




自研时序大模型成果论文入选国际顶会,多场景预测性能实现突破。
之前,我们发布了时序数据库 IoTDB 团队自研的 Timer-XL 时序大模型,可以有效地为异常检测、数据填补、时序预测等时序数据场景提供解决方案。该模型已经内置在 IoTDB 的智能分析节点 AINode 中,用户能够非常方便地进行调用。
Timer-XL 时序大模型的论文成果:Timer-XL: Long-Context Transformers For Unified Time Series Forecasting(《Timer-XL:用于时间序列统一预测的长上下文 Transformer 模型》)已经被公认的深度学习领域国际顶级会议之一,ICLR 2025(The International Conference on Learning Representations,国际学习表征会议)收录,标志着 Timer-XL 模型在技术设计及预测效果上的领先性获得权威认可。
针对长上下文时序预测问题,本篇论文提出了时序注意力机制,基于 Decoder-Only Transformer 进行多维时序数据的下一词预测,通过对预测上下文的统一建模,在单变量、多变量以及协变量等任务中取得了性能提升,并进一步通过大规模预训练构建了 Timer-XL 时序大模型,在零样本预测中取得了更好效果。
ICLR 官网收录论文
01 | Timer-XL 的基础:Transformer 模型 |
02 | Transformer 的时序预测局限 |
03 | Timer-XL 优化:通用、灵活、可扩展 |
04 | Timer-XL 预测效果:多类场景领先 |
01
Timer-XL 的基础:Transformer 模型
Transformer 已成为自然语言、图像、视频等领域的基础模型。除了与日俱增的训练规模,基础模型的上下文长度也是重要能力指标。面向自然语言处理,它是上下文学习(ICL),检索增强生成(RAG),以及思维链(CoT)等涌现能力的基础;在视觉领域,长上下文模型能够支持更高分辨率、更长时间的生成任务。
