



随着我们从2024年进入2025年,AI领域的焦点正从检索增强生成(RAG)转向更具突破性的技术——智能体式RAG。
本文将向您介绍智能体式RAG的概念、实现方法以及其优点和局限性。
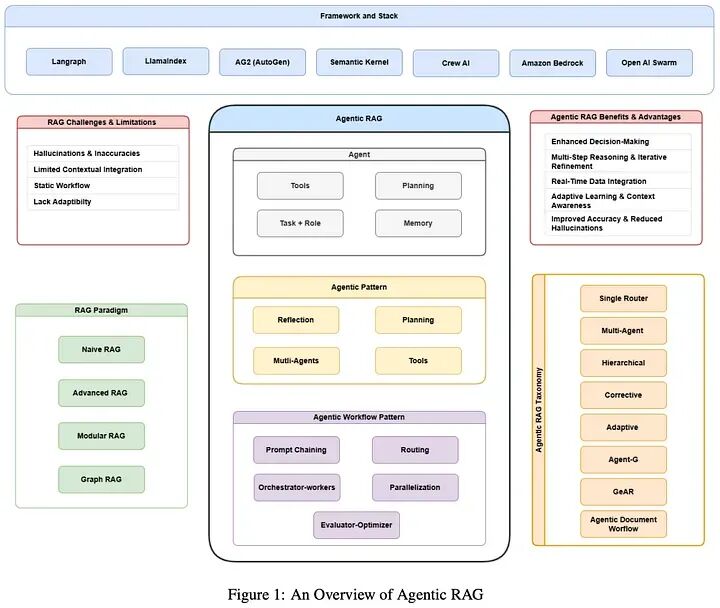
1.1 智能体式RAG概述
检索增强生成(RAG)代表了人工智能领域的重大进步,它将大型语言模型(LLM)的生成能力与实时数据检索相结合。虽然LLM在自然语言处理方面展示了卓越的能力,但它们对静态预训练数据的依赖往往导致过时或不完整的响应。RAG通过动态检索外部源的相关信息并将其整合到生成过程中解决了这一限制,从而实现上下文准确和最新的输出。
图片来源:AgenticRAG-Survey
1.2 RAG与智能体式RAG对比
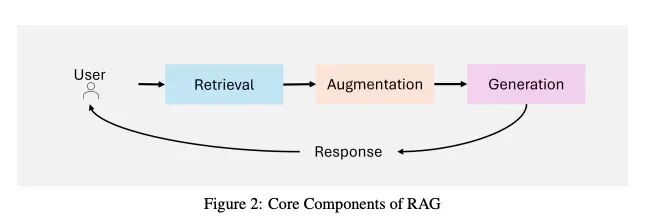
RAG系统的架构集成了三个主要组件:
图片来源:AgenticRAG-Survey
- • 检索:负责查询外部数据源,如知识库、API或向量数据库。高级检索器利用密集向量搜索和基于transformer的模型来提高检索精度和语义相关性。
- • 增强:处理检索到的数据,提取和总结最相关的信息以与查询上下文对齐。
- • 生成:将检索到的信息与LLM的预训练知识相结合,生成连贯、上下文适当的响应。

智能体式RAG通过使用AI智能体引入自主决策和编排,实现了更强大和灵活的检索-生成工作流。其高级流程包括:
- • 步骤1:面向智能体的查询分析
用户查询被路由到一个AI智能体,该智能体解释查询的意图和上下文。
- • 步骤2:记忆和策略
智能体利用短期(会话)和长期(历史)记忆来跟踪上下文。然后它制定动态检索和推理策略。
- • 步骤3:工具选择和数据收集
智能体智能地选择工具——如向量搜索、API连接器,甚至其他智能体——并从相关知识库(例如,MCP服务器、图数据库、文档存储)中检索数据。
- • 步骤4:提示构建
检索到的内容通过结构化上下文和系统指令进行丰富。这个丰富的提示被传递给LLM。
- • 步骤5:LLM响应生成
LLM处理优化和上下文化的提示,产生高度相关、可解释和自适应的响应。
- RAG范式的演进
检索增强生成(RAG)领域已经显著演进,以解决现实世界应用日益增长的复杂性,其中上下文准确性、可扩展性和多步推理至关重要。从简单的基于关键词的检索开始,已经转变为复杂的、模块化和自适应系统,能够集成多样化的数据源和自主决策过程。这一演进突显了RAG系统高效有效处理复杂查询的日益增长的需求。
本节考察了RAG范式的进展,呈现了关键发展阶段:朴素RAG、高级RAG、模块化RAG、GraphRAG和智能体式RAG
2.1 朴素RAG
朴素RAG代表了检索增强生成的基础实现。图3说明了朴素RAG的简单检索-读取工作流,专注于基于关键词的检索和静态数据集。这些系统依赖于简单的基于关键词的检索技术,如TF-IDF和BM25,从静态数据集中获取文档。然后,检索到的文档用于增强语言模型的生成能力。
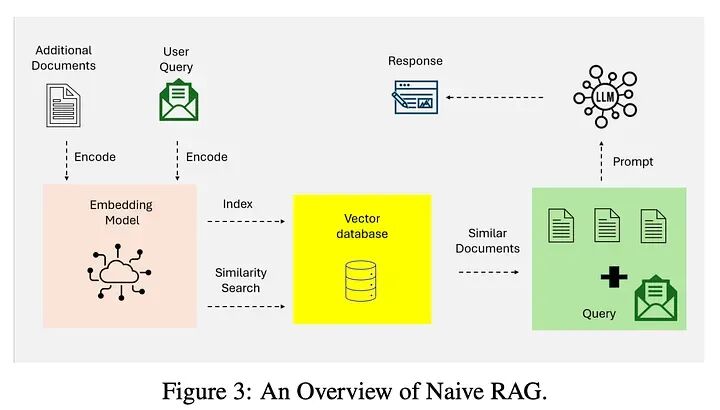
朴素RAG的特点是其简单性和易于实现,使其适用于涉及基于事实的查询且上下文复杂性最小的任务。然而,它有几个限制:
- • 缺乏上下文感知:由于依赖词汇匹配而非语义理解,检索到的文档往往无法捕捉查询的语义细微差别。
- • 碎片化输出:缺乏高级预处理或上下文整合通常导致不连贯或过于通用的响应。
- • 可扩展性问题:基于关键词的检索技术在处理大型数据集时遇到困难,通常无法识别最相关的信息。
尽管有这些限制,朴素RAG系统为将检索与生成集成提供了关键的概念验证,为更复杂的范式奠定了基础。
2.2 高级RAG
高级RAG系统通过整合语义理解和增强的检索技术,建立在朴素RAG的限制之上。图4强调了高级RAG在检索中的语义增强和迭代、上下文感知的管道。这些系统利用密集检索模型,如密集段落检索(DPR),和神经排序算法来提高检索精度。
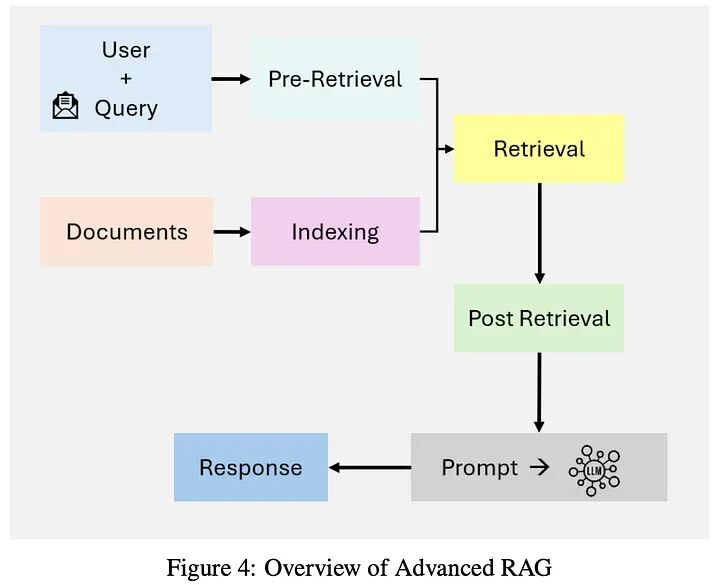
2.3 模块化RAG
模块化RAG代表了RAG范式的最新演进,强调灵活性和定制化。这些系统将检索和生成管道分解为独立的、可重用的组件,实现领域特定优化和任务适应性。
图5展示了模块化架构,展示了混合检索策略、可组合管道和外部工具集成。
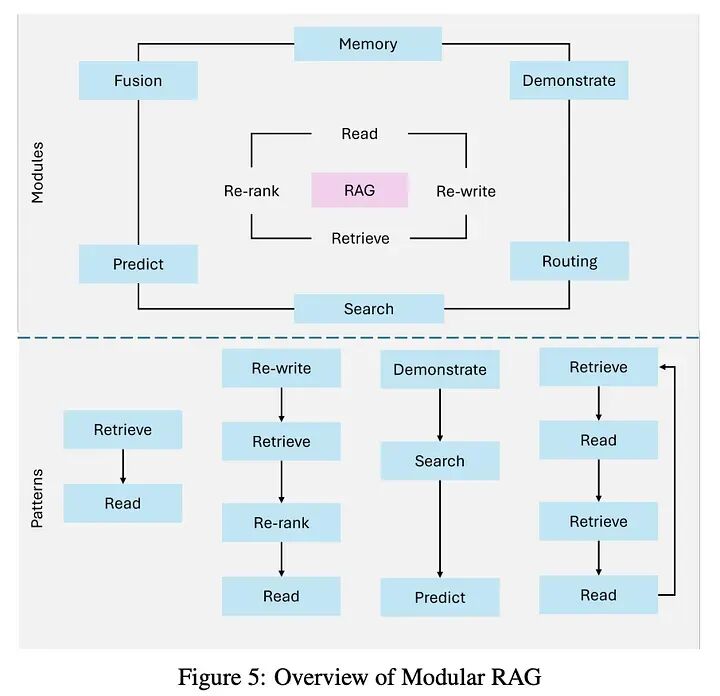
2.4 GraphRAG
GraphRAG通过集成基于图的数据结构扩展了传统的检索增强生成系统,如图6所示。这些系统利用图数据中的关系和层次结构来增强多跳推理和上下文丰富化。通过整合基于图的检索,GraphRAG能够实现更丰富和更准确的生成输出,特别是对于需要关系理解的任务。
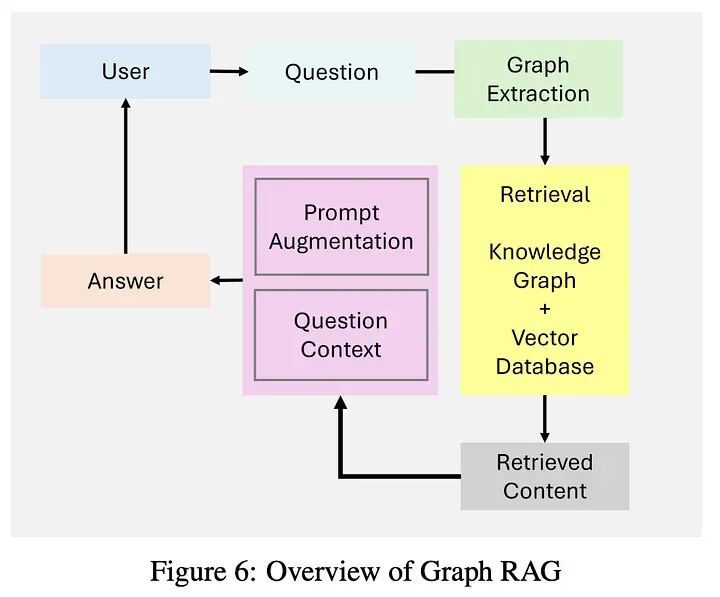
然而,GraphRAG有一些限制:
- • 有限的可扩展性:对图结构的依赖可能限制可扩展性,特别是对于广泛的数据源。
- • 数据依赖:高质量的图数据对于有意义的输出至关重要,限制了其在非结构化或注释不良的数据集中的适用性。
- • 集成的复杂性:将图数据与非结构化检索系统集成增加了设计和实现的复杂性。
GraphRAG非常适合于医疗诊断、法律研究和其他需要对结构化关系进行推理的领域等应用。
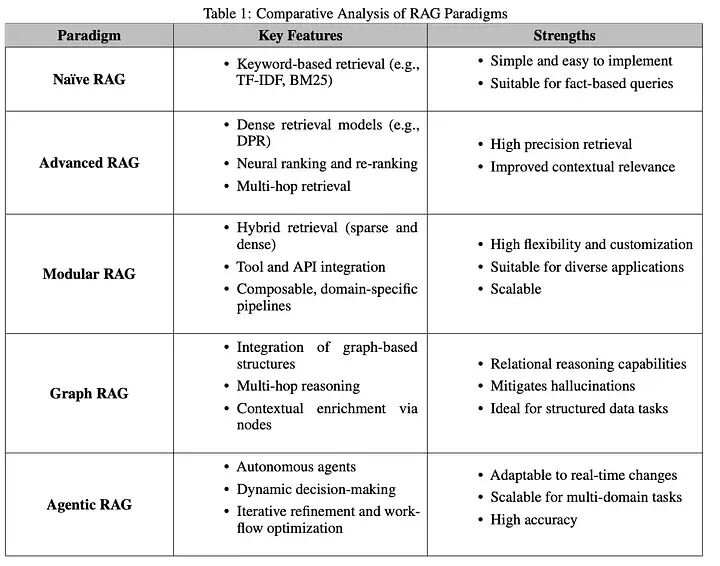
2.5 智能体式RAG
