



前言
在企业中部署大模型,相信各位都有 ”数据不出库“ 的需求。
想用大模型的能力,又要保证数据安全。
有 且只有一条出路:本地部署大模型。
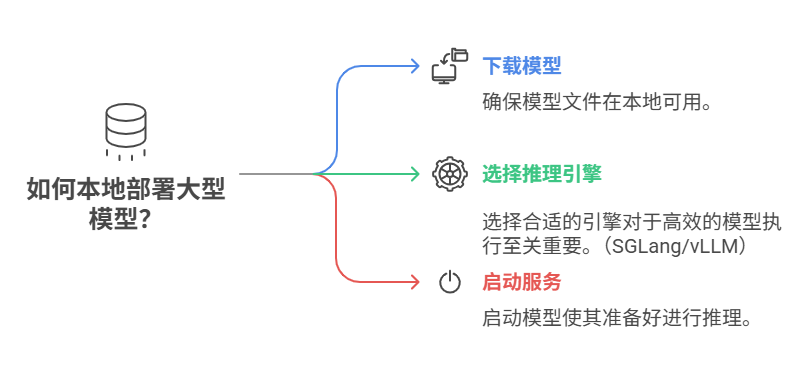
本地部署大模型,只需三步:下载模型–选推理引擎–启动服务
硬件要求
- • 显存:至少需 2*24GB(如 RTX 3090/4090)以支持 32B 模型的运行
- • 内存:建议 32GB 以上,若使用混合推理(GPU+CPU)则需更高内存
- • 存储:模型文件约 20GB,需预留 30GB 以上的硬盘空间
一、下载模型
[ModelScope / Huggingface] 两个方式,任君二选一
1.1 ModelScope
安装包
pip install -U modelscope
代码下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-32B',cache_dir='/NV/llm_models/Qwen/Qwen3-32B')
1.2 Huggingface
安装包
pip install -U huggingface_hub
添加环境变量,就不存在“需要科学”的问题
export HF_ENDPOINT=https://hf-mirror.com
代码下载
# 代码下载
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="Qwen/Qwen3-32B",local_dir='/NV/llm_models/Qwen/Qwen3-32B')
或命令行下载
huggingface-cli download Qwen/Qwen3-32B --local-dir /NV/models_hf/Qwen/QwQ-32B/
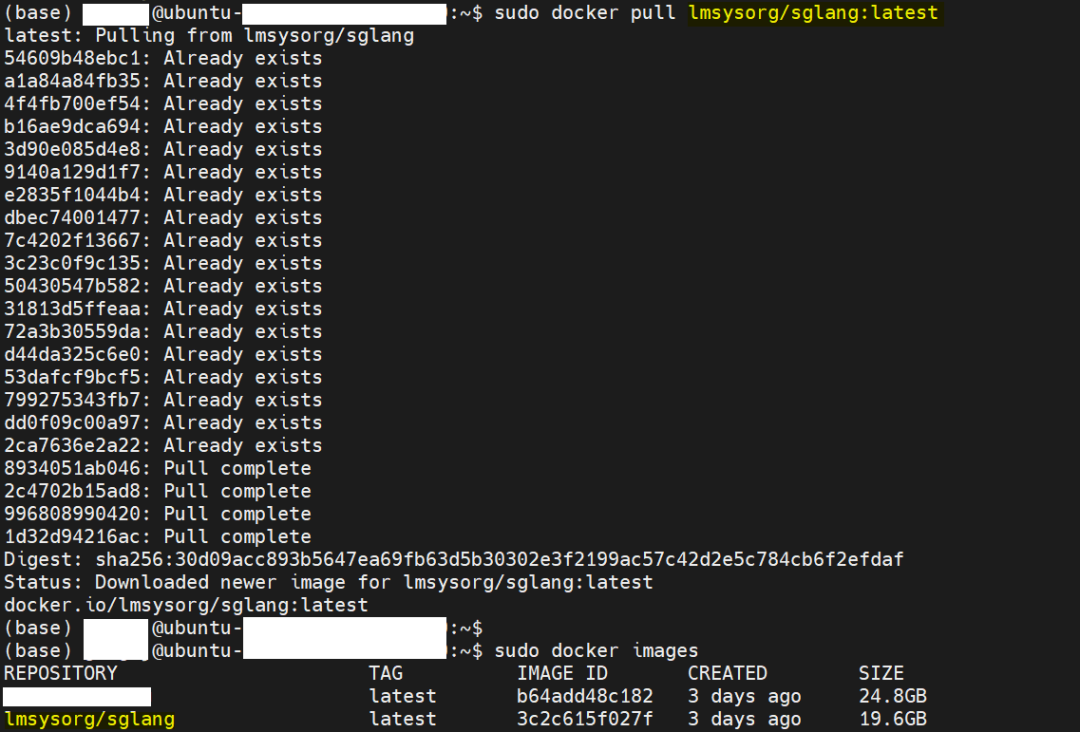
二、拉镜像
Docker-Hub官网 搜 SGLang,找到合适的镜像
默认为
docker pull lmsysorg/sglang:latest
三、启动模型
SGLang官方文档查看参数
Docker 启动命令如下:
docker run -d --gpus all \
--shm-size 32g \
-p 8001:8001 \
-v /NV/models_hf/Qwen/Qwen3-32B:/model \
--ipc=host \
lmsysorg/sglang:latest \
python3 -m sglang.launch_server \
--model /model \
--tp 4 \
--trust-remote-code \
--port 8001
基本参数
- • 启用显卡
- • 启用全部显卡:
--gpus all - • 启用指定几张卡:
--gpus '"device=0,1,2,3"'
- • 后台运行:
-d
- • 初次运行:验证是否正常启动了服务,先不使用
