



 文章探讨了深度强化学习中的Policy-based方法,特别是将神经网络作为Actor来决定行动。强调了网络的泛化能力以及在强化学习中处理奖励延迟的问题。此外,文章还讨论了模型压缩技术,如网络修剪,以及如何通过微调恢复精度。
文章探讨了深度强化学习中的Policy-based方法,特别是将神经网络作为Actor来决定行动。强调了网络的泛化能力以及在强化学习中处理奖励延迟的问题。此外,文章还讨论了模型压缩技术,如网络修剪,以及如何通过微调恢复精度。
文章目录
一、deep reinforcement learning
强化学习场景
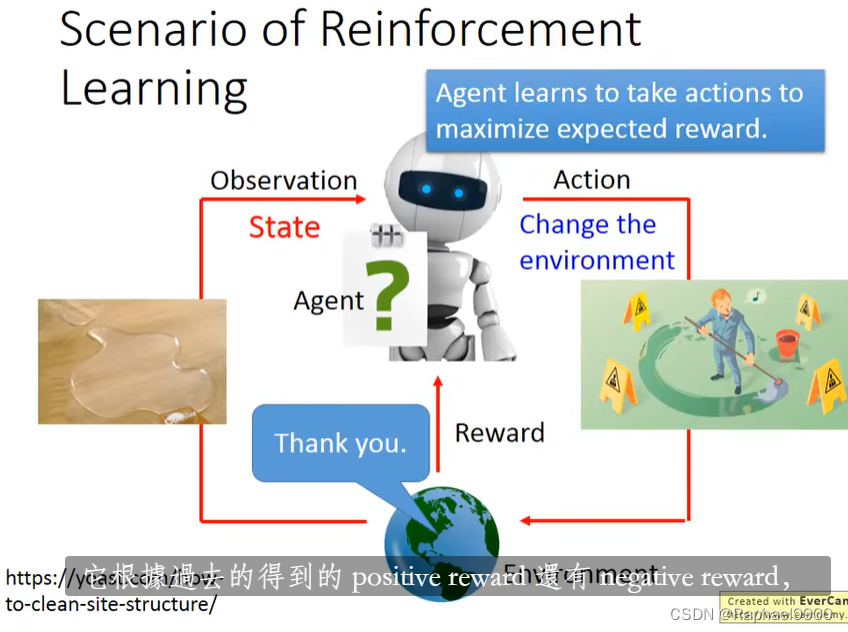

监督学习和强化学习之间:

训练一个聊天机器人-强化学习:让两个代理相互交谈(有时产生好的对话,有时产生坏的对话)
通过这种方法,我们可以产生很多对话。使用一些预定义的规则来评估对话的好坏

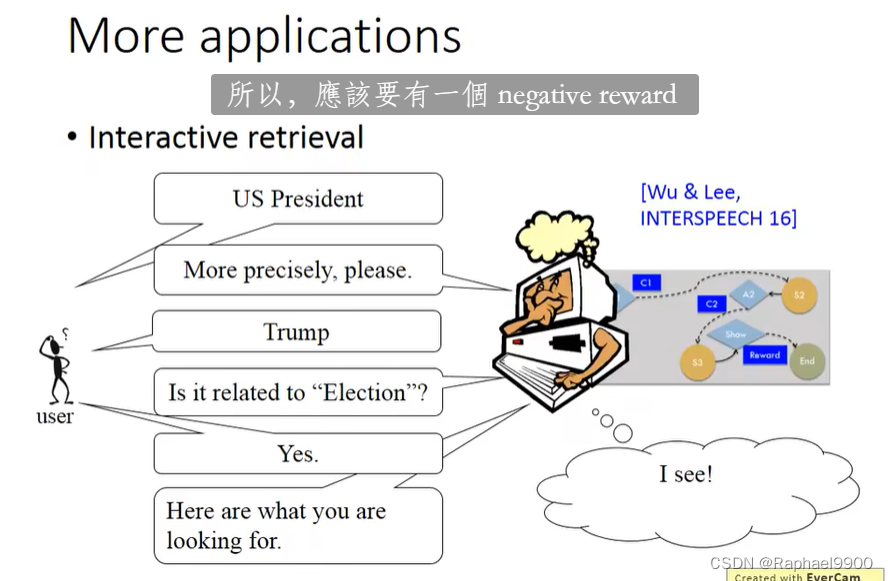
交互式检索

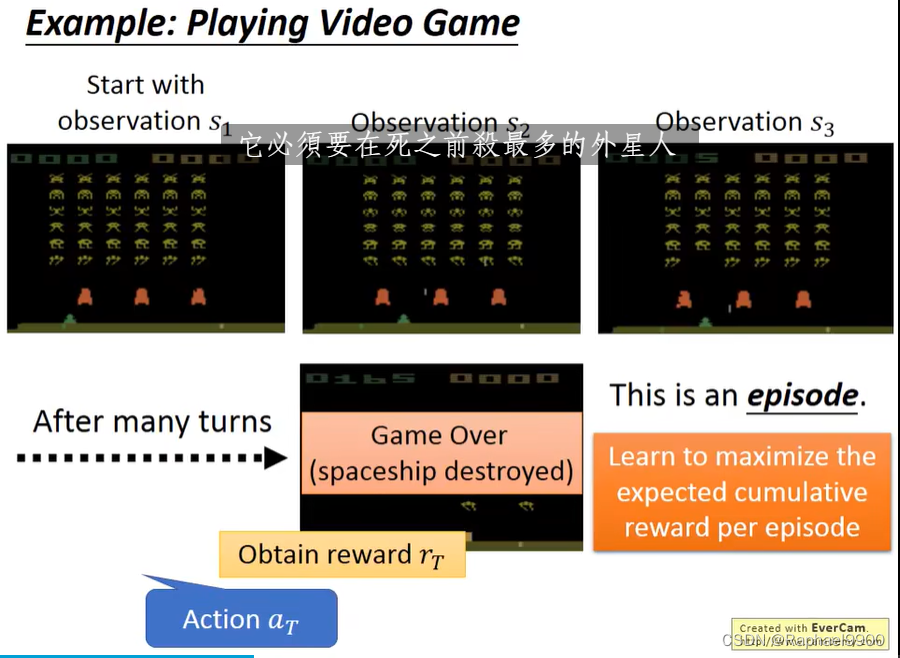
