




0.简介
这段时间YOLO系列算法很火,尤其是YOLOv3,很多大牛都复现了其在各种平台下的实现(tensorflow,pytorch,caffe…)。主要还是因为YOLOv3算法结合了很多有用的trick,兼顾了速度和精度。但究其本质仍然是回归算法,所以我们在这里先详细介绍下YOLOv1的实现细节,好了解回归算法的特性。网上有很多教程,但质量参差不齐,而且本人阅读起来很多细节比较难理解。因此还是打算总结一下,加深印象。后续还会写v2和v3的实现细节。我们主要分为三部分来介绍,算法整体结构+算法前向计算+算法训练过程。总体来说,YOLOv1算法的特点为算法结构简单,但具体实现细节比较多。
1.YOLO算法结构图
YOLO是利用一个简单的回归网络实现目标检测分类算法。直接放一张图来说明YOLO算法结构之简单。下图不是YOLO论文中的原始结构,而是用一个24层的网络替代了论文中原作者用的GoogleNet作为YOLO检测算法的特征提取器(我们可以用任意的分类网络替代,比如MobileNet,SqueezeNet,ShuffleNet等)。
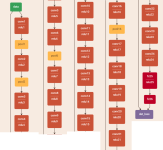
那么有人会问这么简单的网络是怎么实现目标检测和分类的呢?其所有的秘密就在如下所示的相对复杂的损失函数中(所以损失函数才是深度学习任务的核心嘛,我一直这么认为)。详细细节我们下面展开讨论。(下述代码为网络最后一层的输出层,和损失函数层)
layer {
name: "reg_reshape"
type: "Reshape"
bottom: "conv_reg"
top: "regression"
reshape_param {
axis: 1
shape {
dim: 1470
}
}
}
layer {
name: "det_loss"
type: "DetectionLoss"
bottom: "result"
bottom: "label"
top: "det_loss"
loss_weight: 1
detection_loss_param {
side: 7
num_class: 20
num_object: 2
object_scale: 1.0
noobject_scale: 0.5
class_scale: 1.0
coord_scale: 5.0
sqrt: true
constriant: true
}
}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1452
1452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