-d
附加参数
- • 允许外部访问:
--host 0.0.0.0 - • 指定模型名称:–served-model-name Qwen3-32B
- • 开启最大上下文长度32768:
--json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}}' --context-length 131072
四、使用Qwen3的三种方式🌐
4.1 Python调用本地Qwen3
import openai
client =openai.client(base_url="http://localhost:8001/v1",api_key="EMPTY" )
# Chat completion
response=client.chat.completions.create(
model="default",
messages=[
{"role": "system","content": "You are a helpful AI assistant"},
{"role":"user","content":"简要介绍RAG是什么?"},
],
temperature=0,
max_tokens=64,
)
print(response)
4.2 HTTP 接口请求本地Qwen3
curl --location --request POST 'http://127.0.0.1:8001/v1/chat/completions' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "Qwen/Qwen3-32B",
"messages": [
{"role": "user", "content": "请用一句话介绍你自己"}
],
"temperature": 0.7,
"max_tokens": 512
}'
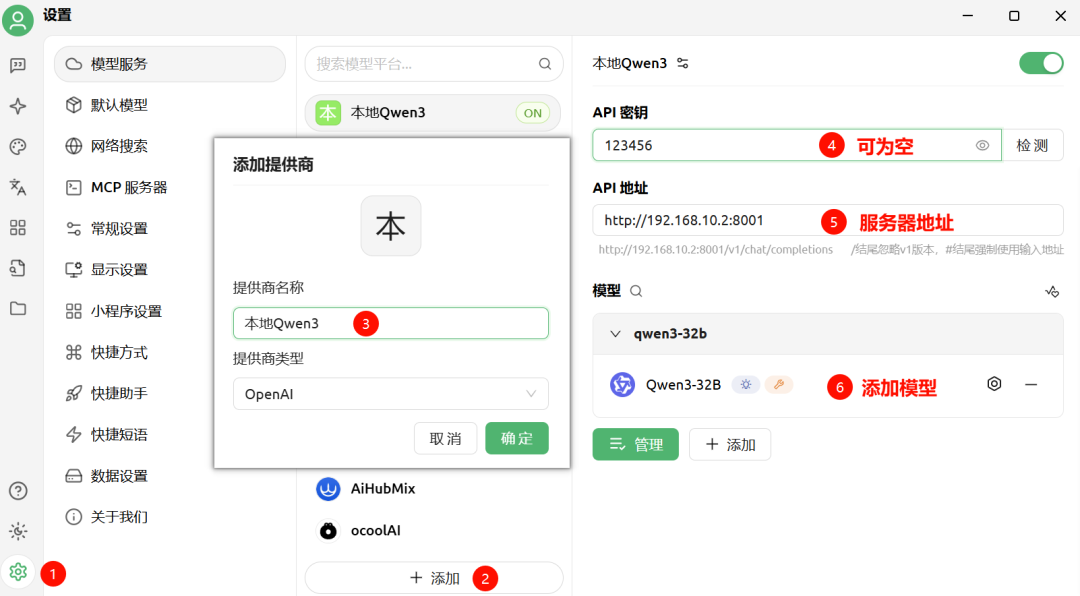
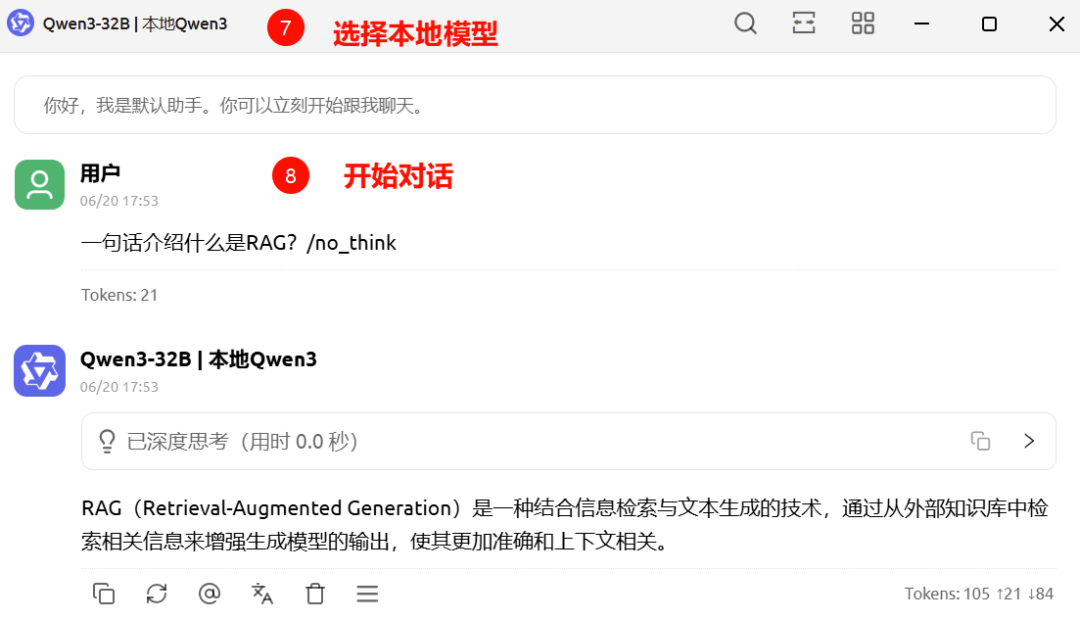
4.3 客户端使用本地Qwen3
以CherryStudio为例
4.4 查看推理速度
找到你的容器id
sudo docker ps # 如0d5faf88f505
查看容器的日志
sudo docker logs 0d5faf88f505 # 如需实时查看,加个-f
以下是 逐行解析 启动命令的含义和作用,按需查看。
🐳 docker run 是什么?
这是启动一个 Docker 容器的命令。你可以把它理解为“运行一个已经打包好的应用环境”。
🔧 参数详解
✅ --gpus all
- • 启用所有 GPU(NVIDIA 显卡),让容器可以访问你的 CUDA 设备。
- • 需要安装好
nvidia-docker2。
✅ --shm-size 32g
- • 设置共享内存大小为 32GB。
- • 某些模型推理需要较大的共享内存空间,特别是大规模模型(如 DeepSeek-V3)。
