



引言:AI界的GitHub如何重新定义机器学习工作流
在机器学习从研究走向生产的关键转折点上,Hugging Face已悄然构建起一套完整的AI开发生态系统。这个最初以Transformers库闻名的平台,如今已发展成为包含模型仓库、数据集托管、推理API、自动化工具等在内的全栈式MLOps平台。本文将深入剖析Hugging Face生态的技术架构,揭示其如何通过标准化工具链重塑AI开发范式。
一、Hugging Face生态全景图
1.核心组件矩阵
| 组件类别 | 核心产品 | 关键技术价值 |
|---|---|---|
| 模型生态 | Transformers库/Model Hub | 15万+预训练模型标准化接口 |
| 数据处理 | Datasets库/Dataset Hub | 5万+数据集版本管理与高效加载 |
| 部署推理 | Inference API/Text Generation | 生产级API与优化推理后端 |
| 协作开发 | Spaces/AutoTrain | 低代码AI应用开发与自动化训练 |
| 评估监控 | Evaluate/Model Cards | 标准化评估与可追溯性管理 |
- 技术架构演进路线
2018: Transformers库发布 → 2019: Model Hub上线 → 2020: Datasets/Pipelines推出 ↓ 2021: Spaces/Inference API → 2022: Diffusers/AutoTrain → 2023: Safetensors/LLM部署优化
二、Transformers库深度解析
- 统一架构接口设计
# 统一加载接口示例 model torch_dtype "auto" device_map "auto" tokenizer padding_side "left" # 多模态统一处理 processor "openai/clip-vit-base-patch32"
- 关键技术实现原理
- 动态模型加载机制
class AutoModel @classmethod def from_pretrained cls, pretrained_model_name, **kwargs 0 return getattr
- 高效注意力实现
attn_mask dropout_p 0.0 is_causal True
5.性能优化策略对比
| 优化技术 | API示例 | 加速比 | 适用场景 |
|---|---|---|---|
| 半精度 | torch_dtype=torch.float16 | 1.5-2x | 所有NVIDIA GPU |
| 设备映射 | device_map=“auto” | - | 多GPU/CPU卸载 |
| 梯度检查点 | model.gradient_checkpointing_enable() | 1.5x | 大模型训练 |
