



在前两篇文章中,我们聊了 RAG 的核心概念和它为什么能成为大模型开发的 “刚需技术”
今天,咱们直接上干货 —— 用迪士尼客服的真实场景当例子,手把手教你搭一个能实际干活的 RAG 系统。从文档处理到最终回答用户问题,每一步都拆解得明明白白,代码思路 + 操作逻辑全公开,看完就能跟着做!
先明确目标:我们要做一个什么系统?
想象一下,迪士尼客服每天要回答上百个问题:“门票能退吗?”“年卡怎么续?”“园区里有婴儿车租赁吗?”…… 这些问题答案都藏在官方文档里,但让大模型死记硬背显然不现实。
我们要搭的 RAG 系统,就是让大模型 “带着答案库上班”:用户问啥,系统先从文档里找出相关内容,再基于这些内容生成回答。既避免大模型 “瞎编”,又能随时更新知识(比如门票政策变了,换份文档就行)。
RAG 系统 3 大核心组件 + 完整流程
整个系统的逻辑其实很简单,就像咱们 “查资料→整理→回答” 的过程,拆解成 3 大模块和 8 个步骤:
核心组件:文档处理模块、向量化与索引模块、检索增强模块
完整流程:文档→解析→语义切片→向量化→索引→检索→Prompt→生成
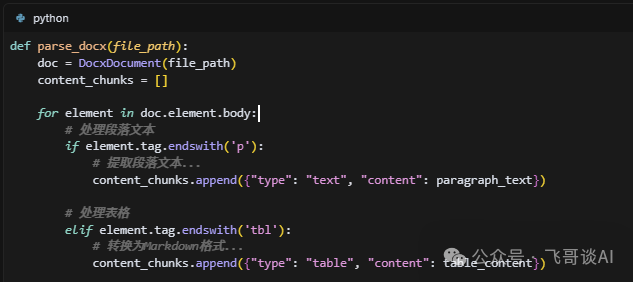
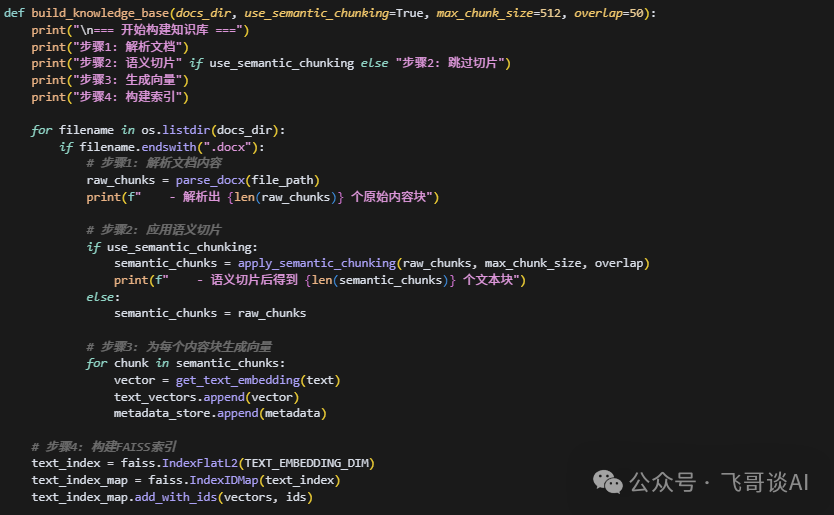
1. 先把文档 “拆解开”
用Python-docx库读取 Word 文档(如果是 PDF / 图片,可用PyPDF2或 OCR 工具),重点是保留原始结构:
-
段落按顺序提取,标题标清楚层级(比如 “1. 门票退款”“1.1 退款条件”);
-
表格转换成 Markdown 格式(比如
| 票种 | 退款期限 |),方便后续处理。
这里作为展示只是使用了文本知识库,实际项目中也可以读取图片等多媒体资料。
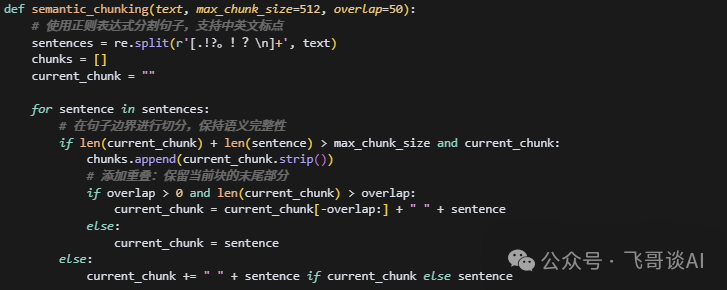
2. 再做 “语义切片”(关键!)
文档太长怎么办?切成小块(叫 “chunk”),但不能乱切:
- 切在句子结尾
:比如 “门票支持退款。/ 申请需提前 3 天。” 用句号拆分,避免把一句话砍成两半;
- 留重叠内容
:比如前一块结尾是 “退款需通过官方 APP”,后一块开头重复这句,保证上下文连贯;
- 表格不拆
:完整保留,不然数据就乱了。
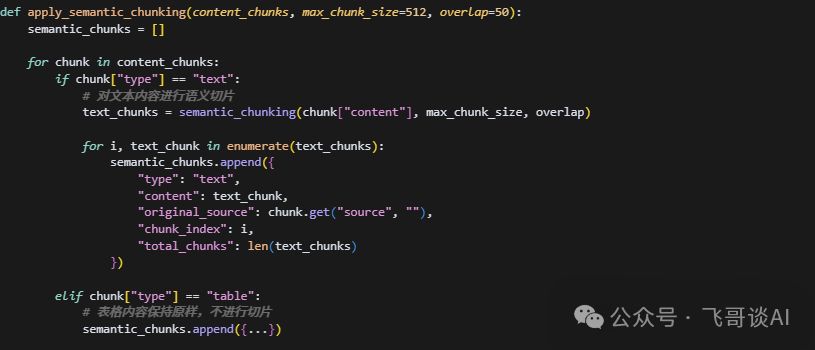
3. 给每个 chunk “贴标签”
每个小块都要加元数据,比如:
来源:迪士尼门票政策2025.docx
页码:第8页
索引ID:chunk_008
这样后续用户问 “这个答案哪来的”,能直接溯源,也方便以后更新知识库。
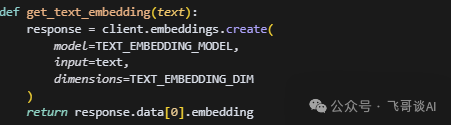