智能体式RAG通过引入能够动态决策和工作流优化的自主智能体,代表了范式转变。与静态系统不同,智能体式RAG采用迭代优化和自适应检索策略来解决复杂的、实时的和多领域查询。这种范式利用了检索和生成过程的模块化,同时引入了基于智能体的自主性。

当涉及到扩展检索增强生成(RAG)系统以解决现实世界业务问题时,没有单一、僵化的模板。架构必须根据您的独特用例、数据环境和领域需求进行演进。
要有效地做到这一点,理解驱动智能体式RAG管道的模块化组件至关重要。让我们分解核心阶段并探索它们如何交互:
🧠 1. 分析查询 第一步涉及将原始用户查询传递给一个由语言模型驱动的智能体,负责深度分析和转换。这个阶段包括:
- • 🔁 查询重写:智能体可能会重新表述输入,生成精炼或替代版本以更好地提取相关知识。
- • 🧭 决策逻辑:它评估查询是否可以直接回答,或者是否需要额外数据。
🔍 2. 额外数据源
如果需要更多上下文,系统会激活一个或多个检索智能体,负责获取最相关的数据。这些智能体可能获取:
- • 📍 实时用户数据(例如,用户当前位置或状态)
- • 📂 私有/内部文档(项目文件、报告、手册)
- • 🌐 公共或基于网络的内容(API数据、索引文章等)
每个检索路径都是动态的,通常根据查询的意图和性质进行选择。
🧩 3. 重新排序搜索结果
一旦检索到候选文档,它们会通过一个重新排序模型——通常比基础嵌入器更强大和上下文感知。这一步:
- • ⚖️ 过滤噪声,仅提取语义最相关的数据点。
- • 📉 压缩范围,确保下游步骤使用精确、高信号的上下文。
🧪 4. 生成答案
在LLM智能体确定它已经有足够知识的情况下,它直接进行答案合成,可能产生:
- • ✅ 单个事实响应
- • 🧮 建议操作列表
- • 🤖 甚至执行任务的智能体驱动工作流
📊 5. 分析答案
最后,生成的答案由另一个智能体(或重新调用的同一智能体)进行关键评估:
- • 🔄 如果准确和相关,则与最终用户共享。
- • ♻️ 如果不足,系统可能会重新表述原始查询并重新启动循环——由预定义的重试限制限制以避免无限循环。
本质上,智能体式RAG系统更像是自主决策者而不是简单的检索工具。它们动态适应、推理并在各阶段演进——全部由您的业务上下文指导。
💡 设计您的系统意味着选择正确的智能体,定义它们的决策边界,并仔细编排它们的交互。
- 传统RAG系统的挑战和局限性
检索增强生成(RAG)通过将生成与实时数据结合推进了LLM,但在复杂的现实世界场景中,仍然有几个关键挑战限制了其性能:
- 上下文整合
即使RAG系统成功检索到相关信息,它们也常常难以将其无缝整合到生成的响应中。检索管道的静态性质和有限的上下文感知导致碎片化、不一致或过于通用的输出。
示例:
当被问及"阿尔茨海默病研究的最新进展及其对早期治疗的影响是什么?“时,RAG可能会提取相关研究,但未能将这些发现连接到患者护理的可操作见解。同样,对于"干旱地区小规模农业的最佳可持续实践是什么?”,它可能检索到广泛的农业方法,但错过了干旱特定的可持续技术。
2. 多步推理
复杂问题通常需要跨多个步骤进行推理,但传统RAG通常在单次跳转中检索信息,错过了更深层次的合成。
示例:
像"欧洲可再生能源政策的哪些经验可以应用于发展中国家,潜在的经济影响是什么?"这样的查询需要结合政策数据、当地背景和经济预测。RAG通常无法将所有这些部分整合成一个连贯的答案。
3. 可扩展性和延迟问题
随着外部数据的增长,搜索和排序大型数据集会减慢响应时间,这对实时用例来说是有问题的。
示例:
在实时金融分析或客户支持中,获取和处理大型数据集的延迟可能是代价高昂的——例如,由于检索缓慢而在高频交易期间错过市场趋势。
- 智能体式RAG分类
4.1 单智能体智能体式RAG:路由器
单智能体智能体式RAG:作为一个集中式决策系统,其中单个智能体管理信息的检索、路由和整合(如图所示)。这种架构通过将这些任务整合到一个统一的智能体中来简化系统,使其在工具或数据源数量有限的设置中特别有效。
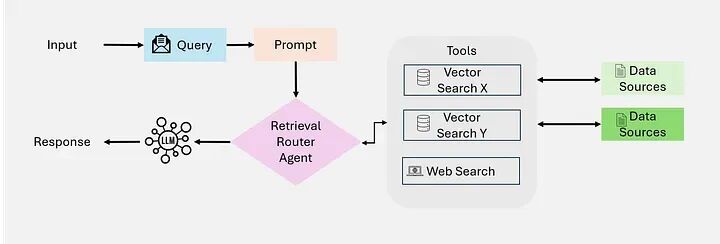
单智能体RAG概述 | 图片来源:AgenticRAG-Survey
工作流:
-
查询提交和评估:用户提交查询;协调智能体分析并确定适当的数据源
-
知识源选择:
- • 结构化数据库(例如,通过Text-to-SQL的PostgreSQL、MySQL)。
- • 语义搜索(例如,对PDF、书籍、内部记录进行基于向量的搜索)。
- • 网络搜索(实时在线数据)。
- • 推荐系统(基于用户档案的个性化建议)。
-
数据整合和LLM合成:检索到的数据传递给LLM,合成为连贯的响应。
-
输出生成:系统为用户生成简洁、可操作的响应。

尽管有其进步,智能体式RAG面临一些挑战:
- • 协调复杂性:管理智能体之间的交互需要复杂的编排机制。
- • 计算开销:使用多个智能体增加了复杂工作流的资源需求。
- • 可扩展性限制:虽然可扩展,但系统的动态性质可能会对高查询量的计算资源造成压力。
智能体式RAG在客户支持、金融分析和自适应学习平台等领域表现出色,其中动态适应性和上下文准确性至关重要。
4.2 多智能体智能体式RAG系统
多个专业智能体协作工作,每个专注于特定的数据源或任务,实现对复杂查询的可扩展、模块化处理。
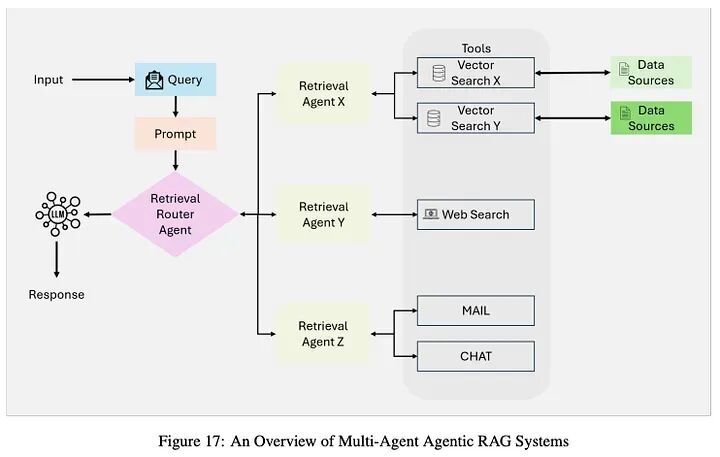
工作流:
- 查询提交:协调智能体接收查询并将其分发给专业智能体。
2. 专业检索智能体:
智能体1:结构化数据(对PostgreSQL、MySQL进行SQL查询)。
