







 本文详细介绍了强化学习(RL)的难点和方法,重点探讨了策略梯度(policy-based approach)的三大步骤,包括神经网络作为行为者、函数优劣度量以及选取最佳函数。还讲解了PPO(策略梯度的进阶版)的概念,如on-policy与off-policy的区别。此外,文章还涉及了值基方法(value-based approach)和actor-critic方法,如Q-learning和A2C算法,讨论了连续动作问题及解决方案。
本文详细介绍了强化学习(RL)的难点和方法,重点探讨了策略梯度(policy-based approach)的三大步骤,包括神经网络作为行为者、函数优劣度量以及选取最佳函数。还讲解了PPO(策略梯度的进阶版)的概念,如on-policy与off-policy的区别。此外,文章还涉及了值基方法(value-based approach)和actor-critic方法,如Q-learning和A2C算法,讨论了连续动作问题及解决方案。
十四.Reinforement learning
一.概述
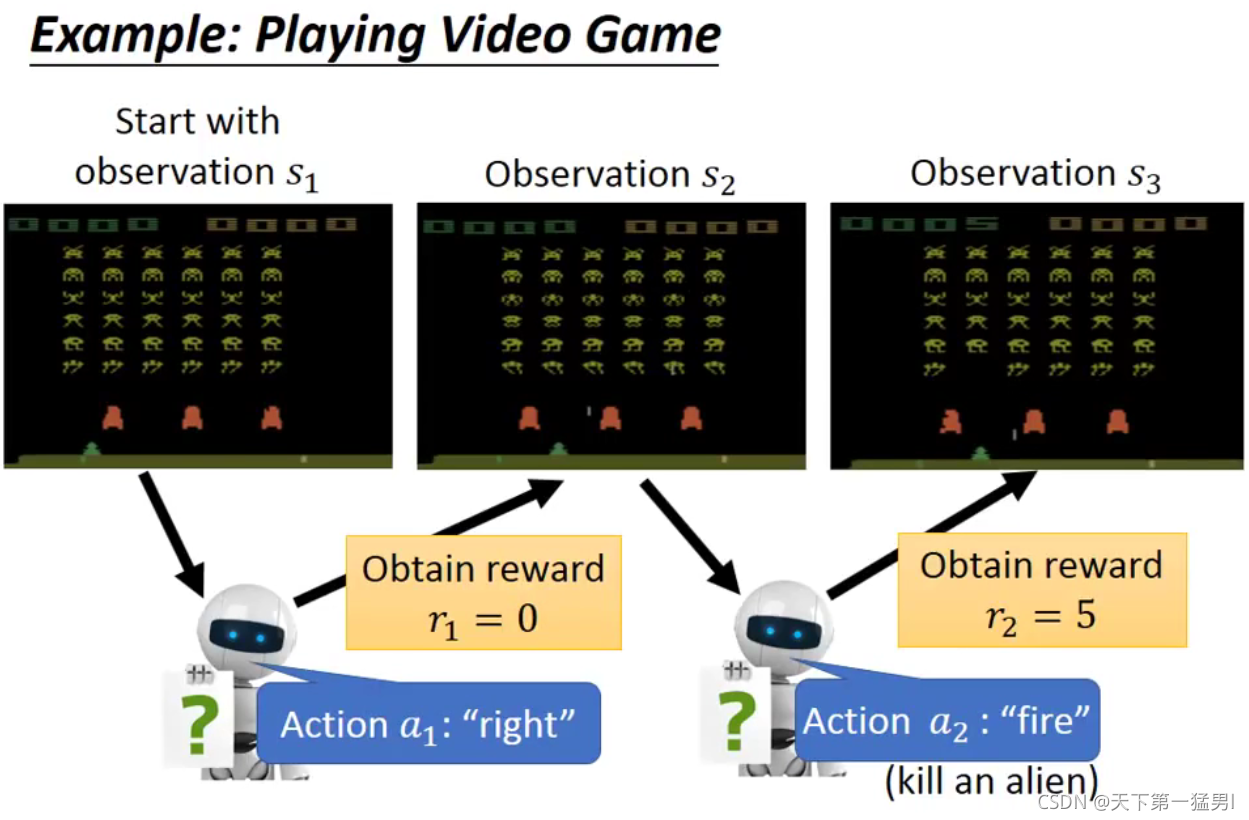
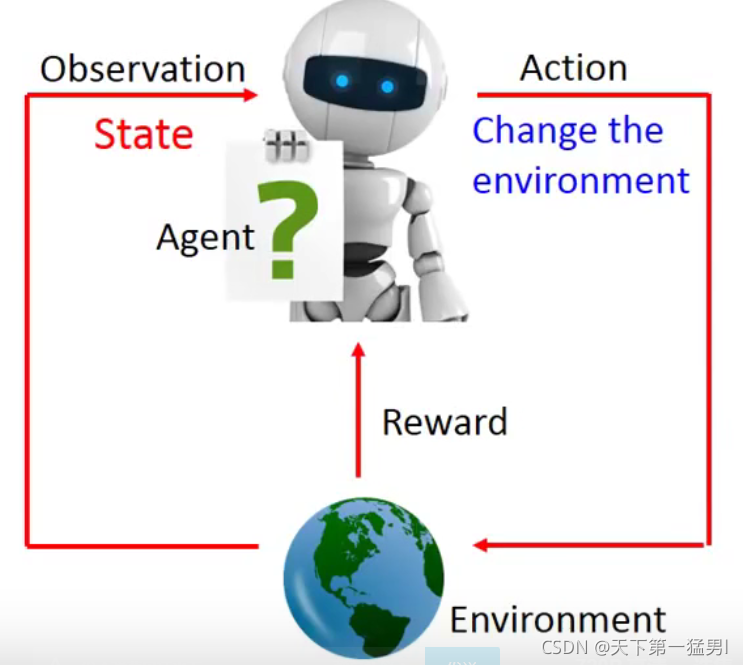
1.RL存在的困难
- 延迟奖励:虽然“向左”、“向右”移动无法得到奖励,但是有助于获得更大的奖励;
- agent采取的行为会影响它看到的东西,要会探索这个世界;
2.方法
- policy-based approach(learning an actor)