奖励延迟:在《太空入侵者》中,只有“开火”获得奖励,虽然“着火”前的移动很重要。在围棋比赛中,牺牲即时奖励以获得更多长期奖励可能更好。代理的行为会影响其收到的后续数据。
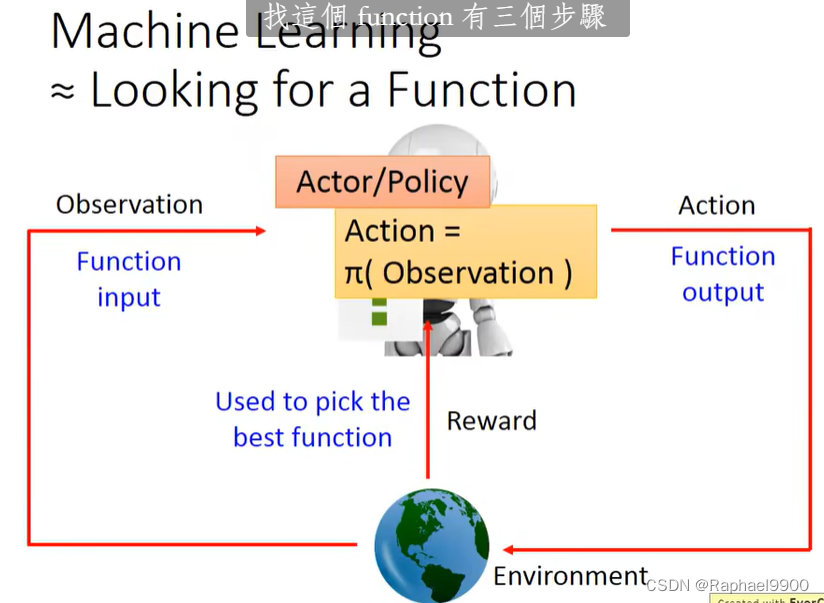
深度强化学习可以分为:Policy-based和Value-based。
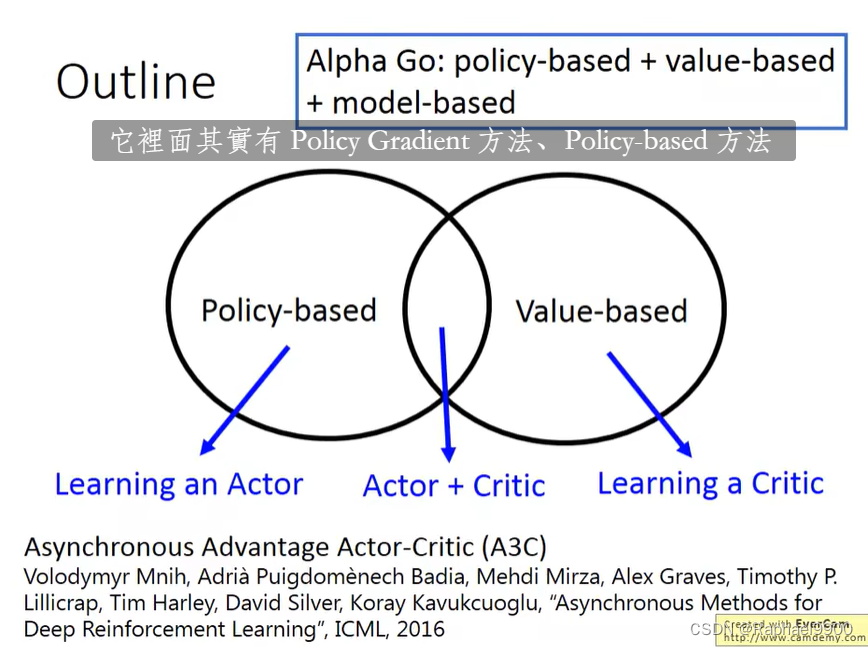

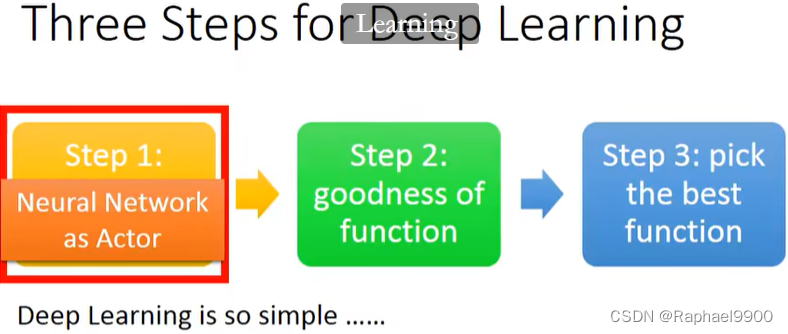
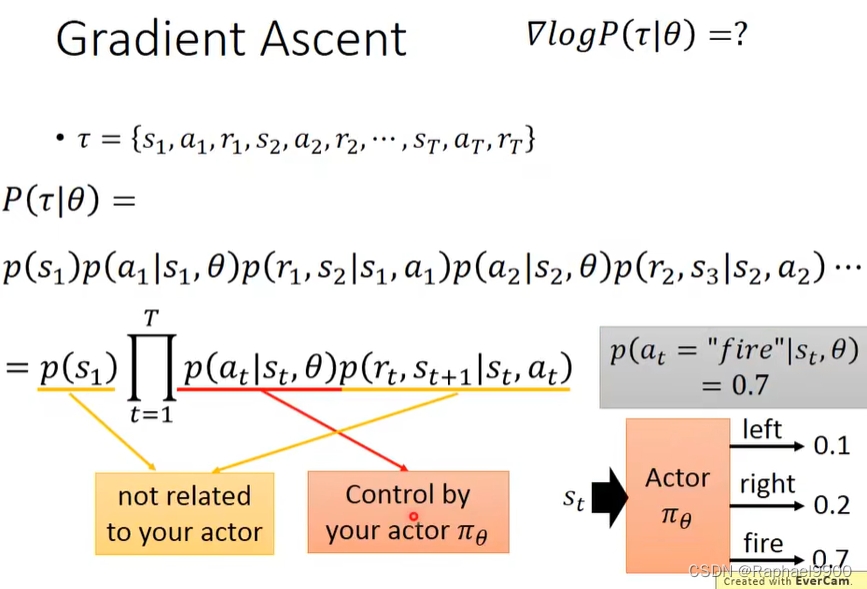