智能体2:语义搜索(PDF、书籍、内部非结构化数据)。
智能体3:实时网络搜索(新闻、政策更新)。
智能体4:推荐系统(个性化内容、专家建议)。
-
工具访问和数据检索:并行利用向量搜索、Text-to-SQL、网络搜索和外部API。
-
数据整合和LLM合成:聚合的数据传递给LLM,合成为全面输出。
-
输出生成: 最终、整合的响应交付给用户。
挑战:
- • 跨智能体协调复杂性增加。
- • 更高的计算资源消耗。
- • 跨异构输出的复杂数据整合。

4.3 层次化智能体式RAG系统
层次化智能体式RAG:系统采用结构化的、多层次的方法进行信息检索和处理,如图18所示,提高了效率和战略决策。智能体按层次组织,高级智能体监督和指导低级智能体。这种结构实现了多级决策,确保查询由最合适的资源处理。
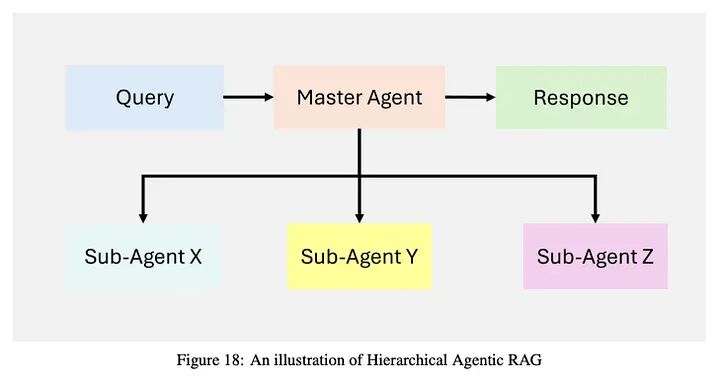
一种分层架构,其中顶级智能体管理多个下属智能体,为高度复杂的任务实现动态委托和合成。
工作流:
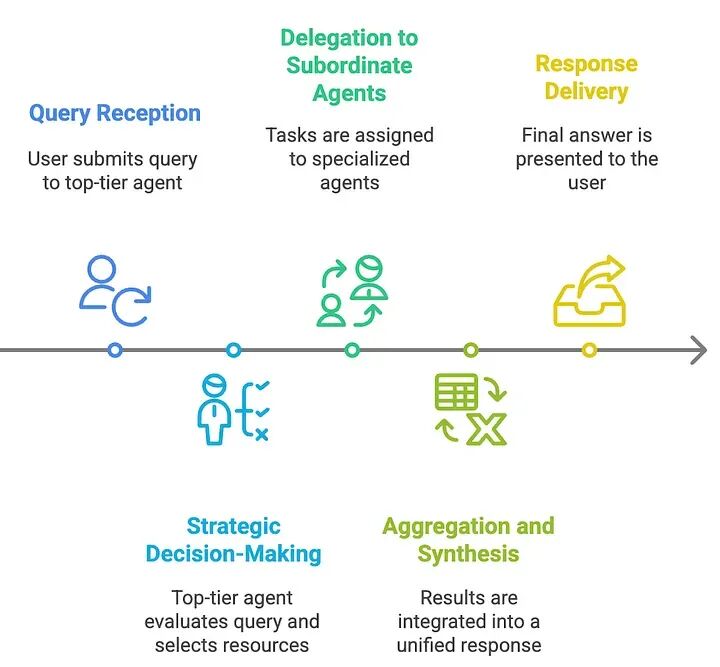
-
查询接收:用户提交查询,由负责初始评估和任务委托的顶级智能体接收。
-
战略决策:顶级智能体评估查询复杂性,并根据领域相关性和数据可靠性选择优先考虑哪些下属智能体、数据库、API或检索工具。
-
委托给下属智能体:任务分配给专业的低级智能体(例如,SQL数据库、网络搜索、专有API),它们独立执行检索。
-
聚合和合成:下属智能体将结果返回给顶级智能体,顶级智能体整合和合成信息为连贯、统一的响应。
-
响应交付:最终、合成的答案呈现给用户,确保完整性和上下文准确性。

挑战:
- • 协调复杂性:跨多个级别的强大智能体间通信增加了编排开销。
- • 资源分配:跨层的高效任务分配复杂,需要仔细管理以避免瓶颈。
4.4 智能体式纠正RAG
纠正RAG引入了自我纠正机制,迭代优化检索结果,通过将智能智能体嵌入工作流来增强文档利用率和响应质量。
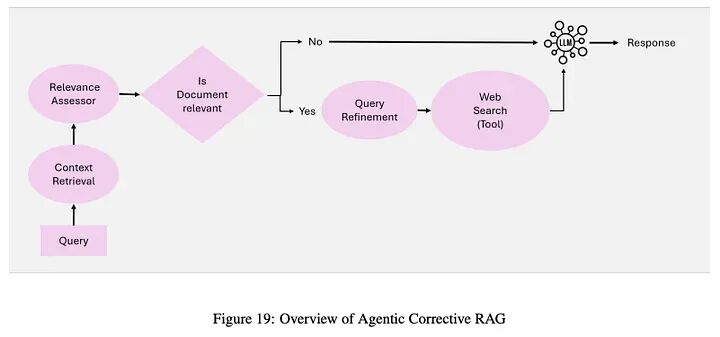
工作流:
-
- 上下文检索智能体:从向量数据库检索初始上下文文档。
-
- 相关性评估智能体:评估检索到的文档的相关性;标记不相关或模糊的文档以进行纠正。
-
- 查询优化智能体:使用语义理解重写和优化查询,以改善检索结果。
-
- 外部知识检索智能体:如果上下文仍然不足,进行网络搜索或访问替代数据源。
-
- 响应合成智能体:将所有验证和优化的信息合成为连贯、准确的响应。
纠正RAG的关键思想:
- • 文档相关性评估:评估检索到的文档;低相关性文档触发纠正步骤。
- • 查询优化和增强:查询由查询优化智能体重写,以改善检索,确保为响应生成提供更高质量的输入。

4.5 自适应智能体式RAG
自适应RAG通过根据每个查询的复杂性定制检索策略,引入动态查询处理,增强了灵活性和效率。
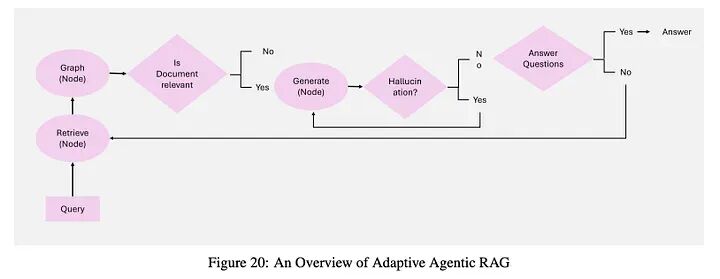
自适应RAG的关键思想:
- • 直接查询:对于基于事实的问题,直接生成而不检索(例如,“水的沸点是多少?”)。
- • 简单查询:对于中等复杂任务进行单步检索(例如,“我最新的电费账单状态是什么?”)。
- • 复杂查询:对于需要分层推理的复杂查询进行多步检索和迭代优化(例如,“X市的人口在过去十年中如何变化,贡献因素是什么?”)。
工作流:
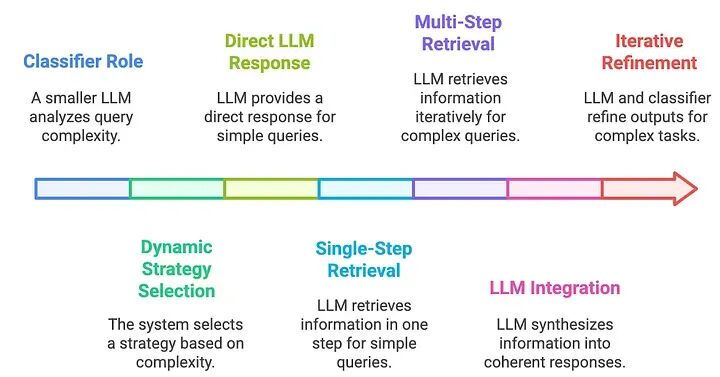
- 分类器角色:
- • 一个较小的LLM使用基于历史结果自动标记的数据集分析查询复杂性。
2. 动态策略选择:
- • 对于直接查询,直接LLM响应。
- • 对于简单查询,单步检索。
- • 对于需要迭代推理的复杂查询,多步检索。
3. LLM集成:
- • 检索到的信息合成为连贯的响应。
- • LLM和分类器之间的迭代交互优化复杂任务的输出。

4.6 基于图的智能体式RAG
4.6.1 Agent-G:GraphRAG的智能体式框架
Agent-G引入了一种新颖的架构,将图知识库与非结构化文档检索相结合,增强了RAG系统中的推理和检索准确性。
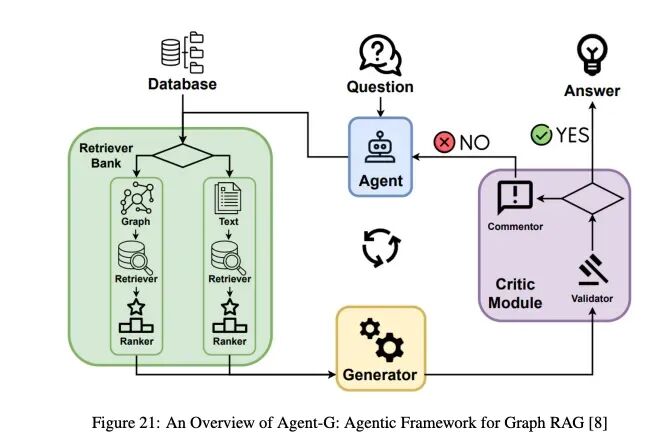
Agent-G的关键思想:
- • 图知识库:提取结构化关系(例如,医疗保健中的疾病到症状映射)。
- • 非结构化文档:用文本源的上下文信息补充结构化数据。
- • 批评模块:评估检索数据的相关性和质量,在需要时触发纠正操作。
- • 反馈循环:通过验证和重新查询迭代优化检索和合成。
工作流:
-
- 检索器库:模块化智能体专门从事图或非结构化数据检索,根据查询需求动态选择源。
-
- 批评模块:验证检索信息的相关性和置信度,标记不确定结果以进行优化。
-
- 动态智能体交互:任务特定智能体协作将结构化和非结构化数据源集成到统一工作流中。
-
- LLM集成:将验证的数据合成为连贯的响应,通过批评反馈循环持续优化。

4.6.2 GeAR:图增强的RAG智能体
GeAR通过集成基于图的检索和智能体控制增强了传统RAG,改善了复杂查询的多跳检索。
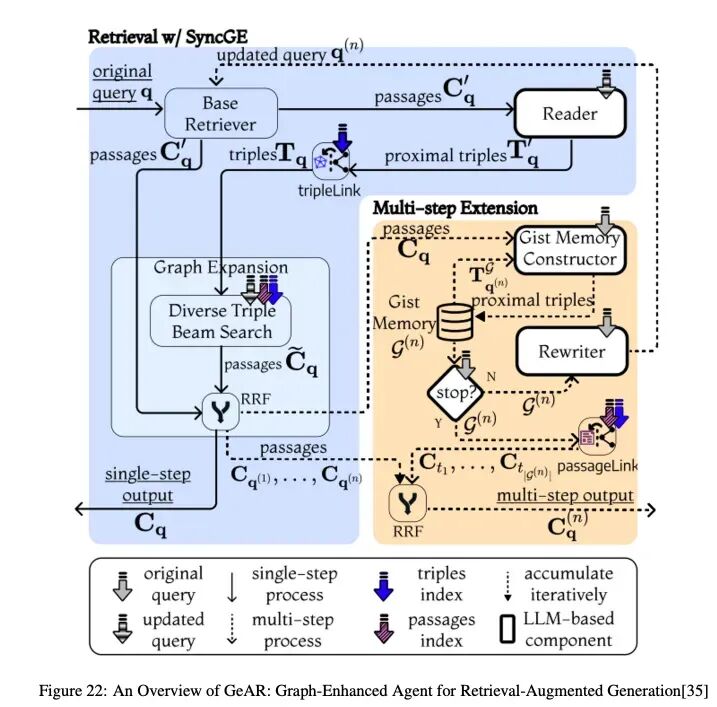
GeAR的关键思想:
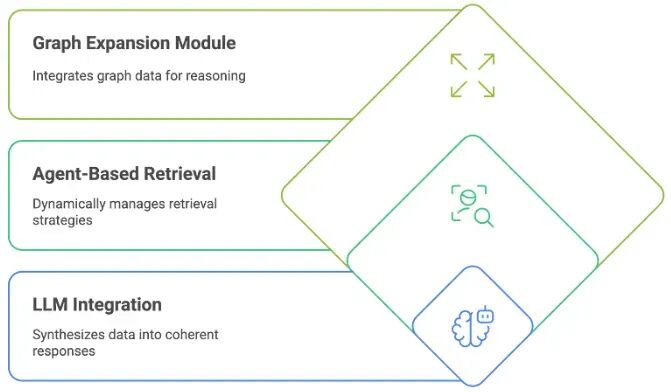
- • 图扩展:通过整合图结构数据扩展基础检索器(例如,BM25),捕获复杂的实体关系和依赖关系。