- value-based approach(learning a critic)
- actor+critic (A3C)
二.policy-based approach
1.梗概
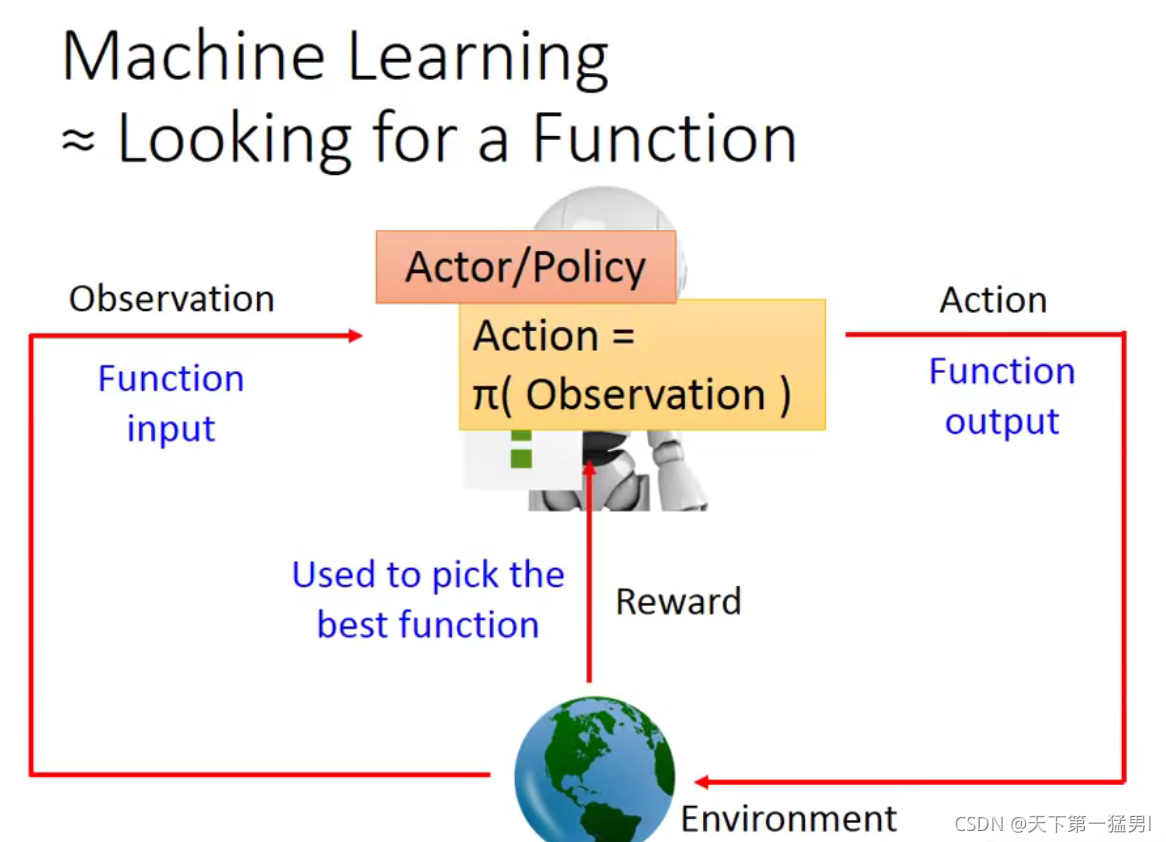
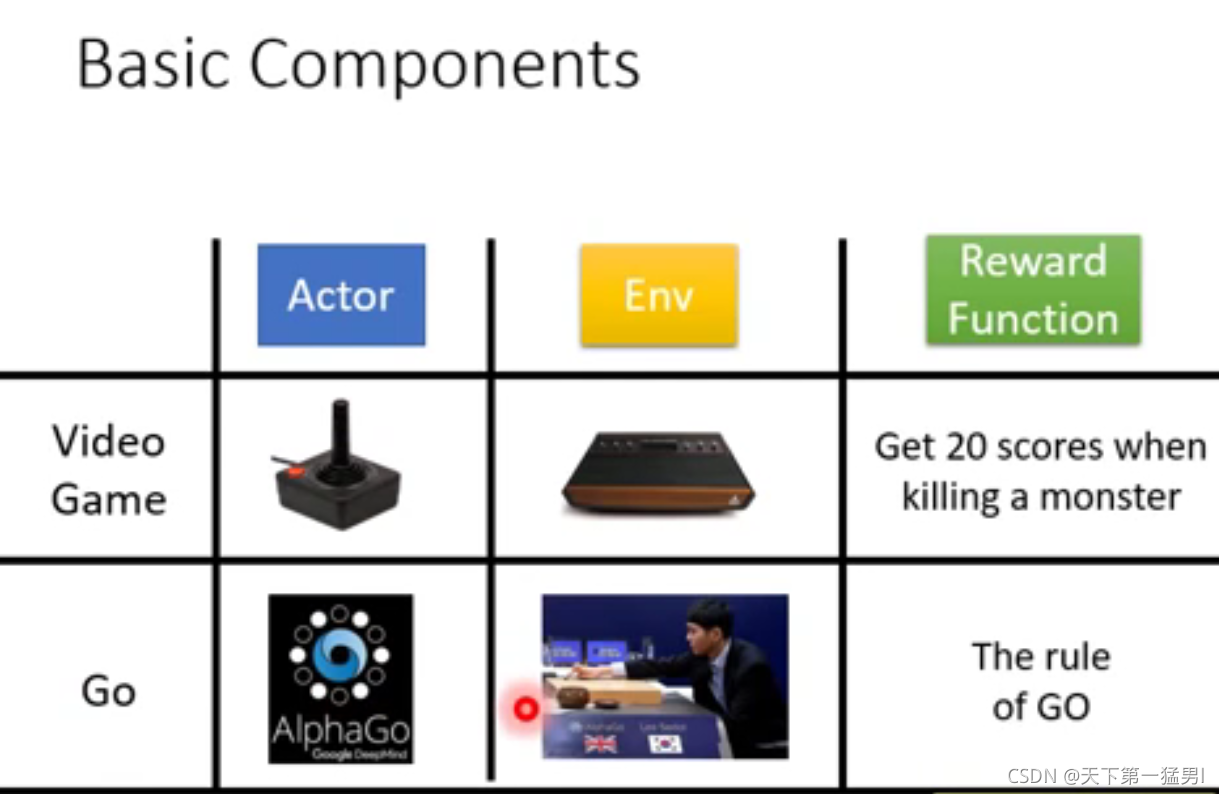
2. 3大步骤
2.1 step1:neural network as actor
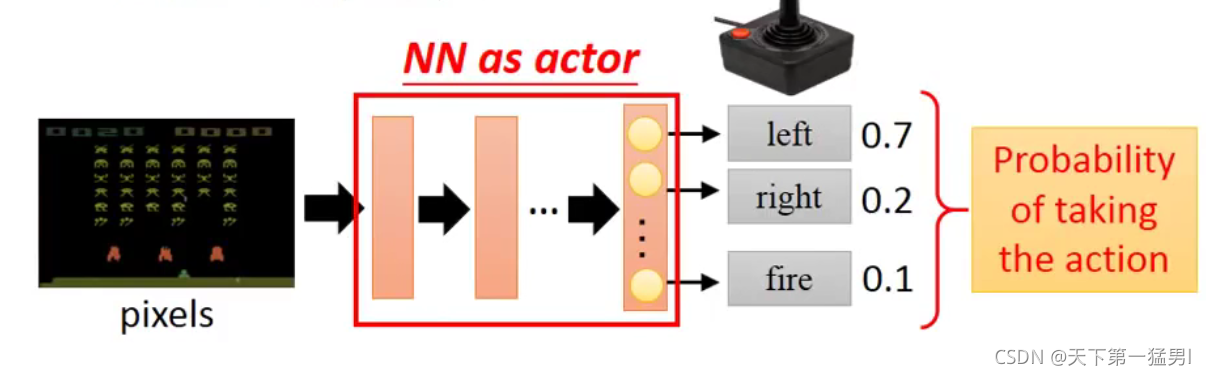
输入:observation;输出:action的分布
2.2 step2:goodness of a function
假设让actor(定义为: π θ ( s ) \pi_\theta(s) πθ(s))玩一场游戏(episode)从开始到结束有这样一个轨迹(trajectory):
τ = { s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , … , s T , a T , r T } \tau=\{ s_1,a_1,r_1,s_2,a_2,r_2,\dots,s_T,a_T,r_T\} τ={
s1,a1,r1,s2,a2,r2,…,sT,aT,rT};
R θ = ∑ t = 1 T r t R_\theta=\sum_{t=1}^{T}r_t Rθ=∑t=1Trt;
由于actor和游戏具有随机性,故 R θ R_\theta Rθ是一个随机变量,故转而求它的期望值( R ˉ θ \bar{R}_\theta Rˉθ)的最大值;