针对时序预测设计的 Transformer 层出不穷,以往工作普遍关注长期未来预测,然而,可靠预测依赖于对历史序列的长期观测,以及对外生因素的充分捕捉。因此,提升模型的长上下文预测能力至关重要。
我们首先分析了 Transformer 的仅编码器(Encoder-Only)和仅解码器(Decoder-Only)架构在长上下文预测任务中的表现。
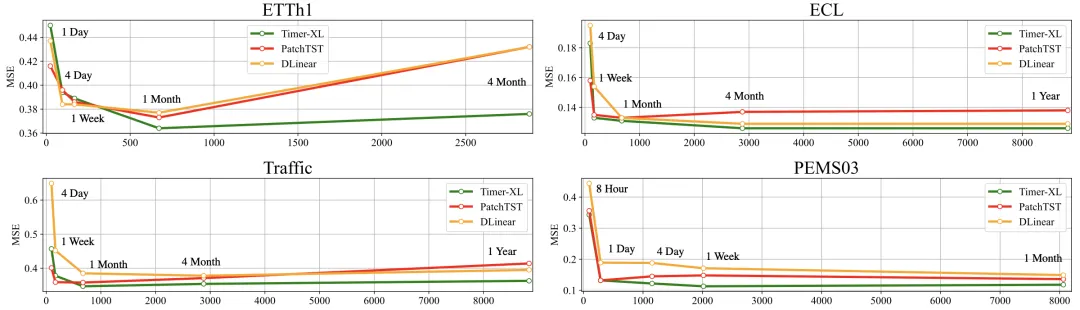
深度预测模型在长上下文任务中的预测误差:
PatchTST 对应 Encoder-Only Transformer,Timer-XL 对应 Decoder-Only Transformer
实验表明:Decoder-Only Transformer 能够更好地支持时序预测上下文长度的有效扩展。此外,基于该架构在处理不同序列长度时的上下文灵活性,我们有望突破以往“一事一议”的设计思路,构建一个支持多种预测场景的通用模型。
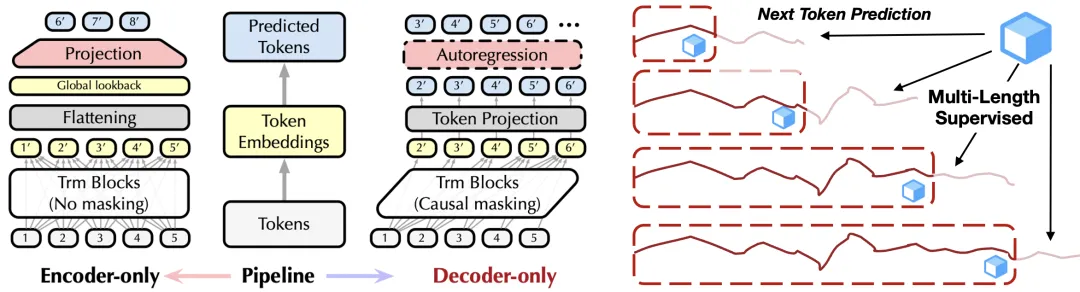
(左)架构对比;(右)下一词预测
受自然语言建模启发,我们将下一词预测任务扩展至多维时序数据;提出多维时序注意力机制(TimeAttention),在保证时序单元(Token)因果关系的同时捕捉跨序列(变量)的依赖关系;基于并行化的下一词预测监督信号,训练上下文(时序/变量)可变的预测模型。
效果方面,我们所提出的模型在单变量,多变量,带协变量的有监督预测任务中取得了性能提升;通过在 2600 亿时间点进行预训练,模型取得了领先的零样本预测效果。
02
Transformer 的时序预测局限
PatchTST 提出分块(Patch)时序单元,在捕捉长期时序变化时具备明显优势。为弥补通道独立(Channel Independence)对多变量关联的建模不足,iTransformer 将多变量时序数据的每个变量视作独立单元,在进行多维时序预测时效果优良。后续 TimeXer,UniTST 等模型从时序单元和注意力机制出发,能够同时进行序列内和序列间时序建模。