- • 智能体框架:利用智能体动态管理检索策略,根据查询复杂性自主选择图扩展路径。
工作流:
-
- 图扩展模块:将图数据集成到检索中,扩展搜索空间以包括连接的实体,以实现更好的多跳推理。
-
- 基于智能体的检索:智能体动态选择和组合检索策略,在必要时利用图扩展检索。
-
- LLM集成:使用LLM将图丰富和非结构化数据合成为连贯、上下文丰富的响应。

4.7 智能体式RAG中的智能体式文档工作流(ADW)
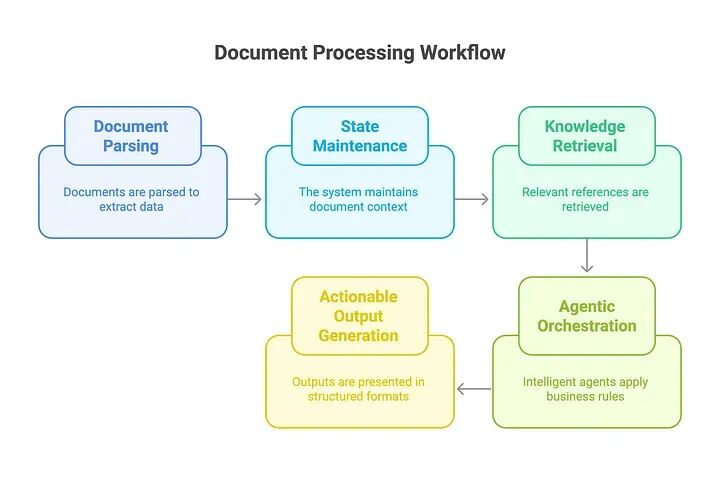
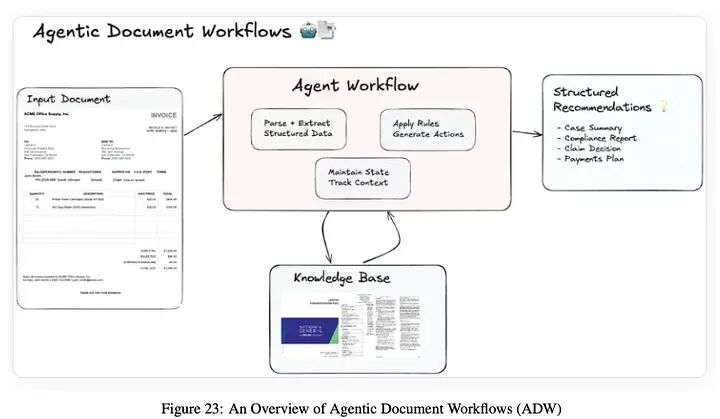
ADW通过编排以文档为中心的流程中的端到端知识工作自动化扩展了传统RAG,将解析、检索、推理和结构化输出与智能智能体集成。
工作流:
- 文档解析和信息结构化:
- • 使用企业工具(例如,LlamaParse)解析文档,提取发票号码、日期、供应商、行项目和付款条件等字段。
- • 为下游任务结构化提取的数据。
- 跨流程状态维护:在多个处理阶段维护文档上下文和跟踪工作流进展。
3. 知识检索:
- • 从外部知识库(例如,LlamaCloud)和向量索引检索相关参考。
- • 融入实时、特定领域的指导原则以支持决策。
-
智能体式编排:智能智能体应用业务规则,执行多跳推理,并协调解析器、检索器和API等组件。
-
可操作输出生成:生成结构化输出,在简洁、可操作的报告中提供合成建议和见解。

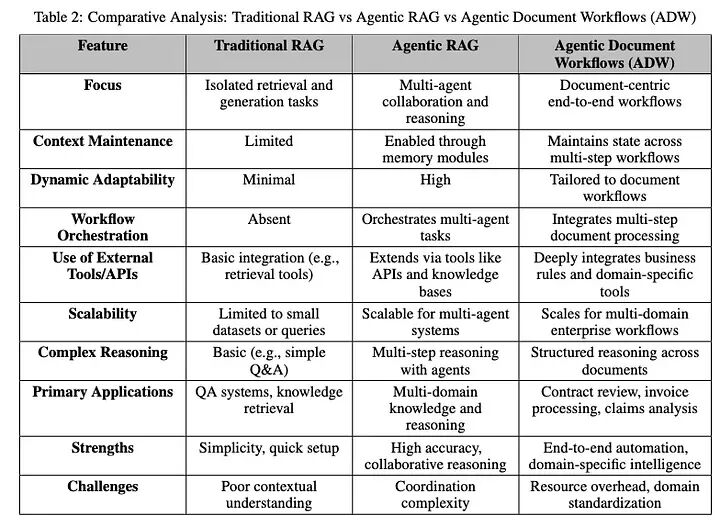
- 智能体式RAG框架的比较分析
表2提供了三种架构框架的全面比较分析:传统RAG、智能体式RAG和智能体式文档工作流(ADW)。该分析突出了它们各自的优点、缺点和最适合的场景,为它们在不同用例中的适用性提供了有价值的见解。
- 构建智能体式RAG系统
在本教程中,我们将构建一个检索智能体。当您希望LLM决定是否从向量存储库检索上下文或直接响应用户时,检索智能体非常有用。
在本教程结束时,我们将完成以下工作:
-
- 获取和预处理将用于检索的文档。
-
- 为这些文档建立索引以进行语义搜索,并为智能体创建检索器工具。
-
- 构建一个智能体式RAG系统,可以决定何时使用检索器工具。
设置
让我们下载所需的包并设置我们的API密钥:
pip install -U --quiet langgraph "langchain[openai]" langchain-community langchain-text-splitters
``````plaintext
import getpassimport osdef _set_env(key: str): if key not in os.environ: os.environ[key] = getpass.getpass(f"{key}:")_set_env("OPENAI_API_KEY")
6.1 预处理文档
-
- 获取将在我们的RAG系统中使用的文档。我们将使用Lilian Weng的优秀博客的最新三页。我们将首先使用
WebBaseLoader工具获取页面的内容:
- 获取将在我们的RAG系统中使用的文档。我们将使用Lilian Weng的优秀博客的最新三页。我们将首先使用
from langchain_community.document_loaders import WebBaseLoaderurls = [\ "https://lilianweng.github.io/posts/2024-11-28-reward-hacking/",\ "https://lilianweng.github.io/posts/2024-07-07-hallucination/",\ "https://lilianweng.github.io/posts/2024-04-12-diffusion-video/",\]docs = [WebBaseLoader(url).load() for url in urls]
``````plaintext
docs[0][0].page_content.strip()[:1000]
-
- 将获取的文档分割成更小的块,以便索引到我们的向量存储库中:
from langchain_text_splitters import RecursiveCharacterTextSplitterdocs_list = [item for sublist in docs for item in sublist]text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( chunk_size=100, chunk_overlap=50)doc_splits = text_splitter.split_documents(docs_list)
``````plaintext
doc_splits[0].page_content.strip()
6.2 创建检索工具
现在我们有了分割的文档,我们可以将它们索引到我们将用于语义搜索的向量存储中。
-
- 使用内存向量存储和OpenAI嵌入:
from langchain_core.vectorstores import InMemoryVectorStorefrom langchain_openai import OpenAIEmbeddingsvectorstore = InMemoryVectorStore.from_documents( documents=doc_splits, embedding=OpenAIEmbeddings())retriever = vectorstore.as_retriever()
