



引言:超越传统提示的局限性
在早期的大语言模型(LLM)应用中,提示工程(Prompt Engineering)是连接用户意图与模型输出的核心手段。然而,纯提示驱动的方案在多步推理、工具调用和动态环境交互中常显不足。ReAct框架(Reasoning+Acting)应运而生,通过将链式推理(Reasoning) 与环境行动(Acting) 结合,构建出能主动思考、决策并执行复杂任务的智能体(Agent)。
一、ReAct的核心设计思想
- 推理(Reasoning)模块
- 动态思考链(Chain-of-Thought) :Agent在每一步生成自然语言推理逻辑,解释当前决策原因(如:“用户需要查天气,需先获取位置信息”)。
- 错误回溯机制:当行动失败时,Agent能分析原因并调整策略(如:“API返回错误,可能是参数格式问题,重试前需校验输入”)。
- 行动(Acting)模块
- 工具集成(Tool Calling) :调用外部API、数据库、计算器等(如:search_weather(location=“Beijing”))。
- 环境状态感知:实时接收行动结果,作为下一步决策的输入(如:“获取到北京气温25°C,建议用户带薄外套”)。
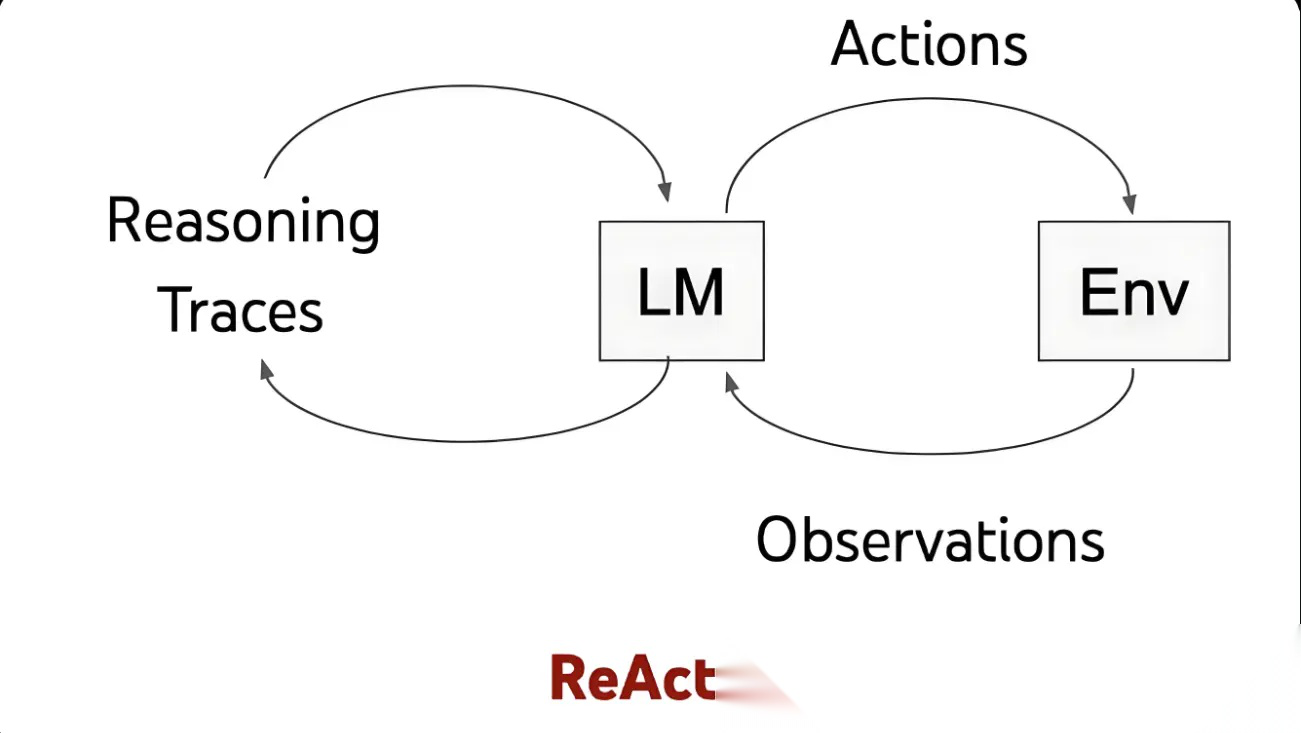
3.交互闭环:Reasoning与Acting的循环
ReAct的执行流程形成自迭代循环:
Final
每一次循环都将环境反馈纳入推理,实现动态适应复杂场景的能力。
二、技术优势:为什么ReAct优于传统Agent?
- 解决LLM的“幻觉”问题
传统Agent可能盲目执行错误指令,而ReAct的显式推理步骤让决策过程可追溯,减少无依据输出。
案例:当用户问“爱因斯坦最近的推特说了什么?”,ReAct会先推理:“爱因斯坦已去世,需搜索历史资料库而非实时社交媒体”。
- 支持长任务分解
复杂任务被拆解为原子化推理-行动对(ReAct Pair)执行:
# 用户请求:“分析特斯拉过去一年的股价趋势并总结原因” Steps: 1. Thought: 需要特斯拉股票代码 → Action: search_stock_symbol("Tesla") 2. Observation: 获得代码TSLA 3. Thought: 查询过去一年股价 → Action: get_stock_data("TSLA", period="1y") 4. Observation: 接收时间序列数据 5. Thought: 调用数据分析模型 → Action: analyze_trend(data)
3.无缝集成领域工具
通过工具注册机制(如LangChain Tools),Agent可灵活扩展能力边界:
tools "web_search" # 自定义Python计算器 agent
三、架构实现:从理论到代码
- 核心组件拆解
| 模块 | 功能说明 | 实现示例 |
|---|---|---|
| LLM Core | 生成推理与行动指令 | GPT-4、Claude 3、Llama 3 |
| Tool Engine | 工具调度与执行 | LangChain Tools, LlamaIndex |
| Memory | 存储历史观察与推理链 | Redis、向量数据库 |
| Parser | 解析LLM输出为结构化操作 | Pydantic + 正则表达式 |
- 代码片段:简易ReAct循环实现
from import from import def web_search query: str str # 调用搜索API return f"Results about {query}" "Search" "Search the web" 0 "巴黎埃菲尔铁塔高度是多少米?" for in range 3 # 最大迭代步数 if "Final Answer" in print break else # 执行Action并更新环境反馈 f"\nObservation: {action_result}"
四、挑战与优化方向

- 现实瓶颈
- 推理漂移(Reasoning Drift) :长任务中思维链可能偏离目标。
解法:加入强化学习奖励机制(如PPO)对齐目标。 - 工具依赖风险:API失败导致任务中断。
解法:构建Fallback策略,如重试、替换工具或请求人工干预。
- 前沿探索
- 多智能体协同(ReAct Swarm) :多个Agent分工协作处理子任务。
- 推理压缩(Reasoning Distillation) :将复杂推理链蒸馏为更高效的微调模型。
结论:走向自我进化的智能体
ReAct不仅是工具调用框架,更代表着LLM从内容生成向决策智能的跨越。随着开源框架(如LangChain, AutoGPT)的成熟和LLM推理能力提升,ReAct Agent将在自动编程、智能运维、科研辅助等领域释放巨大潜力。未来,融合记忆增强、多模态感知和人类反馈的下一代ReAct架构,有望实现真正的通用任务自主智能体。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的
核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

















 1606
1606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