然而,上述工作主要聚焦长期时序预测。在长上下文预测任务中,我们发现:相比于广泛采用的 Encoder-Only 架构,维持因果性质的 Decoder-Only 架构在长上下预测中效果更好。然而,多维时间序列中同时存在序列内以及跨序列的时序依赖,依靠 Transformer 的原生掩码注意力机制难以进行有效建模。

面向时序数据设计的不同 Transformer 能力对比
Transformer 是否能有效建模时序数据一直是领域热点问题。一方面,单一的评测基准制约了模型创新;另一方面,在小规模数据上 XGBoost,MLP 等轻量模型往往能取得更加优异的效果,而 Transformer 等深度模型的数据需求和调优难度往往更大。
在此趋势下,最近研究旨在构建时序大模型:无需在特定任务上进行训练,预训练模型提供开箱即用的预测能力,如谷歌的 TimesFM,亚马逊的 Chronos 以及 Saleforce 的 Moirai 系列模型。
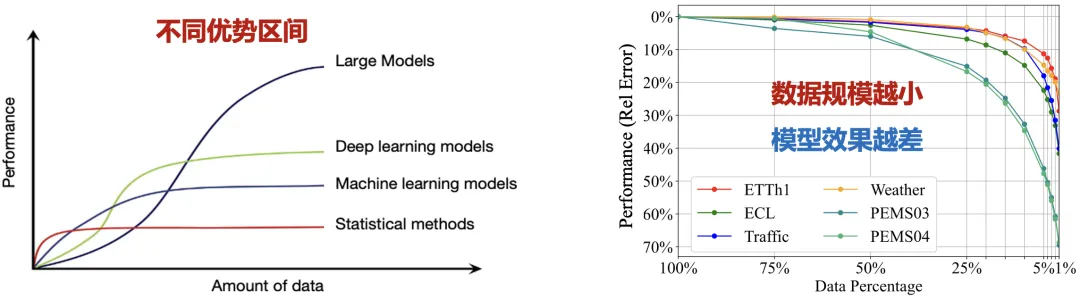
模型效果与数据规模息息相关
我们基于此前自研的时序大模型 Timer 构建了 Timer-XL 模型,主要扩展了模型的上下文长度,增强对预测任务的通用适配性,以及在规模上验证了时序模型的扩展定律。
03
Timer-XL 优化:通用、灵活、可扩展
下一词预测(Next Token Prediction)一直是大语言模型的主流训练目标之一,其核心在于训练时并行优化在多个位置上的自回归预测信号,推理时,模型可基于不同的上下文长度进行预测。我们将该范式首次扩展到多变量时间序列:
如下图(b)所示,基于分块(Patching)后的二维时间序列单元,每个位置的下一词预测不仅依赖于该序列的历史变化(时序因果性),还依赖于相关变量的外生关联,这为 Transformer 建模多维时序数据带来了新的问题。
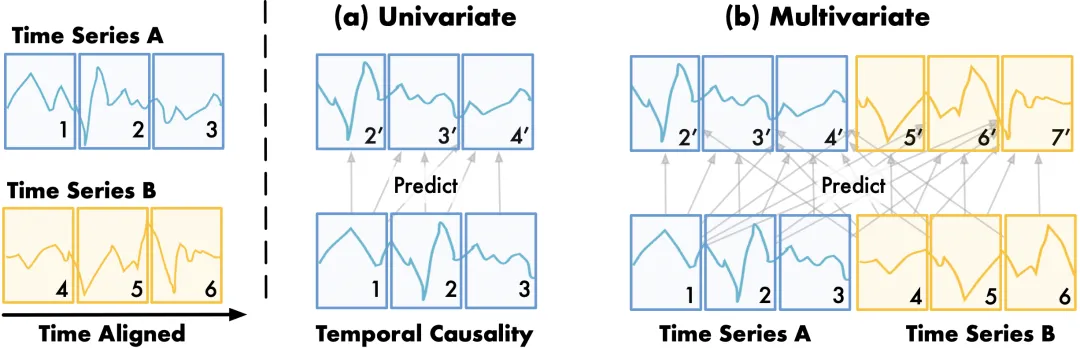
多变量时序预测中的序列内与序列间时序关联