-
- 使用LangChain预构建的
create_retriever_tool创建检索器工具:
- 使用LangChain预构建的
from langchain.tools.retriever import create_retriever_toolretriever_tool = create_retriever_tool( retriever, "retrieve_blog_posts", "Search and return information about Lilian Weng blog posts.",)
-
- 测试工具:
retriever_tool.invoke({"query": "types of reward hacking"})
6.3 生成查询
现在我们将开始为我们的智能体式RAG图构建组件(节点和边)。请注意,这些组件将在[MessagesState](https://archive.ph/o/irT5D/https://langchain-ai.github.io/langgraph/concepts/low_level%23messagesstate)上操作——包含带有聊天消息列表的messages键的图状态。
-
- 构建一个
generate_query_or_respond节点。它将调用LLM根据当前图状态(消息列表)生成响应。给定输入消息,它将决定使用检索器工具进行检索,或直接响应用户。请注意,我们通过.bind_tools让聊天模型访问我们之前创建的retriever_tool:
- 构建一个
from langgraph.graph import MessagesStatefrom langchain.chat_models import init_chat_modelresponse_model = init_chat_model("openai:gpt-4.1", temperature=0)def generate_query_or_respond(state: MessagesState): """Call the model to generate a response based on the current state. Given the question, it will decide to retrieve using the retriever tool, or simply respond to the user. """ response = ( response_model .bind_tools([retriever_tool]).invoke(state["messages"]) ) return {"messages": [response]}
-
- 在随机输入上尝试:
input = {"messages": [{"role": "user", "content": "hello!"}]}generate_query_or_respond(input)["messages"][-1].pretty_print()
6.4 文档评分
-
- 添加一个条件边——
grade_documents——以确定检索到的文档是否与问题相关。我们将使用具有结构化输出模式GradeDocuments的模型进行文档评分。grade_documents函数将根据评分决策返回要去的节点名称(generate_answer或rewrite_question):
- 添加一个条件边——
from pydantic import BaseModel, Fieldfrom typing import LiteralGRADE_PROMPT = ( "You are a grader assessing relevance of a retrieved document to a user question. \n " "Here is the retrieved document: \n\n {context} \n\n" "Here is the user question: {question} \n" "If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n" "Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question.")class GradeDocuments(BaseModel): """Grade documents using a binary score for relevance check.""" binary_score: str = Field( description="Relevance score: 'yes' if relevant, or 'no' if not relevant" )grader_model = init_chat_model("openai:gpt-4.1", temperature=0)def grade_documents( state: MessagesState,) -> Literal["generate_answer", "rewrite_question"]: """Determine whether the