Policy-based Approach——Learning an Actor
作为actor的神经网络
神经网络的输入:用向量或矩阵表示的机器的观测值
输出神经网络:每个动作对应输出层的一个神经元
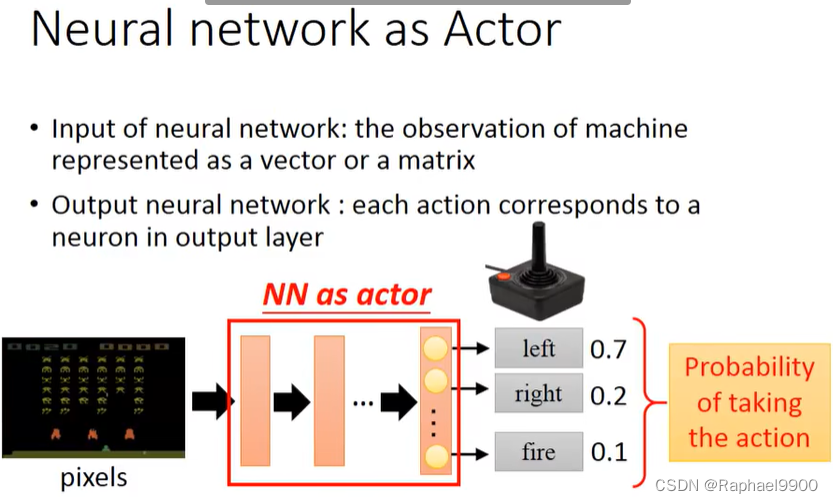
其实动作是随机的,不固定。不是说数字大就一定是这个动作。
用网络代替查找表有什么好处?generalization!没有看过的东西也会得到好的结果。





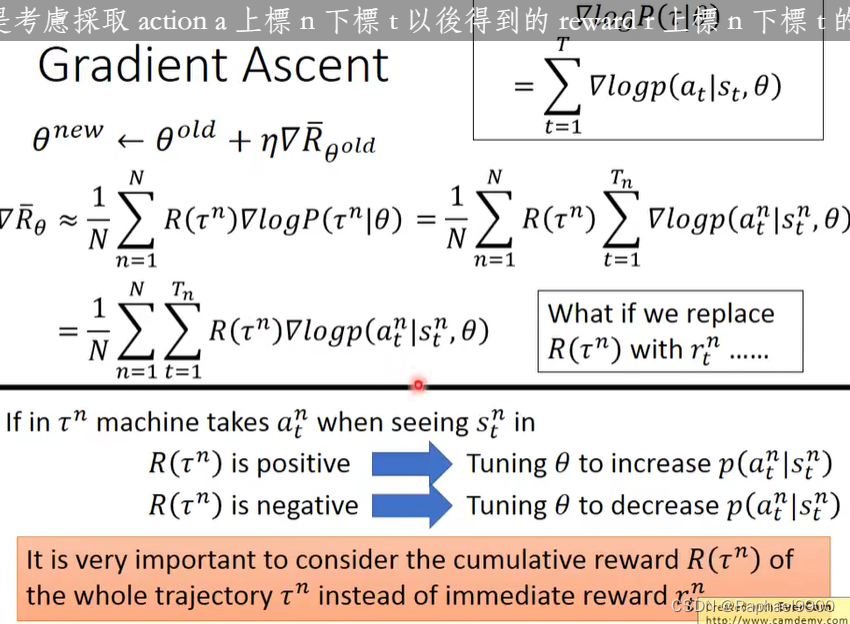