为了解决上述问题,本工作提出一种适配多维时序数据的自注意力掩码机制。如下图所示,我们将多变量数据的下一词预测时序依赖进行可视化。在多变量时序预测任务中,假设所有变量之间都存在互相关联,上述关联图表示为全 1 邻接矩阵 ,通过引入 Kronecker 积,对下三角掩码矩阵 进行分块扩展,上述张量乘积的结果恰好为多变量时序关联所需的注意力掩码。
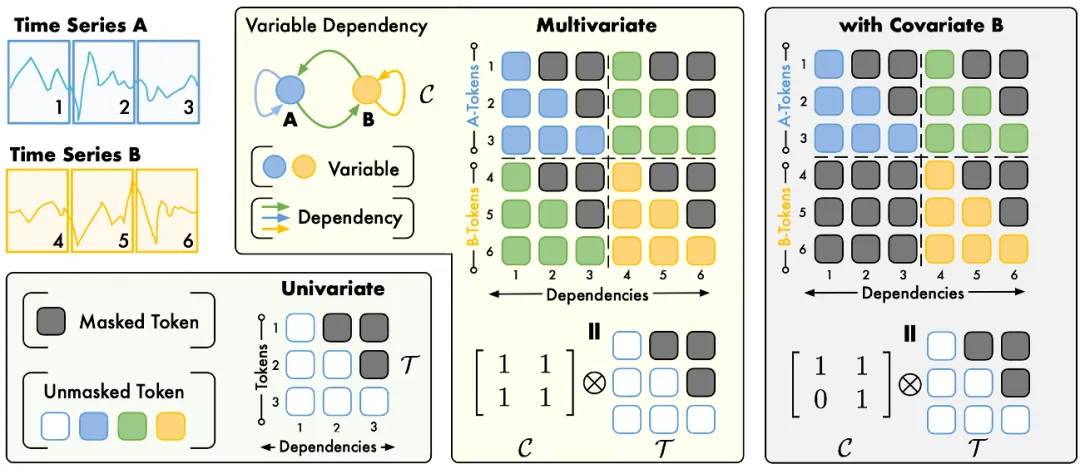
TimeAttention 将多变量时序关联解耦为变量关联图与时序因果掩码
类似地,在提供先验变量关联的情况下(例如带协变量的时序预测),通过定制变量关联图,上述掩码机制能够泛化到其他预测场景中。因此,TimeAttention 可形式化为:
其中 是在 Transformer 各层前向传播的时序单元编码,其中,时序单元的自注意力分数 计算方式如下:
上述计算过程使用旋转位置编码(RoPE)规避 Attention 机制在时间维的置换不变性(Permutation-Invariance),并使用注意力位置偏置(ALiBi)赋予内生变量与外生变量不同的可学习权重。此外,TimeAttention 在变量维保持了排列不变性(Permutation-Equivalence)。

多变量时序预测中的时序因果性与变量等价性
Timer-XL 采用 Patch Token 作为基本时序单元,将多维时间序列展平为一维 Token 序列,使用 TimeAttention 进行通用时序建模,最终获得每个位置的上下文表征,以进行下一词预测。受益于 Decoder-Only 结构的上下文长度可变性,Timer-XL 可以支持多种预测任务。
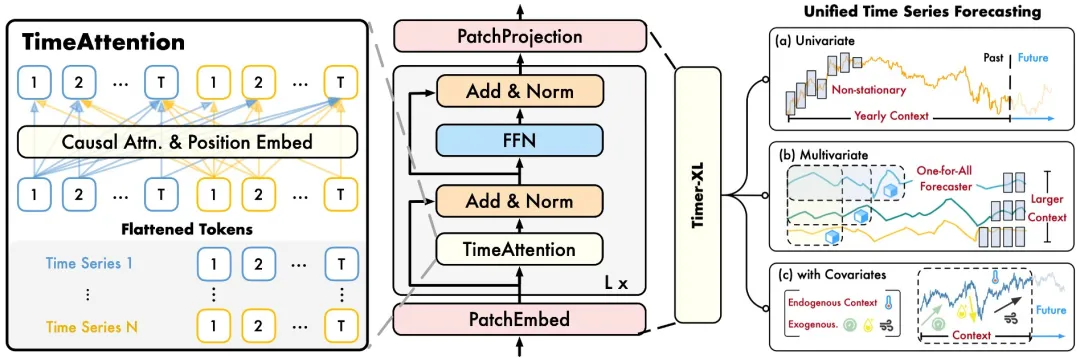
Timer-XL 模型结构
04
Timer-XL 预测效果:多类场景领先
我们从通用时序预测模型和时序大模型两个角度,评估了 Timer-XL 模型的预测效果。
(1) 通用时序预测
我们在多项时序预测场景中,对多类深度预测模型进行有监督训练,与 Timer-XL 对比模型包括 UniTST(2024)、iTransformer(2023)、DLinear(2023)、PatchTST(2022)、TimesNet(2022)、Stationary(2022)、Autoformer(2021)等。