retrieved documents are relevant to the question.""" question = state["messages"][0].content context = state["messages"][-1].content prompt = GRADE_PROMPT.format(question=question, context=context) response = ( grader_model .with_structured_output(GradeDocuments).invoke( [{"role": "user", "content": prompt}] ) ) score = response.binary_score if score == "yes": return "generate_answer" else: return "rewrite_question"
-
- 在工具响应中使用不相关文档运行:
from langchain_core.messages import convert_to_messagesinput = { "messages": convert_to_messages( [\ {\ "role": "user",\ "content": "What does Lilian Weng say about types of reward hacking?",\ },\ {\ "role": "assistant",\ "content": "",\ "tool_calls": [\ {\ "id": "1",\ "name": "retrieve_blog_posts",\ "args": {"query": "types of reward hacking"},\ }\ ],\ },\ {"role": "tool", "content": "meow", "tool_call_id": "1"},\ ] )}grade_documents(input)
-
- 确认相关文档被如此分类:
input = { "messages": convert_to_messages( [\ {\ "role": "user",\ "content": "What does Lilian Weng say about types of reward hacking?",\ },\ {\ "role": "assistant",\ "content": "",\ "tool_calls": [\ {\ "id": "1",\ "name": "retrieve_blog_posts",\ "args": {"query": "types of reward hacking"},\ }\ ],\ },\ {\ "role": "tool",\ "content": "reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering",\ "tool_call_id": "1",\ },\ ] )}grade_documents(input)
6.5 重写问题
-
- 构建
rewrite_question节点。检索器工具可能返回不相关的文档,这表明需要改进原始用户问题。为此,我们将调用rewrite_question节点:
- 构建
REWRITE_PROMPT = ( "Look at the input and try to reason about the underlying semantic intent / meaning.\n" "Here is the initial question:" "\n ------- \n" "{question}" "\n ------- \n" "Formulate an improved question:")def rewrite_question(state: MessagesState): """Rewrite the original user question.""" messages = state["messages"] question = messages[0].content prompt = REWRITE_PROMPT.format(question=question) response = response_model.invoke([{"role": "user", "content": prompt}]) return {"messages": [{"role": "user", "content": response.content}]}
-
- 尝试:
input = { "messages": convert_to_messages( [\ {\ "role": "user",\ "content": "What does Lilian Weng say about types of reward hacking?",\ },\ {\ "role": "assistant",\ "content": "",\ "tool_calls": [\ {\ "id": "1",\ "name": "retrieve_blog_posts",\ "args": {"query": "types of reward hacking"},\ }\ ],\ },\ {"role": "tool", "content": "meow", "tool_call_id": "1"},\ ] )}response = rewrite_question(input)print(response["messages"][-1]["content"])
