VOC数据集的20个类别)
-
所以,30 = 2 × 5 + 20 = 10 + 20 📊
2.3 边界框的编码方式
YOLO V1对边界框的坐标进行了巧妙的归一化处理:
-
(x, y):边界框中心相对于当前网格的偏移量,范围在0-1之间
-
(w, h):边界框的宽高相对于整个图像的比例,范围在0-1之间
这种归一化处理使得模型更容易学习和收敛。
三、YOLO V1的置信度与预测过程 🔍
3.1 置信度(Confidence)的含义
置信度是YOLO中一个关键概念,它表示边界框内包含目标的可能性以及预测框的准确程度。其计算公式为:
Confidence = Pr(Object) × IoU
其中:
-
Pr(Object):该网格是否包含目标(0或1)
-
IoU(交并比):预测框与真实框的重叠程度
如果网格不包含目标,置信度为0;如果包含,置信度等于IoU值。
3.2 类别概率预测
每个网格还预测20个类别的条件概率:P(Classᵢ | Object),即给定网格包含目标的前提下,属于每个类别的概率。
3.3 最终检测得分计算
当我们既想知道是什么物体,又想知道位置有多准时,需要将类别概率和置信度相乘:
最终得分 = P(Classᵢ | Object) × Confidence
这个得分同时反映了分类的准确度和定位的精确度。
3.4 预测流程概览
下图总结了YOLO V1从输入图像到最终检测结果的完整流程:
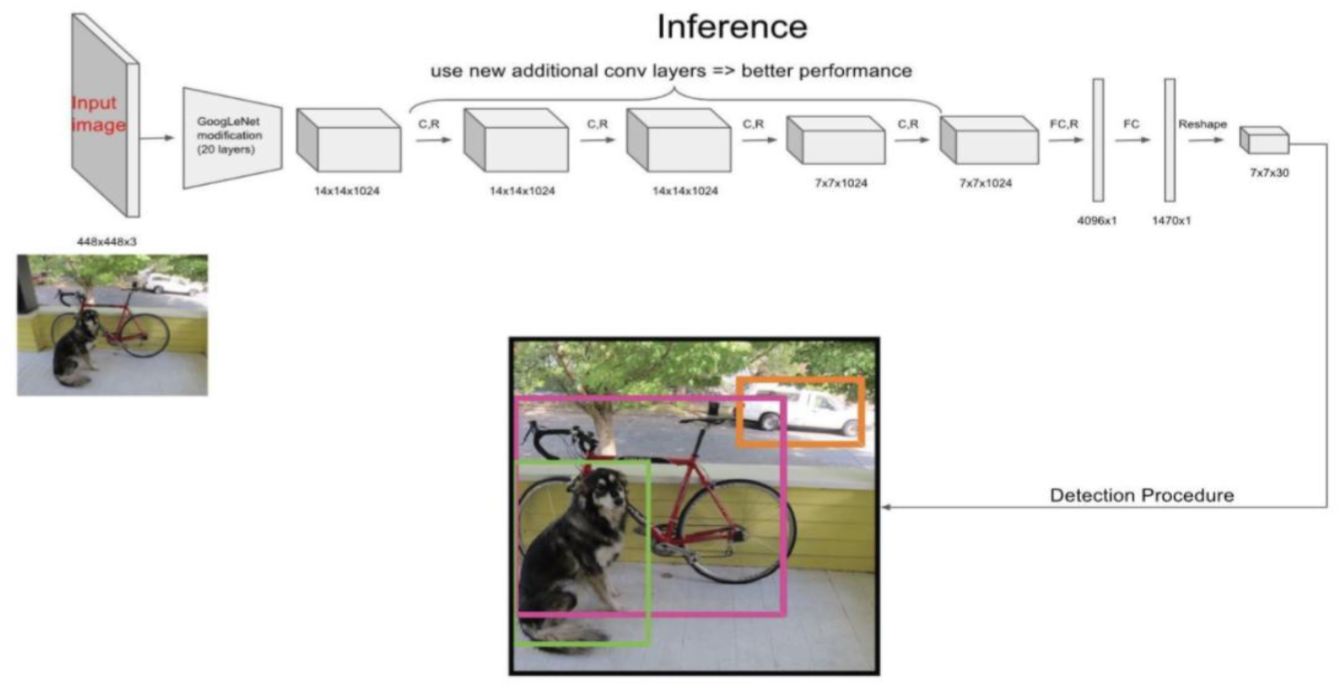
步骤一:输入图像 🖼️
-
图像被固定尺寸调整为448x448像素,包含RGB三个颜色通道,准备送入网络。
-
这是YOLO V1的标准输入尺寸。
步骤二:网格划分 🔲
-
图像在神经网络内部被逻辑上划分成了一个7x7的网格。图中的
GoogLeNet和一系列C.R(卷积与下采样)层的作用,就是逐步提取特征并将空间信息压缩到这个7x7的特征图上。 -
每个网格单元将负责预测中心点落在其内的物体。
步骤三:每个网格预测边界框与类别 📦
-
对于7x7=49个网格中的每一个,网络都预测了一个30维的向量。这30个数字包含:
-
①边界框信息:每个网格预测2个边界框(共2 * 5=10个值),每个框有4个定位值(x, y, w, h)和1个置信度。
- ②类别信息:预测20个类别的概率(针对PASCAL VOC数据集)。
-
所以,30 = 2个框 * 5个参数 + 20个类别概率。
步骤四:计算最终检测得分 & 步骤五:非极大值抑制(NMS)⚖️
- 计算最终得分(D):系统将每个边界框的“类别概率”和“框的置信度”相乘,得到一个综合得分,同时反映了“是什么”和“位置有多准”。
- 非极大值抑制-NMS(E):这一步是生成右侧干净结果的关键。对于同一只狗,最初可能有两个框(绿色和粉色)都预测了它。NMS算法会计算这些框的重叠度(IoU),然后只保留得分最高的那个,抑制掉重叠度高但得分低的冗余预测框。这正是右图中狗狗最终只有一个绿色框,而另一个粉色框消失的原因!