为避免过度调参,实验基于 Timer-XL 的上下文灵活性,在每个数据集上只训练一个模型,基于滚动预测进行多种预测长度下的效果评估。
Timer-XL 在多变量预测中取得了更好的平均结果,证明了其无需针对不同预测长度分别训练,也能够获得高准确性预测结果的能力。
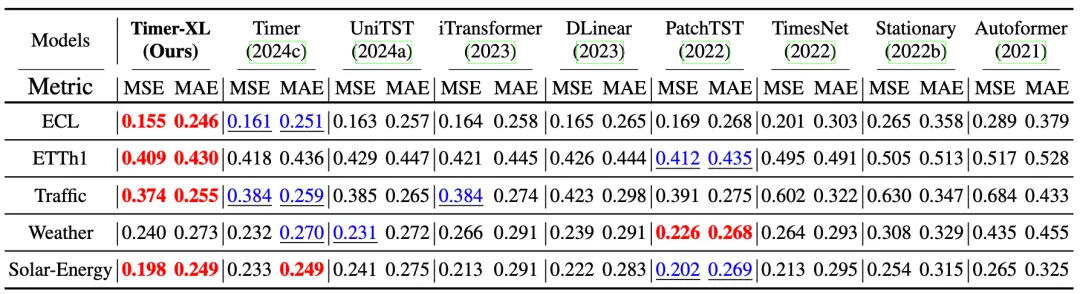
多变量时序预测,多个预测长度下的平均效果
此外,在单变量预测、自动站时空预测、协变量预测以及多变量预训练等预测场景中,Timer-XL 相较主流深度预测模型均取得了性能提升。
单变量长上下文预测:相比 PatchTST,Timer-XL 模型更适配上下文场景
时空预测:Timer-XL 模型预测效果达到了 SOTA 水平(State-of-the-Art,在该领域当前达到的最佳性能水平)
协变量预测:Timer-XL 表现优于 SOTA 水平的专门化模型
多变量预训练:Timer-XL 基于万亿大规模工业物联网领域的时序数据集进行预训练,因此具有更强的泛化性能,可以在训练集之外的数据集保持高可靠性
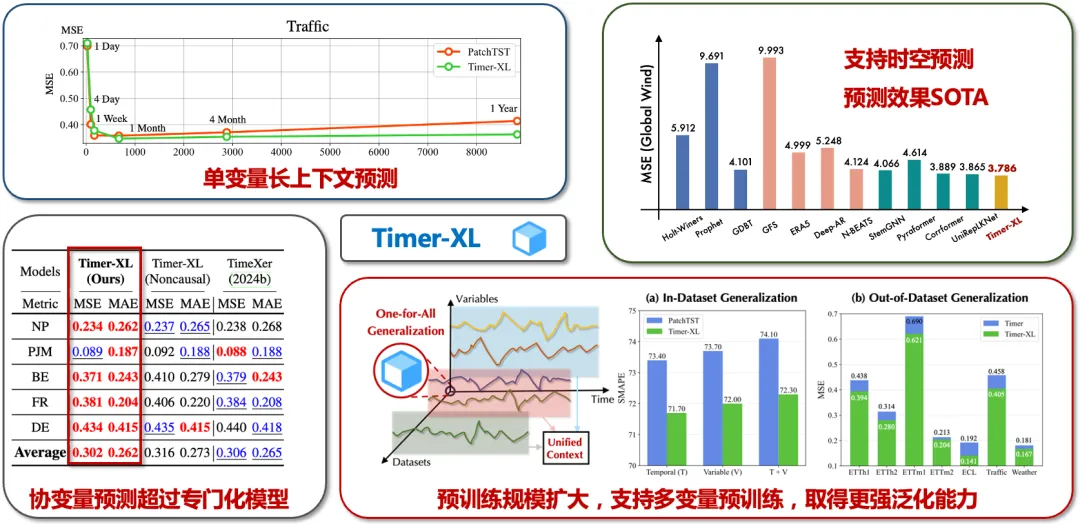
其余预测场景实验结果
(2) 零样本时序预测
我们使用 UTSD,LoSTA 等公开时序数据针对 Timer-XL 和其他时序大模型进行了大规模预训练,在零样本预测任务(使用预训练模型在分布外数据上直接预测)中进行对比。与 Timer-XL 对比的时序大模型包括 Time-MoE(2024)、Moiria(2024)、Chronos(2024)、Moment(2024)、TimesFM(2023)。
因为预训练规模以及上下文长度的增长,Timer-XL 的零样本预测效果相较其他模型取得了显著提升,说明 Timer-XL 模型的特征提取能力和泛化使用能力都非常强大,也验证了时序模型的规模定律。
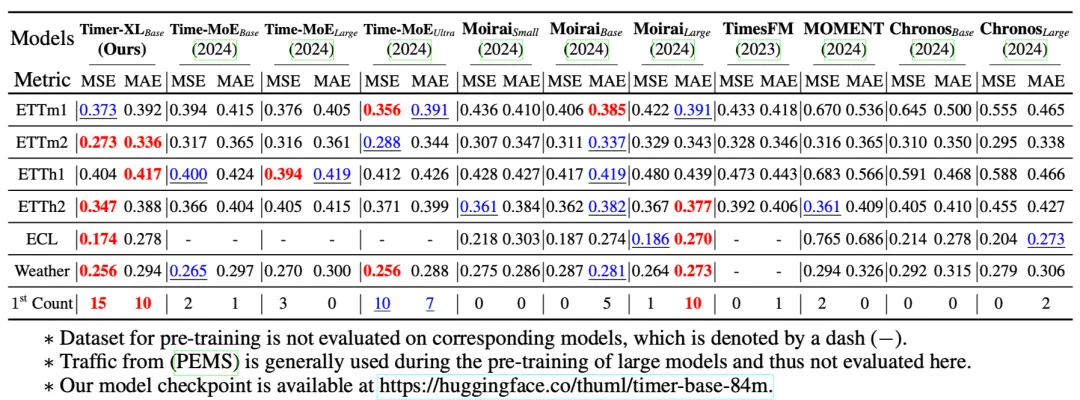
零样本时序预测结果
(3) 模型分析

