






大家好!今天咱们来聊聊机器学习中一个超有趣又实用的领域——聚类算法😎。相信很多小伙伴对机器学习都有所耳闻,但聚类算法具体是啥,和分类算法又有啥区别呢?别急,咱们慢慢唠。
📌什么是聚类算法?
💡直观理解
想象一下,你有一大堆五颜六色的球,红的、蓝的、绿的……它们都混在一起。现在,你要做的就是根据颜色把这些球分成不同的组,红色的放一堆,蓝色的放一堆,绿色的放一堆。在机器学习中,聚类算法干的就是类似的事儿,只不过它处理的是数据,而不是球。
聚类算法是一种无监督学习算法,它不需要我们提前告诉它数据应该分成几类,或者每一类是什么样的。它就像一个聪明的“分类小能手”,核心人物就是:把相似的数据点自动分到同一组,让同一组(簇cluster)内的数据尽可能相似,不同组的数据尽可能不同👏。
📊具体示例
下面这张图就很好地展示了聚类算法的效果。
这里假设是一张二维数据经过聚类算法后分成三个簇的散点图,不同簇用不同颜色表示。
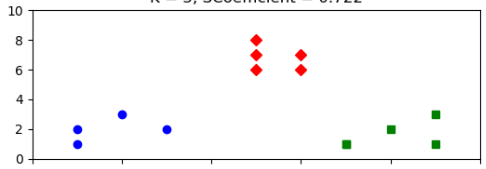
在这个图中,每个点代表一个数据样本,横坐标和纵坐标是数据的两个特征。聚类算法通过计算这些点之间的距离或相似度,把它们分成了三个簇,分别用红色、蓝色和绿色表示。从图中可以直观地看到,同一簇内的点比较接近,不同簇的点相对较远。
📋聚类算法主要类型(附典型算法)
| 算法类型 | 核心思想 | 代表算法 | 特点 |
|---|---|---|---|
| 原型聚类 | 通过中心点定义簇结构 | K-Means、LVQ | 速度快,适合球形分布数据 |
| 密度聚类 | 基于样本分布密度 | DBSCAN、OPTICS | 可识别任意形状簇,抗噪性强 |
| 层次聚类 | 构建树状层次结构 | AGNES、BIRCH | 无需预设簇数,可视化直观 |
| 模型聚类 | 基于概率分布建模 | 高斯混合模型 | 可估计样本属于各簇的概率 |
| 网格聚类 | 基于空间网格划分 | STING、CLIQUE | 处理大规模数据效率高 |
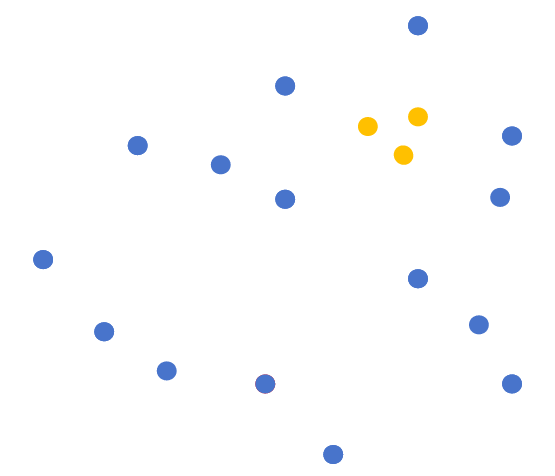
🛠️聚类算法的工作原理(以K-Means为例)
K-Means是最常用的聚类算法之一,其工作原理就像不断优化的“分组游戏”:
-
初始化:随机选择K个点作为初始簇中心(如K=3
-
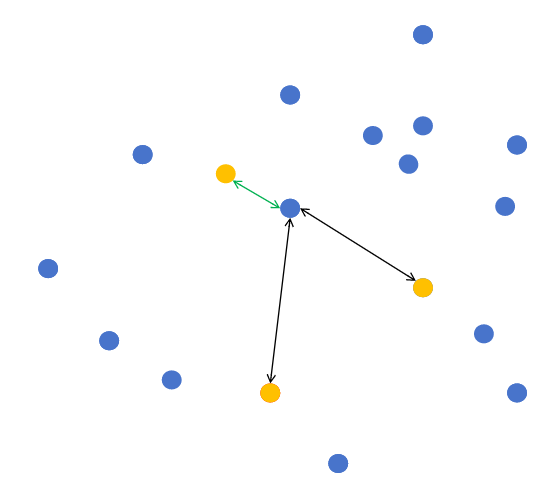
分配数据点:计算每个点到各中心的距离,分配到最近中心所在的组📏
(常用欧氏距离:d = √[(x₁-x₂)² + (y₁-y₂)²]) -
更新中心点:重新计算每个组的中心点(取组内所有点的平均值)🔄
-
迭代优化:重复步骤2-3,直到中心点不再变化或达到最大迭代次数⚙️
关键点:K-Means对离群点敏感,因此改进版K-Medoids要求中心点必须是实际数据点
📌聚类算法和分类算法的区别
🎯目标不同
- 分类算法:分类算法是一种有监督学习算法,它的目标是根据已知的数据类别信息,学习一个分类模型,然后用这个模型去预测新数据的类别。就好比我们已经知道了一些水果是苹果,一些是香蕉,通过学习这些水果的特征,我们就能判断一个新的水果是苹果还是香蕉🍎🍌。