步骤六:最终检测结果 ✅
-
流程的最终输出!一张干净、准确的检测图,标出了每个物体的位置和类别。
四、YOLO V1的损失函数设计 📉
YOLO V1的损失函数是一个多任务加权损失函数,同时优化定位、置信度和分类三个目标。其数学表达式如下:
4.1 损失函数的五个组成部分
-
边界框中心坐标损失(定位损失)
-
边界框宽高损失(定位损失)
-
包含目标的置信度损失
-
不包含目标的置信度损失
-
分类损失
4.2 损失函数的设计技巧
YOLO V1的损失函数设计中有几个精妙之处:
-
宽高开根号:对小目标更敏感,避免小目标损失被大目标淹没
-
权重平衡:对不同部分赋予不同权重(坐标损失权重为5,背景置信度损失权重为0.5)
-
负样本筛选:只对与真实框IoU最大的负样本计算损失,减轻样本不平衡问题
这种精细的损失函数设计使得YOLO能够同时学习定位、识别和置信度评估。
五、YOLO V1的优缺点分析 ⚖️
5.1 优点 ✅
-
速度快:45 FPS(Titan X GPU),真正实现实时检测
-
全局上下文理解:使用整张图像作为上下文,背景误检率低
-
强泛化能力:在不同领域和场景下表现良好
-
端到端训练:结构简单,易于实现和部署
5.2 缺点 ❌
-
空间约束强:每个网格只能预测固定数量的目标(2个),对密集小目标检测效果差
-
泛化能力有限:对不常见长宽比的物体检测效果不佳
-
定位误差较大:尤其是大小物体的处理上有待加强
-
全连接层参数量大:导致模型参数较多
六、YOLO V1的实践意义与影响 🌟
尽管YOLO V1有一些局限性,但它的开创性思想为后续目标检测算法的发展指明了方向。它的"单阶段检测"思路被后续众多算法借鉴和发展,形成了完整的YOLO系列算法。
YOLO V1的成功证明了将目标检测转化为回归问题的可行性,为实时目标检测应用(如自动驾驶、视频监控、机器人导航等)奠定了基础。
总结 💡
YOLO V1作为单阶段目标检测算法的开创者,其核心思想简洁而强大:将目标检测转化为单一的回归问题,通过划分网格的方式实现"一眼看全"的检测效果。虽然它在精度上可能不如一些两阶段算法,但在速度与精度的平衡上找到了一个完美的结合点。
正如其名"You Only Look Once",YOLO V1告诉我们:有时候,复杂的问題也许只需要一个简单的思路就能解决。这正是深度学习的魅力所在——用简单的网络结构解决复杂的视觉问题。
希望这篇博客能帮助你理解YOLO V1的基本原理!如果你有任何问题,欢迎在评论区留言讨论~ 😊



















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