期望: R ˉ θ = ∑ τ R ( τ ) p ( τ ∣ θ ) \bar{R}_\theta=\sum_{\tau}R(\tau)p(\tau \vert \theta) Rˉθ=∑τR(τ)p(τ∣θ);
抽样 { τ 1 , τ 2 , … , τ N } \{\tau^1,\tau^2,\dots,\tau^N\} {
τ1,τ2,…,τN}估计总体:
即: R ˉ θ ≈ 1 N ∑ n = 1 N R ( τ n ) \bar{R}_\theta \approx \frac{1}{N} \sum_{n=1}^{N}R(\tau^n) Rˉθ≈N1∑n=1NR(τn)
2.3 step3:pick the best function
1.目标函数: θ ∗ = arg max θ R ˉ θ \theta^*=\argmax_{\theta}\bar{R}_{\theta} θ∗=θargmaxRˉθ
2.梯度上升法(policy gradient): θ n e w ← θ o l d + η ▽ R ˉ θ \theta^{new} \leftarrow \theta^{old}+\eta\triangledown \bar{R}_\theta θnew←θold+η▽Rˉθ
3.推导过程
R ˉ θ = ∑ τ R ( τ ) p ( τ ∣ θ ) ▽ R ˉ θ = ∑ τ R ( τ ) ▽ p ( τ ∣ θ ) = ∑ τ R ( τ ) p ( τ ∣ θ ) ▽ p ( τ ∣ θ ) p ( τ ∣ θ ) = ∑ τ R ( τ ) p ( τ ∣ θ ) ▽ log p ( τ ∣ θ ) ≈ 1 N ∑ n = 1 N R ( τ n ) ▽ log p ( τ n ∣ θ ) τ = { s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , … , s T , a T , r T } p ( τ ∣ θ ) = p ( s 1 ) p ( a 1 ∣ s 1 , θ ) p ( r 1 , s 2 ∣ s 1 , a 1 ) p ( a 2 ∣ s 2 , θ ) p ( r 2 , s 3 ∣ s 2 , a 2 ) … = p ( s 1 ) ∏ t = 1 T p ( a t ∣ s t , θ ) p ( r t , s t + 1 ∣ s t , a t ) ▽ R ˉ θ ≈ 1 N ∑ n = 1 N ∑ t = 1 T n R ( τ n ) ▽ log p ( a t n ∣ s t n , θ ) \begin{aligned}\bar{R}_\theta &=\sum_{\tau}R(\tau)p(\tau \vert \theta) \\ \triangledown \bar{R}_\theta &= \sum_{\tau}R(\tau)\triangledown{p(\tau \vert \theta)} \\ & =\sum_{\tau}R(\tau)p(\tau \vert \theta)\frac{\triangledown{p(\tau \vert \theta)}}{p(\tau \vert \theta)} \\ & =\sum_{\tau}R(\tau)p(\tau \vert \theta) \triangledown{\log p(\tau \vert \theta) } \\ & \approx \frac{1}{N}\sum_{n=1}^{N}R(\tau^n)\triangledown{\log p(\tau^n \vert \theta) } \\ \tau &=\{ s_1,a_1,r_1,s_2,a_2,r_2,\dots,s_T,a_T,r_T\} \\p(\tau \vert \theta) &=p(s_1)p(a_1 \vert s_1,\theta)p(r_1,s_2 \vert s_1,a_1)p(a_2 \vert s_2,\theta)p(r_2,s_3 \vert s_2,a_2) \dots \\ &=p(s_1)\prod_{t=1}^{T}p(a_t\vert s_t,\theta)p(r_t,s_{t+1} \vert s_t,a_t) \\ \triangledown \bar{R}_\theta & \approx \frac{1}{N}\sum_{n=1}^{N}\sum_{t=1}^{T_n}R(\tau^n) \triangledown \log p(a_t^n \vert s_t^n,\theta)\end{aligned} Rˉθ▽Rˉθτp(τ∣θ)▽Rˉθ=τ∑R(τ)p(τ∣θ)=τ∑R(τ)▽p(τ∣θ)=τ∑R(τ)p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