这个要注意是乘上本次τ的所有reward,不是乘一个r。因为我们希望动作跟很多结果一样。

除以一个p更好,做了标准化,不希望出现更偏向次数多的而分数低情况。
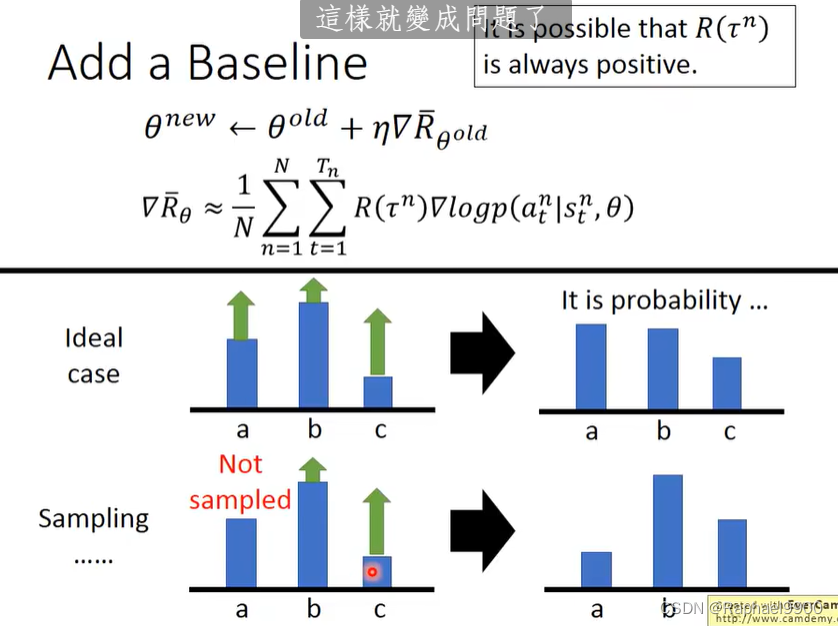
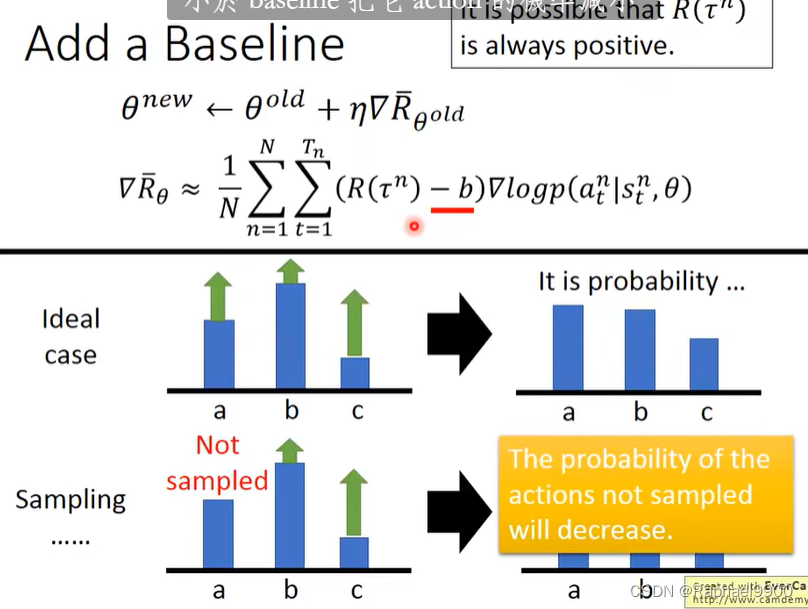
未被采样的动作的概率将会降低,那怎么解决呢?就减去一个bias,让概率有正有负。
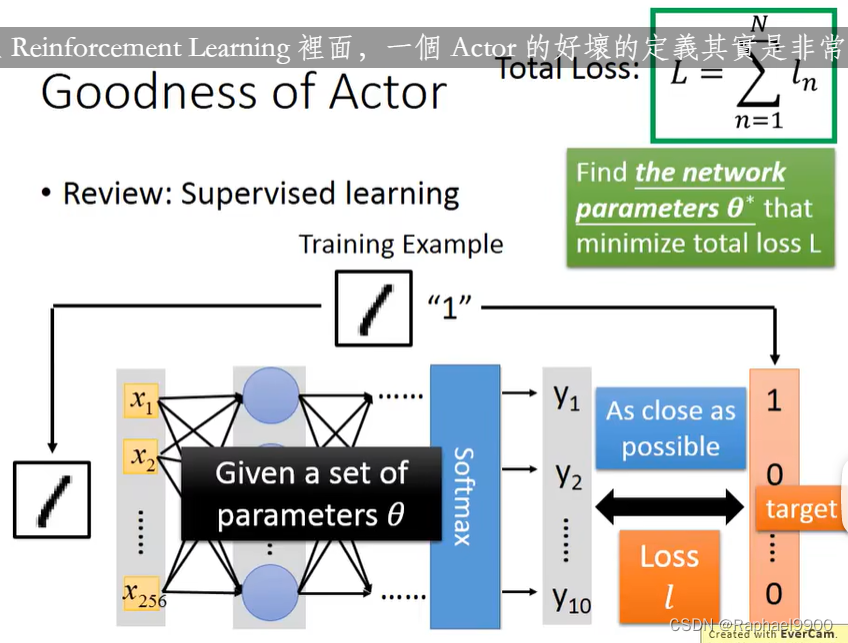