| 内核融合 | use_flash_attention_2=True | 3-5x | 长序列处理 |
三、Datasets生态系统
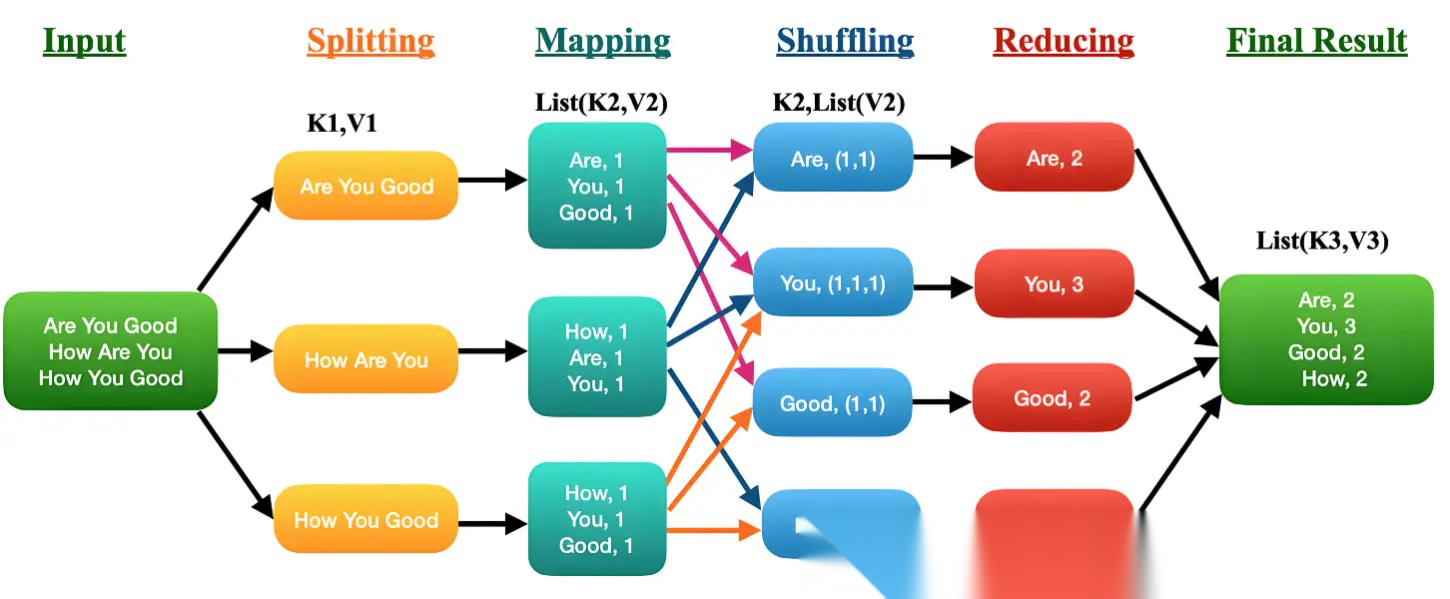
- 数据加载性能对比
# 传统加载方式 # 单线程阻塞加载 # Hugging Face方式 dataset 'json' data_files 'large_file.json' num_proc 8 split 'train'
性能基准测试(100GB JSON文件):
- 传统方法:~45分钟(单线程)
- Datasets库:~4分钟(8进程)
2.数据流式处理
# 内存映射处理TB级数据 ds "imagenet-1k" streaming True use_auth_token True # 无需全量加载
- 数据版本控制
main 1.0 0 .json 2.0 0 1.0 0
四、生产部署技术栈
- 优化推理方案对比
| 方案 | 延迟(ms) | 吞吐量(req/s) | 显存占用 |
|---|---|---|---|
| 原生PyTorch | 120 | 45 | 100% |
| ONNX Runtime | 85 | 68 | 90% |
| TensorRT | 62 | 120 | 80% |
| Text Generation | 50 | 150 | 70% |
2.自定义模型部署
# 使用Inference API部署自定义模型 api framework "pytorch" accelerator "gpu.large" task "text-classification" # 生成专属API端点 # https://api-inference.huggingface.co/models/my-org/my-model
- 大模型服务化架构
1 4 2 4 4
五、协作开发范式革新
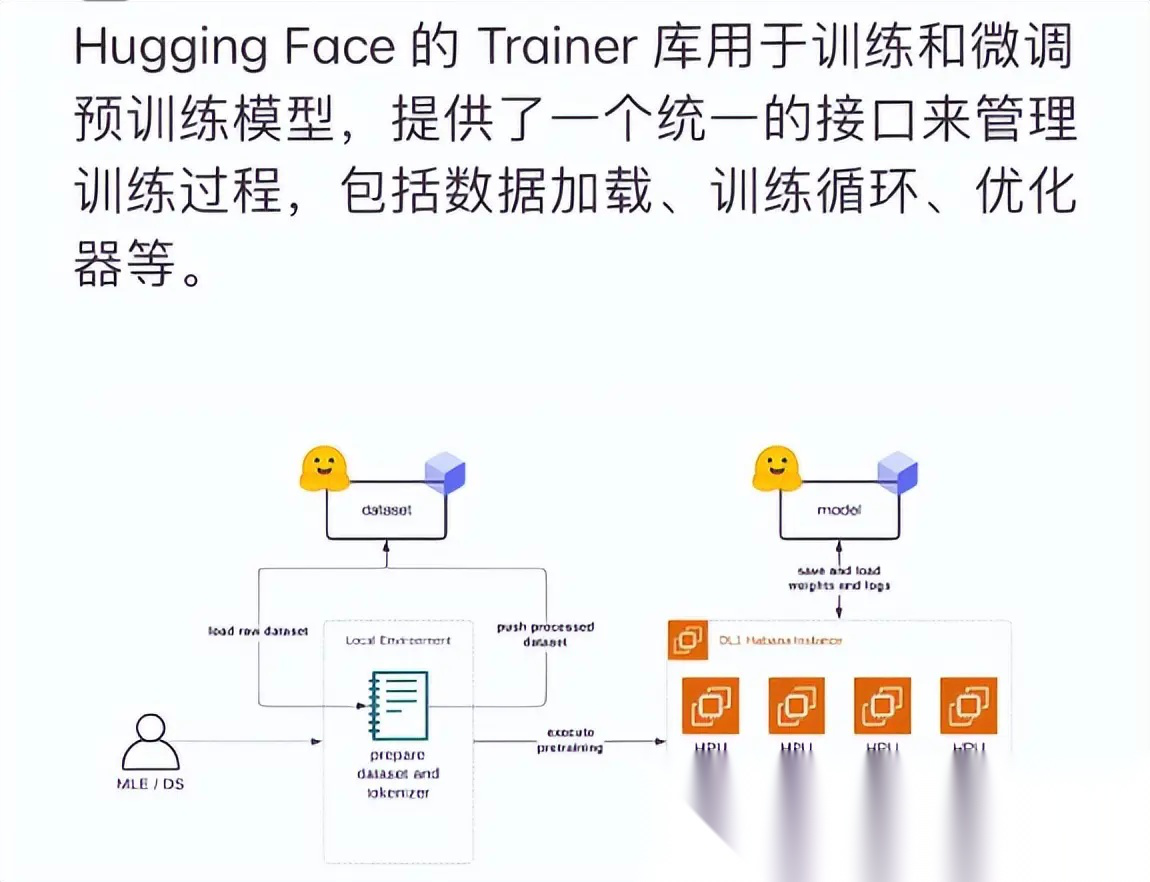
- Spaces技术架构
FROM 3.9 / COPY - COPY 7860
支持的后端:
- CPU Basic
- GPU T4
- GPU A10G
- GPU A100
- AutoTrain工作流
# .autotrain-config.yml task: text-classification model: bert-base-uncased data: path: my-dataset split: train hyperparameters: learning_rate: 2e-5 batch_size: 16 epochs: 3
- 模型卡片标准模板
