




代码地址
https://github.com/memmelma/VO-Transformer/tree/dev
环境配置
1.拉取github库
git clone https://github.com/memmelma/VO-Transformer.git
cd VO-Transformer/
2.创建环境
创建environment.yml
name: vot_nav
channels:
- pytorch
- conda-forge
dependencies:
- python=3.7
- cmake=3.14.0
- numpy
- numba
- tqdm
- tbb
- joblib
- h5py
- pytorch=1.10.0
- torchvision=0.8.0
- cudatoolkit=11.0
- pip
- pip:
- yacs
- lz4
- opencv-python
- future
- numba
- numpy
- tqdm
- tbb
- joblib
- h5py
- opencv-python
- lz4
- yacs
- wandb
- tensorboard==1.15
- ifcfg
- jupyter
- gpustat
- moviepy
- imageio
- einops
conda env create -f environment.yml
conda activate vot_nav
3.安装habitat-sim
conda install -c aihabitat -c conda-forge habitat-sim=0.1.7 headless
4.安装habitat-lab
git clone https://github.com/facebookresearch/habitat-lab.git -b v0.1.7
cd habitat-lab/
pip install -r requirements.txt
python setup.py develop --all
5.Install timm and other
cd ..
git clone https://github.com/rwightman/pytorch-image-models.git -b v0.6.12
cd pytorch-image-models
pip install -e .
pip install protobuf==3.20
6.配置数据集和模型
直接参考原本github库
生成数据
./generate_data.sh --act_type -1 --N_list 250000 25000 --name_list 'train' 'val'
一个漫长的过程…
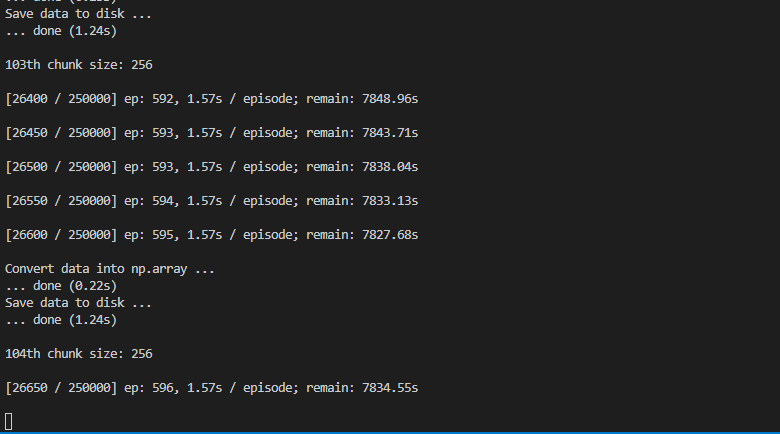
6.运行训练的
训练之前改一下configs/rl/evaluation/example_rl.yaml的batch_size,太大了跑不动,把N_GPU也改一下
./start_vo.sh --config-yaml configs/vo/example_vo.yaml
7.运行eval脚本
./start_rl.sh --run-type eval --config-yaml configs/rl/evaluation/example_rl.yaml
Docker学习
docker 简单回顾
构建镜像(vot_dk是构建的镜像的名称,这是通过dockerfile的形式进行的构建)
docker build -t vot_dk .
创建容器(这样创建的容器可以指定name, mycontainer 是给自己的容器取得名字)
最开始运行一次就行了,镜像可以多次使用,容器建议一直用一个
docker run -it --name mycontainer 镜像名称 /bin/bash
docker文件映射
docker run -v /宿主机路径:/容器路径 -it --name mycontainer 镜像名称 /bin/bash
我常用的一条创建容器指令(这里的容器中的code就和主机关系起来了)
docker run -v ./docker_data:/home/masteruser/code -it --name ql vot_dk /bin/bash
启动容器
docker start -ai mycontainer
删除容器
docker rm mycontainer
查看镜像
docker images
查看容器,没有-a则只查看处于运行状态的docker
docker pa -a
在Vscode中使用docker
在VSCODE中使用docker,可以直接修改文件的那种
连接进入后,先输bash才能进入终端