评论家是一个依赖于被评价的演员的函数,该函数由神经网络表示。状态值函数Vπ(s):当使用行动者π时,期望在看到观察(状态)s后获得累积奖励。


small model
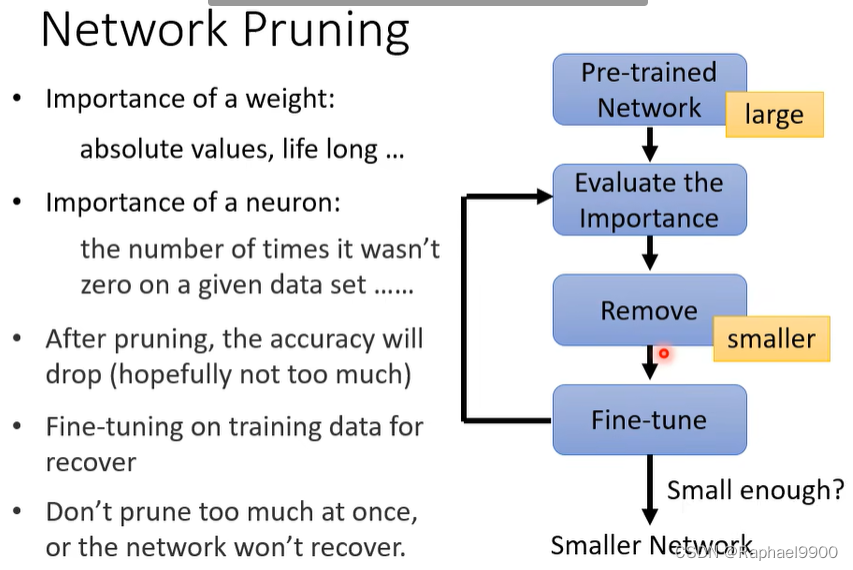
模型压缩

网络可以被修剪
网络通常是过度参数化的(有大量冗余的权重或神经元),我们可以修剪它们!
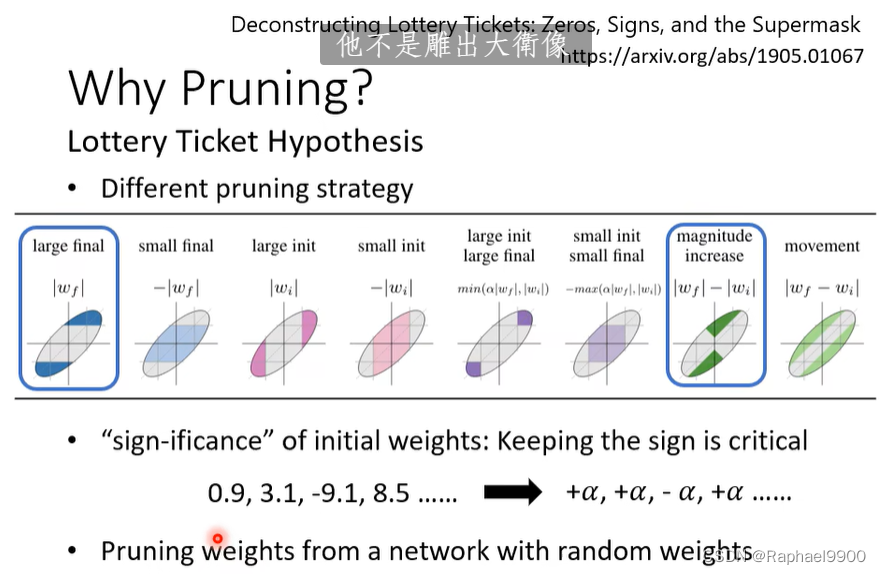
权重的重要性:绝对值,终身…
一个神经元的重要性:在一个给定的数据集上它不为零的次数…
修剪后,精确度会下降(希望不会下降太多)
