




 本文详细介绍了深度学习中常用的激活函数,包括sigmoid、softmax、ReLU、Leaky ReLU、ELU和tanh。探讨了它们的特点、应用场景及优缺点,如ReLU的稀疏性和加速收敛特性,Leaky ReLU解决的神经元死区问题,以及ELU的平滑性质。
本文详细介绍了深度学习中常用的激活函数,包括sigmoid、softmax、ReLU、Leaky ReLU、ELU和tanh。探讨了它们的特点、应用场景及优缺点,如ReLU的稀疏性和加速收敛特性,Leaky ReLU解决的神经元死区问题,以及ELU的平滑性质。
一般在图像的目标检测,图像分类中,用到损失函数是交叉熵。
一、sigmoid
用作二分类,在特征相差比较复杂或是相差不是特别大时效果比较好。
二、softmax
用作多分类。“soft”在于连续可微。比起sigmoid,数值稳定。所有值得和为1,那么就会此消彼涨,有相互抑制的效果
softmax(z)i=exp(zi)/Σjexp(zj)softmax(z)_i=exp(z_i)/\Sigma _jexp(z_j)softmax(z)i=exp(zi)/Σjexp(zj)
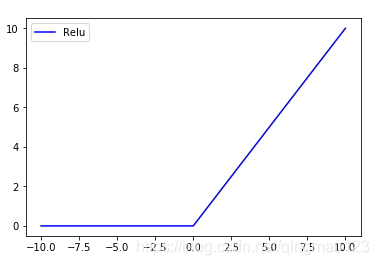
三、relu
有单侧抑制的作用,通过ReLU实现稀疏后的模型能够更好地挖掘相关特征,拟合训练数据,加速收敛。
f(x)=max(0,x)f(x)=max(0,x)f(x)=max(0,x)
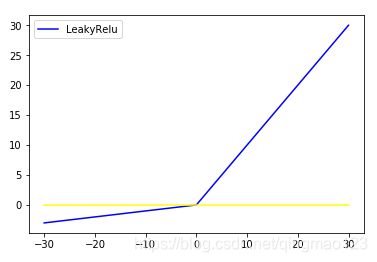
四、leaky relu
为了解决relu容易让神经元不被激活的问题。保留了一些负轴的值,使得负轴的信息不会全部丢失。
f(x)=max(0,x)+leak∗min(0,x)f(x)=max(0,x)+leak*min(0,x)f(x)=max(0,x)+leak∗min(0,x)
leak要设置得小一点。
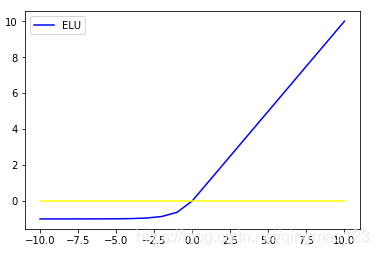
五、ELU
f(x)={α∗(expx−1),x<0x,x>=0f(x)=\lbrace^{x,x>=0}_{α*(exp^x-1),x<0}f(x)={α∗(expx−1),x<0x,x>=0
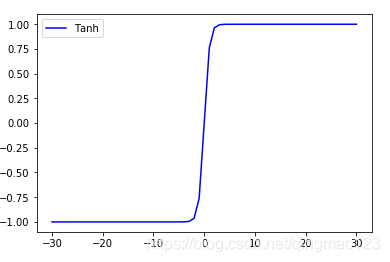
六、tanh
sigmoid不是原点对称的。tanh原点对称。计算形式更复杂:
tanh(x)=(expx−exp−x)/(expx+exp−x)tanh(x)=(exp^x-exp^{-x})/(exp^x+exp^{-x})tanh(x)=(expx−exp−x)/(expx+exp−x)

















 1986
1986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