这里的(base)也只有
conda init
source ~/.bashrc
之后才会出现
要想在vscode中编译文件,还需要进行权限赋值
文件及文件夹赋权限
sudo chmod -R 777 /path/to/directory
sudo chmod 777 /home/masteruser/data/test.py
如果~被vscode强行更改了
export HOME=/home/ql
可以暂时解决
Docker可视化
参考https://blog.youkuaiyun.com/qq_42731705/article/details/130798908
在创建容器时加上
--env="DISPLAY=$DISPLAY" --net=host --volume="$HOME/.Xauthority:/root/.Xauthority:rw" --env="QT_X11_NO_MITSHM=1" -v /tmp/.X11-unix:/tmp/.X11-unix:ro
例如
docker run --env="DISPLAY=$DISPLAY" --net=host --volume="$HOME/.Xauthority:/root/.Xauthority:rw" --env="QT_X11_NO_MITSHM=1" -v /tmp/.X11-unix:/tmp/.X11-unix:ro -it -v ./docker_data:/home/masteruser/code --name ql_vis vot_dk /bin/bash
使用GPU
--gpus all
设置共享内存
默认生成的docker的共享内存很小,要通过这样的方式设置docker的共享内存
--shm-size=20g
查看共享内存
df -h /dev/shm
使用docker进行配置
1.只保留原Dockerfile的这部分
FROM nvidia/cudagl:11.0-base-ubuntu18.04
LABEL maintainer "Memmel Marius <marius.memmel@epfl.ch>"
USER root
# fix https://github.com/NVIDIA/nvidia-docker/issues/1632
RUN rm /etc/apt/sources.list.d/cuda.list
RUN rm /etc/apt/sources.list.d/nvidia-ml.list
# Setup basic packages
RUN apt-get update && \
apt-get install -y --no-install-recommends \
build-essential \
git \
curl \
vim \
locales \
htop \
ca-certificates \
libjpeg-dev \
libpng-dev \
libglfw3-dev \
libglm-dev \
libx11-dev \
libomp-dev \
libegl1-mesa-dev \
pkg-config \
wget \
zip \
sudo \
net-tools \
cmake \
vim \
locales \
wget \
git \
nano \
screen \
gcc \
python3-dev \
bzip2 \
libx11-6 \
libssl-dev \
libffi-dev \
parallel \
tmux \
g++ \
unzip &&\
sudo rm -rf /var/lib/apt/lists/*
ENV user masteruser
RUN useradd -m -d /home/${user} ${user} && \
chown -R ${user} /home/${user} && \
adduser ${user} sudo && \
echo '%sudo ALL=(ALL) NOPASSWD:ALL' >> /etc/sudoers
ENV HOME=/home/$user
USER masteruser
WORKDIR /home/masteruser
# Create conda environment
RUN curl -Lso ~/miniconda.sh https://repo.anaconda.com/miniconda/Miniconda3-py37_4.11.0-Linux-x86_64.sh \
&& chmod +x ~/miniconda.sh \
&& ~/miniconda.sh -b -p ~/miniconda \
&& rm ~/miniconda.sh
ENV PATH=$HOME/miniconda/bin:$PATH
ENV CONDA_AUTO_UPDATE_CONDA=false
RUN $HOME/miniconda/bin/conda create -y --name py37 python=3.7 \
&& $HOME/miniconda/bin/conda clean -ya
ENV CONDA_DEFAULT_ENV=py37
ENV CONDA_PREFIX=$HOME/miniconda/envs/$CONDA_DEFAULT_ENV
ENV PATH=$CONDA_PREFIX/bin:$PATH
RUN $HOME/miniconda/bin/conda clean -ya
2.使用dockerfile构建镜像
在dockerfile同级文件夹下运行
docker build -t vot_dk .
3.使用镜像创建容器
(这里为了训练配了20G动态内存,GPU内存报错那个不是这里的问题)
docker run --shm-size=20g -v ./docker_data:/home/masteruser/code --gpus all -it --name ql vot_dk /bin/bash
4.启动容器
docker start -ai ql
5.在docker中配置代理,便于后续下载
顺便切换一下pip 源
python -m pip config set global.index-url https://mirrors.aliyun.com/pypi/simple
6.构建install.sh
git clone https://github.com/facebookresearch/habitat-sim.git \
&& cd habitat-sim \
&& git checkout 020041d75eaf3c70378a9ed0774b5c67b9d3ce99 \
&& pip install -r requirements.txt \
&& python setup.py install --headless \
&& cd ..
git clone https://github.com/facebookresearch/habitat-lab.git \
&& cd habitat-lab \
&& git checkout d0db1b55be57abbacc5563dca2ca14654c545552 \
&& pip install -e . \
&& cd ..
# Install timm
git clone https://github.com/rwightman/pytorch-image-models.git -b v0.6.12\
&& cd pytorch-image-models \
&& pip install -e .
# Install pytorch
conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.0 -c pytorch
# Install other stuff
pip install future \
numba \
numpy \
tqdm \
tbb \
joblib \
h5py \
opencv-python \
lz4 \
yacs \
wandb \
tensorboard==1.15 \
ifcfg \
jupyter \
gpustat \
moviepy \
imageio \
einops \
protobuf==3.20
export GLOG_minloglevel=2
export MAGNUM_LOG="quiet"
export HOROVOD_GLOO_IFACE=em2
7.运行安装脚本,注意运行的conda环境
bash install.sh
8.后续操作就和环境配置中一致了



















 2467
2467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