针对recover的训练数据进行微调,不要一次修剪太多,否则网络无法恢复。
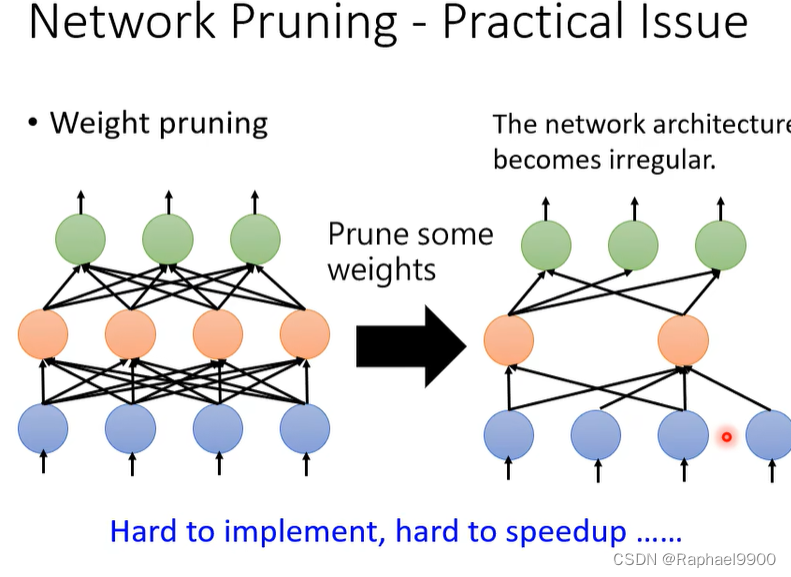
实际上不规则的网络不好用GPU加速,也不一定是加速了
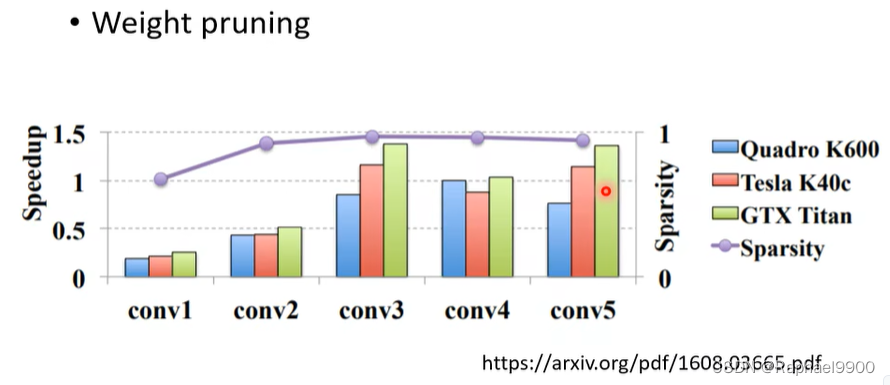
去掉神经元之后,网络是规则的,就可以加速了
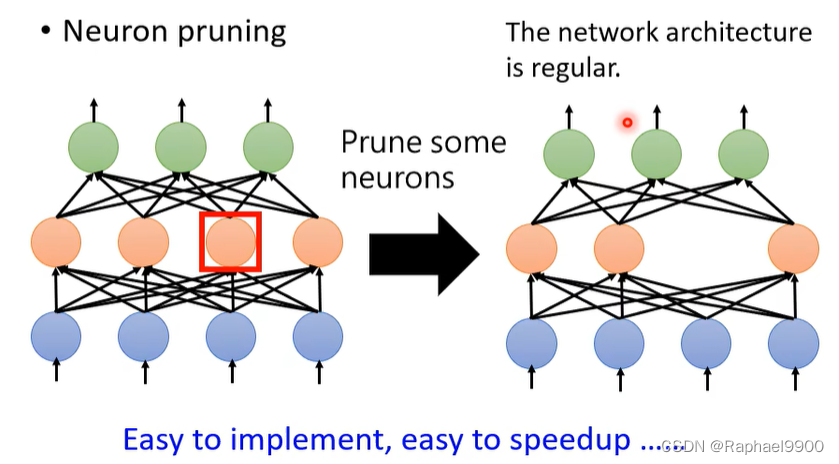
简单地训练一个更小的网络怎么样?众所周知,越小的网络越难成功学习。。更大的网络更容易优化?