重归一化
以往普遍采用的窗口重归一化技术会随着输入上下文的变长逐渐退化。实验表明,在长上下文预测任务中(Lookback Length > 1k)采用重归一化技术还会导致 Transformer 预测模型效果劣化。相比之下,采用 Decoder-Only 结构+不使用重归一化的模型能够取得更好的预测效果。
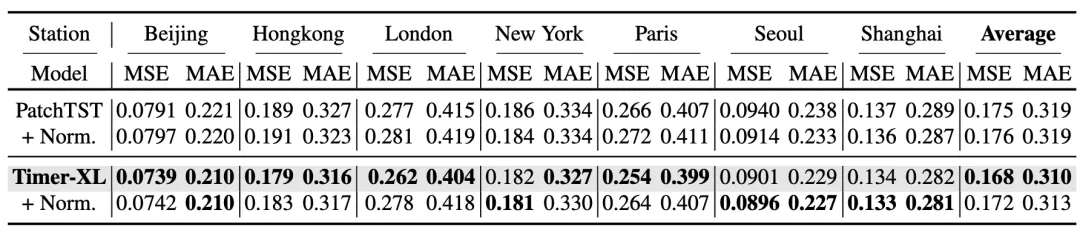
重归一化对长上下文预测效果的影响
位置编码
我们对位置编码的选择进行了消融实验,结果表明合适的位置编码能够带来可观的效果提升。
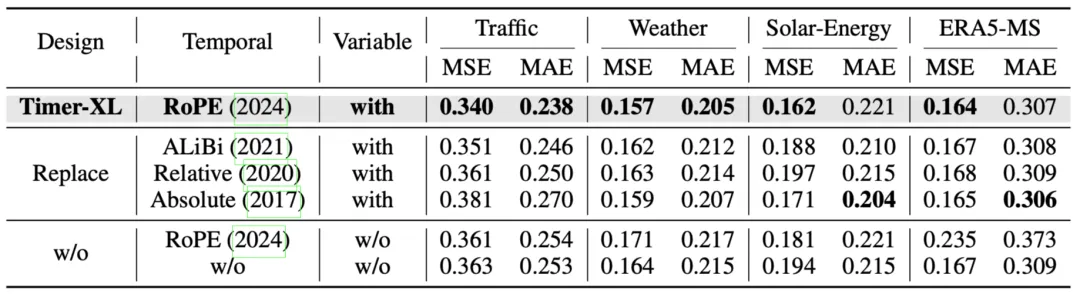
位置编码消融实验
特征分析
通过对 TimeAttention 的可视化,我们发现模型能够自动挖掘时序数据中的潜在关联,如内生变量和外生变量的关联性以及时序自相关性等。
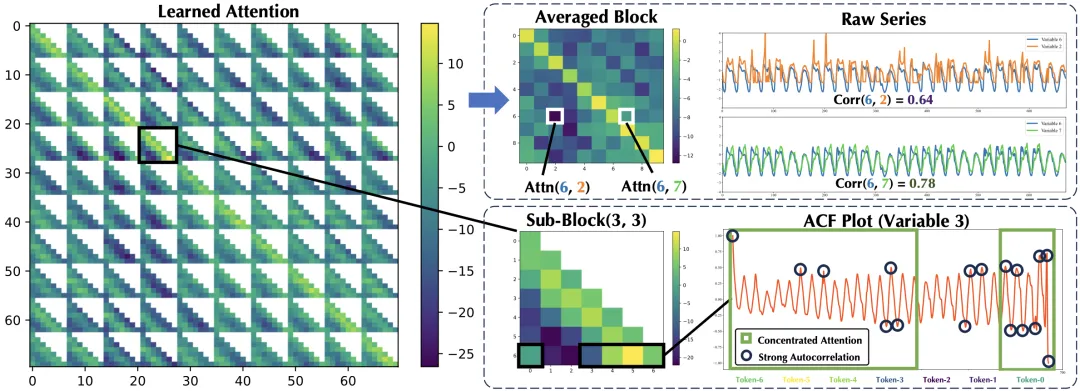
注意力可视化
针对长上下文预测问题,本文提出了一种通用、灵活、可扩展的时序预测基础模型。在扩展上下文长度的基础上,本文着眼于深度预测模型的通用性提升:(1)将下一词预测适配到不同的变量数以及时间点的数据;(2)扩展预训练规模,提供开箱即用的时序预测能力。
权威认可并不是创新的终点,未来我们将持续迭代,面向实际预测决策需求,探索深度模型在通用性、泛化性、可靠性方面的提升。
欢迎添加小助手欧欧(微信号:apache_iotdb)获得论文,或访问项目 GitHub(https://github.com/thuml/Timer-XL)了解更多内容!
规上企业应用实例
能源电力:中核武汉|国网信通产业集团|华润电力|大唐先一|上海电气国轩|清安储能|某储能厂商|太极股份
智慧工厂与物联:PCB 龙头企业|博世力士乐|德国宝马|北斗智慧物联|某物联大厂|昆仑数据|怡养科技|绍兴安瑞思























 3469
3469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