6.6 生成答案
-
- 构建
generate_answer节点:如果我们通过了评分检查,我们可以基于原始问题和检索到的上下文生成最终答案:
- 构建
GENERATE_PROMPT = ( "You are an assistant for question-answering tasks. " "Use the following pieces of retrieved context to answer the question. " "If you don't know the answer, just say that you don't know. " "Use three sentences maximum and keep the answer concise.\n" "Question: {question} \n" "Context: {context}")def generate_answer(state: MessagesState): """Generate an answer.""" question = state["messages"][0].content context = state["messages"][-1].content prompt = GENERATE_PROMPT.format(question=question, context=context) response = response_model.invoke([{"role": "user", "content": prompt}]) return {"messages": [response]}
-
- 尝试:
input = { "messages": convert_to_messages( [\ {\ "role": "user",\ "content": "What does Lilian Weng say about types of reward hacking?",\ },\ {\ "role": "assistant",\ "content": "",\ "tool_calls": [\ {\ "id": "1",\ "name": "retrieve_blog_posts",\ "args": {"query": "types of reward hacking"},\ }\ ],\ },\ {\ "role": "tool",\ "content": "reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering",\ "tool_call_id": "1",\ },\ ] )}response = generate_answer(input)response["messages"][-1].pretty_print()
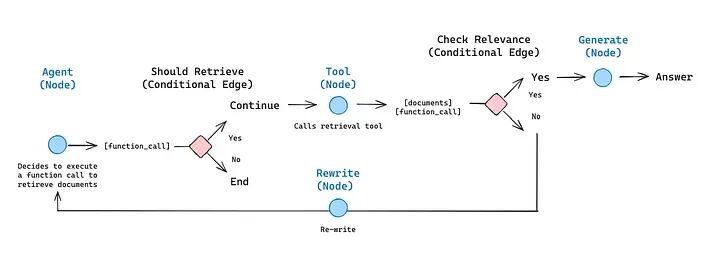
6.7 组装图
从generate_query_or_respond开始,确定我们是否需要调用retriever_tool
使用tools_condition路由到下一步:
- • 如果
generate_query_or_respond返回了tool_calls,调用retriever_tool检索上下文 - • 否则,直接响应用户
评估检索到的文档内容是否与问题相关(grade_documents)并路由到下一步:
- • 如果不相关,使用
rewrite_question重写问题,然后再次调用generate_query_or_respond - • 如果相关,继续到
generate_answer并使用带有检索文档上下文的ToolMessage生成最终响应
from langgraph.graph import StateGraph, START, ENDfrom langgraph.prebuilt import ToolNodefrom langgraph.prebuilt import tools_conditionworkflow = StateGraph(MessagesState)# Define the nodes we will cycle betweenworkflow.add_node(generate_query_or_respond)workflow.add_node("retrieve", ToolNode([retriever_tool]))workflow.add_node(rewrite_question)workflow.add_node(generate_answer)workflow.add_edge(START, "generate_query_or_respond")# Decide whether to retrieveworkflow.add_conditional_edges( "generate_query_or_respond", # Assess LLM decision (call `retriever_tool` tool or respond to the user) tools_condition, { # Translate the condition outputs to nodes in our graph "tools": "retrieve", END: END, },)# Edges taken after the `action` node is called.workflow.add_conditional_edges( "retrieve", # Assess agent decision grade_documents,)workflow.add_edge("generate_answer", END)workflow.add_edge("rewrite_question", "generate_query_or_respond")# Compilegraph = workflow.compile()