只要把子网络训练好,大的也能训练好
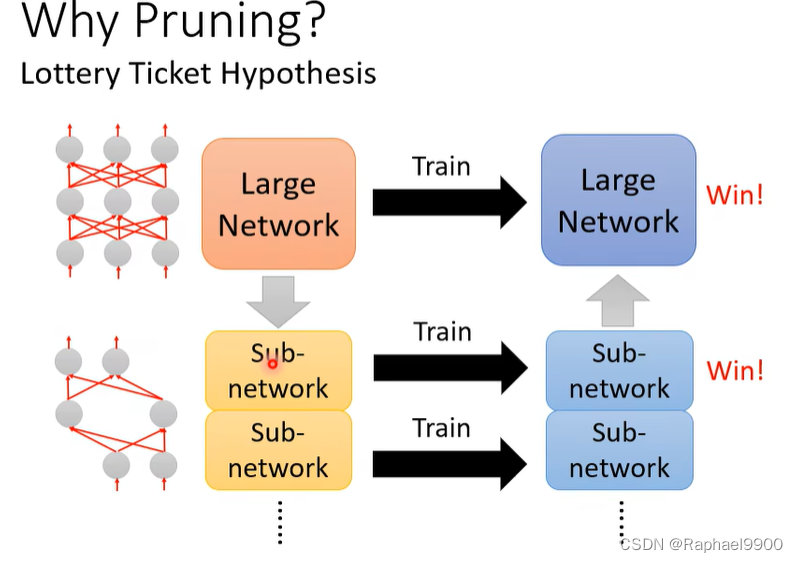
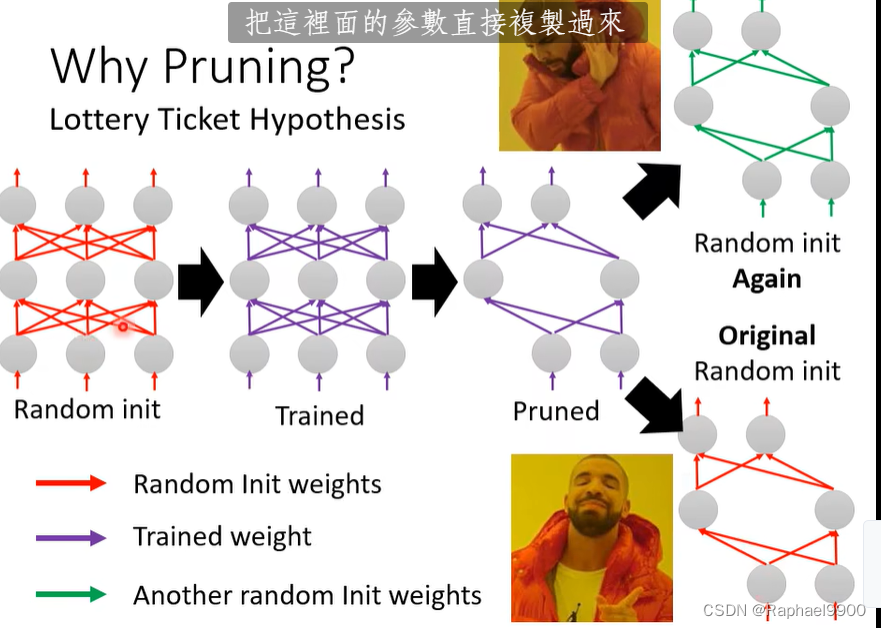
直接训练小的网络无法训练,用大的网络进行修剪小了之后就能训练起来。


















 1284
1284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