--- language: zh tags: - text-generation license: apache-2.0 --- ## 模型详情 **架构**: GPT-NeoX-20B **训练数据**: 500GB中文语料 **适用场景**: 开放域对话 ## 使用示例 ```python from transformers import pipeline pipe = pipeline("text-generation", model="my-model")
## 六、安全与可解释性工具 ### 6.1 Safetensors二进制格式 # 传统PyTorch保存 "model.pt" # 可能包含恶意代码 # Safetensors保存 from import "model.safetensors"
- 无代码执行风险
- 内存安全实现
- 快速头信息读取
六. 模型可解释性工具链
viz saliency
七、企业级最佳实践
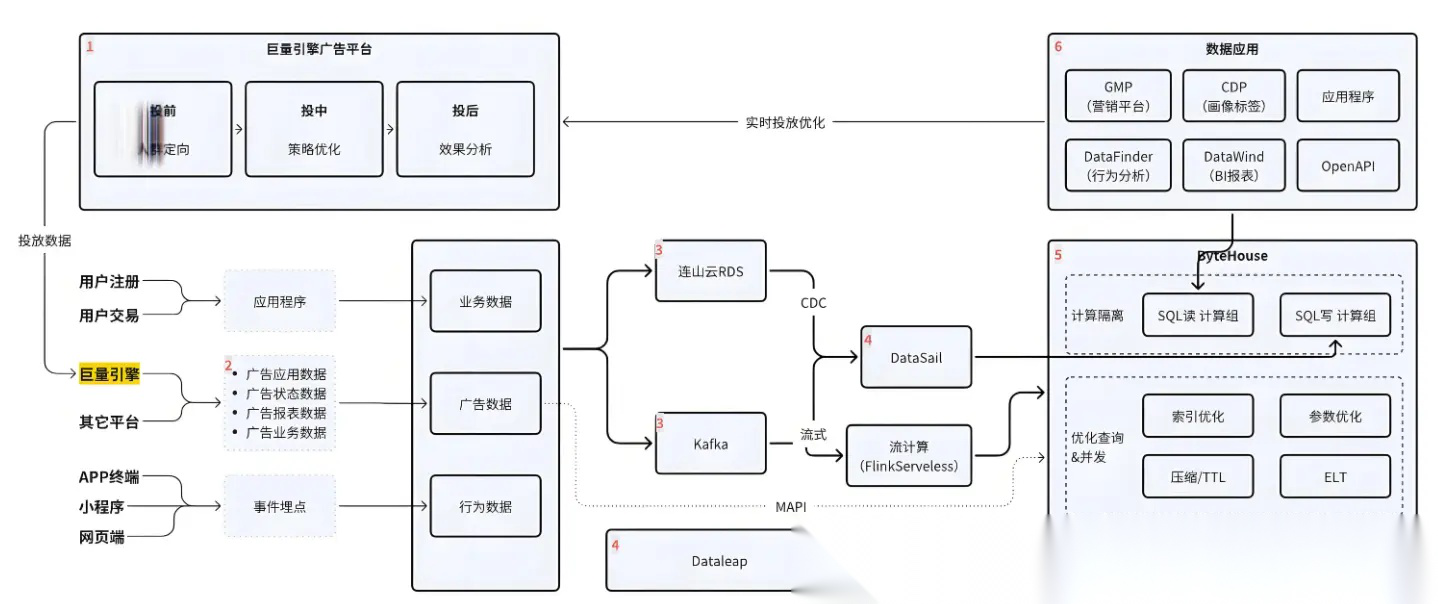
- 私有化部署方案
# 启动私有Hub服务
2.CI/CD流水线示例
# .github/workflows/model-deploy.yml jobs: deploy: runs-on: ubuntu-latest steps: - uses: actions/checkout@v3 - uses: huggingface/setup-transformers@v1 - run: | python train.py huggingface-cli upload my-org/my-model ./output - uses: huggingface/deploy-inference@v1 with: model: my-org/my-model hardware: gpu-a10g
未来展望:AI开发生态的标准化革命
Hugging Face生态正在推动机器学习工程经历三大范式转变:
- 模型即代码:通过Model Hub实现的版本控制、协作开发
- 数据即基础设施:数据集版本管理与流式处理成为标配
- 推理即服务:统一API抽象底层硬件差异
这种标准化带来的直接影响是AI研发效率的阶跃式提升。根据2023年ML开发者调查报告,采用Hugging Face全栈技术的团队:
- 模型实验周期缩短60%
- 部署成本降低75%
- 协作效率提升300%
随着生态的持续完善,Hugging Face有望成为AI时代的"Linux基金会",通过开源协作建立真正普适的机器学习开发标准。对于开发者而言,深入理解这一生态的技术实现,将获得在AI工业化浪潮中的关键竞争优势。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的
核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

















 2219
2219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