可视化图:
from IPython.display import Image, displaydisplay(Image(graph.get_graph().draw_mermaid_png()))
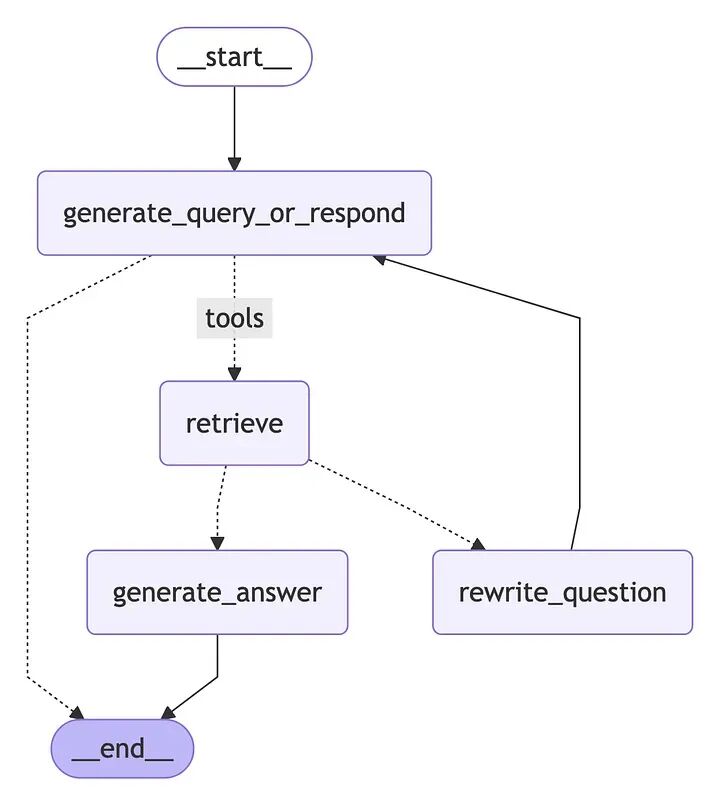
6.8 运行智能体式RAG
for chunk in graph.stream( { "messages": [\ {\ "role": "user",\ "content": "What does Lilian Weng say about types of reward hacking?",\ }\ ] }): for node, update in chunk.items(): print("Update from node", node) update["messages"][-1].pretty_print() print("\n\n")
输出:
Update from node generate_query_or_respond================================== Ai Message ==================================Tool Calls: retrieve_blog_posts (call_cZehDWOxAfSV1RQdw1RHzKwG) Call ID: call_cZehDWOxAfSV1RQdw1RHzKwG Args: query: types of reward hackingUpdate from node retrieve================================= Tool Message =================================Name: retrieve_blog_postsDetecting Reward Hacking#In-Context Reward Hacking#(Note: Some work defines reward tampering as a distinct category of misalignment behavior from reward hacking. But I consider reward hacking as a broader concept here.)At a high level, reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering.Why does Reward Hacking Exist?#Update from node generate_answer================================== Ai Message ==================================Lilian Weng categorizes reward hacking into two types: environment or goal misspecification, and reward tampering. She considers reward hacking as a broader concept that includes both of these categories. Some work defines reward tampering separately, but Weng includes it under the umbrella of reward hacking.
- 结论
从传统检索增强生成(RAG)系统到智能体式RAG的演进代表了我们在复杂现实世界应用中处理推理、检索和响应生成方式的范式转变。正如我们所探索的,智能体式RAG架构通过使智能体能够迭代推理、委托任务、自我纠正和动态适应,解锁了智能的新维度——这是传统RAG管道难以做到的。
从单智能体路由到层次化和纠正性多智能体工作流,进一步通过Agent-G和GeAR等框架将图结构和智能体式推理融合,我们现在拥有了构建真正模块化、弹性和上下文感知的检索系统的基础构建块。每个抽象层次——从自适应到文档工作流智能体——都为RAG生命周期注入了一种新的自主性和决策精细度。
然而,智能体式RAG并非万能解决方案。它需要仔细的编排、强大的提示工程、深思熟虑的分类学设计和持续的监控,以确保可靠性和可扩展性。随着该领域继续成熟,未来的机会在于标准化评估协议、构建可互操作的智能体框架,以及通过多模态和记忆增强能力推动边界。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