- • 默认共享内存较小(64MB),不足以支持大模型推理。
✅ -p 8001:8001
- • 将宿主机(也就是你当前系统的)端口
8001映射到容器内部的8001端口。 - • 用于通过浏览器或 API 访问服务:
http://localhost:8001
✅ /NV/models_hf/Qwen/Qwen3-32B:/model
- • 将宿主机上的 HuggingFace 缓存目录挂载到容器中的
/model。 - • 目的是:
- • 共享模型缓存,避免重复下载
- • 加快下次加载模型的速度
示例路径说明:
- • 宿主机路径:
/NV/models_hf/Qwen/Qwen3-32B→ 当前用户的HuggingFace 缓存目录- • 容器路径:
/model→ 容器中 root 用户的缓存路径
✅ --ipc=host
- • 使用宿主机的 IPC(进程间通信)命名空间。
- • 大模型推理时可能涉及多进程通信,使用这个参数可以避免 IPC 资源限制问题。
🖼️ lmsysorg/sglang:latest
这是你要运行的镜像名称和标签:
- •
lmsysorg/sglang: SGLang 的官方镜像 - •
latest: 最新版本的 tag
🚀 python3 -m sglang.launch_server
这部分是容器启动后执行的命令,用来启动 SGLang 服务。
参数解释
--model /model
- • 加载 HuggingFace 上的模型
/model - • 如果本地没有这个模型,SGLang 会自动从 HF 下载并缓存到之前挂载的目录中
--tp 4
- •
tp= Tensor Parallelism(张量并行) - • 表示使用 4 个 GPU 并行推理(适用于多卡服务器)
- • 如果你只有 2 张卡,请设置为
--tp 2
--trust-remote-code
- • 允许加载远程代码(某些模型依赖自定义代码实现)
- • 如不加此参数,可能会报错:
This repository requires custom code
--port 8001
- • 指定服务监听的端口号(与前面的
-p对应)
📦 小结:整个命令的作用
| 功能 | 说明 |
|---|---|
| 使用 GPU | 支持深度学习加速 |
| 共享内存 32G | 支持大规模模型推理 |
| 挂载模型缓存 | 避免重复下载模型 |
| 映射端口 | 通过 REST API 访问模型服务 |
| 启动 SGLang 服务 | 加载 Qwen3-32B 模型并提供推理接口 |
实践出真知,与君共勉。
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取


















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