- 聚类算法:聚类算法的目标是发现数据中的内在结构,把相似的数据聚集在一起,形成不同的簇,它并不关心数据的类别标签。就像前面说的分球例子,我们只是根据颜色把球分组,并不知道这些球原本有没有特定的类别。
📚数据要求不同
- 分类算法:需要大量的带有类别标签的训练数据。这些标签就像是“参考答案”,让算法能够学习到如何根据特征来正确分类。没有标签数据,分类算法就“巧妇难为无米之炊”啦😅。
- 聚类算法:只需要数据本身,不需要类别标签。它可以从数据中自动挖掘出潜在的模式和结构,即使我们对数据一无所知,也能通过聚类算法得到一些有价值的信息👏。
📈评估方式不同
- 分类算法:通常使用准确率、召回率、F1 值等指标来评估模型的性能。这些指标可以直观地反映出模型预测的正确程度。
- 聚类算法:由于没有类别标签,评估聚类效果就比较复杂了。常用的评估指标有轮廓系数、戴维森堡丁指数等,它们从簇内紧凑度和簇间分离度等方面来衡量聚类的质量🤔。
🎯聚类算法的典型应用场景
-
用户分群分析:电商平台根据消费行为自动划分用户群体,实现精准营销
👥 示例:高价值客户、低频客户、折扣敏感型客户... -
图像压缩与分割:通过聚类减少图像颜色数量(压缩),或分割图像不同区域
🖼️ 如图像压缩前后对比
-
异常检测:在金融领域检测异常交易,网络安全中识别入侵行为
🚨 原理:异常点通常不属于任何密集簇 -
生物信息学:分析基因表达数据,发现功能相似的基因簇
🧬 应用:癌症亚型识别、药物反应预测 -
自然语言处理:新闻自动分组、话题发现、文档聚类
📰 如每日新闻自动归类到“体育”、“财经”、“科技”等板块
📌总结
聚类算法是机器学习中一种非常有用的无监督学习算法,它能够帮助我们从大量的数据中发现隐藏的模式和结构。和分类算法相比,它们在目标、数据要求和评估方式等方面都有明显的区别。在实际应用中,我们可以根据具体的问题和需求,选择合适的算法来解决问题😎。
聚类算法VS分类算法:
| 特性 | 聚类算法 | 分类算法 |
|---|---|---|
| 学习类型 | 无监督学习 | 有监督学习 |
| 标签需求 | 不需要标签 | 需要已标记数据 |
| 目标 | 发现隐藏分组结构 | 预测新样本的类别 |
| 过程 | 先有数据,后产生分组 | 先定义类别,后分配数据 |
| 结果确定性 | 分组结果可能不唯一 | 类别定义明确唯一 |
| 典型算法 | K-Means, DBSCAN | 决策树, SVM, 逻辑回归 |
希望今天的分享能让大家对聚类算法有一个初步的了解。如果你对机器学习感兴趣,不妨自己动手实践一下聚类算法,相信你会有更深刻的体会💪!
以上就是今天的博客内容啦,如果你觉得有用,别忘了点赞👍、收藏🌟、转发📤哦!咱们下次再见👋!
拓展阅读:
1、一招搞定分类问题!决策树算法原理与实战详解(附Python代码)


















 91
91

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