Step 2:向量化与索引 —— 让知识 “可检索”
处理好的文本还是 “文字”,计算机看不懂。这一步要把它们变成 “数字”,再存到专门的数据库里。
1. 文本→向量:给文字 “编密码”
用向量化模型把每个 chunk 转换成一串数字(叫 “embedding”)。比如:
-
用阿里通义的
DashScope API,生成 1024 维向量(简单理解:维度越高,细节越丰富); -
也可以用 OpenAI 的
text-embedding-ada-002(需科学上网),生成 1536 维向量。
原理很简单:语义相似的句子,向量也相似。比如 “退款流程” 和 “如何退票” 的向量会靠得很近。
Step 2:向量化与索引 —— 让知识 “可检索”
处理好的文本还是 “文字”,计算机看不懂。这一步要把它们变成 “数字”,再存到专门的数据库里。
1. 文本→向量:给文字 “编密码”
用向量化模型把每个 chunk 转换成一串数字(叫 “embedding”)。比如:
-
用阿里通义的
DashScope API,生成 1024 维向量(简单理解:维度越高,细节越丰富); -
也可以用 OpenAI 的
text-embedding-ada-002(需科学上网),生成 1536 维向量。
原理很简单:语义相似的句子,向量也相似。比如 “退款流程” 和 “如何退票” 的向量会靠得很近。
2. 建索引:把向量 “存起来”
用 Meta 的FAISS库建向量数据库(专门用来快速搜相似向量的工具)。就像给图书馆的书编目录,以后用户提问,能秒速找到最相关的 chunk。
Step3:RAG问答流程
Step 3:检索增强 —— 让大模型 “照着答案说”
终于到了回答用户问题的环节!这一步的核心是:不让大模型 “瞎想”或者漫天漫地去找答案,只让它 “照着找来的资料说”。
1. 先找相关资料
用户问 “迪士尼门票怎么退?”,系统会:
-
把问题转换成向量;
-
用 FAISS 在数据库里搜最相似的 3 个 chunk(比如关于退款条件、申请方式、到账时间的内容)。
2. 给大模型 “划范围”
把找到的 chunk 当 “背景知识”,写一个严格的 Prompt:

3. 让大模型 “按格式答”
顺便告诉大模型输出格式,比如分点说明,这样用户看得清楚。
将检索的文档作为背景知识(context)来构建增强的prompt来限定大模型只在知识库里寻找答案,结构化背景知识和用户问题,避免幻觉。

根据检索到的文档生成答案
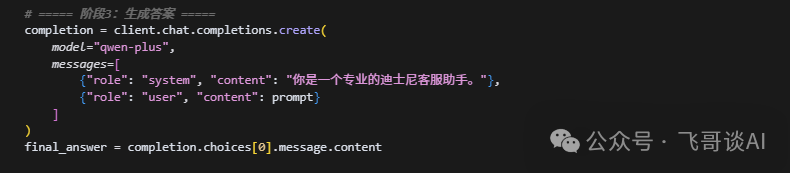
这里告诉大模型生成答案的格式。
好的经过这四大步骤一个迪士尼的客服RAG系统就构建完毕了!
现在我们看看演示效果吧!
演示效果:真能答对吗?
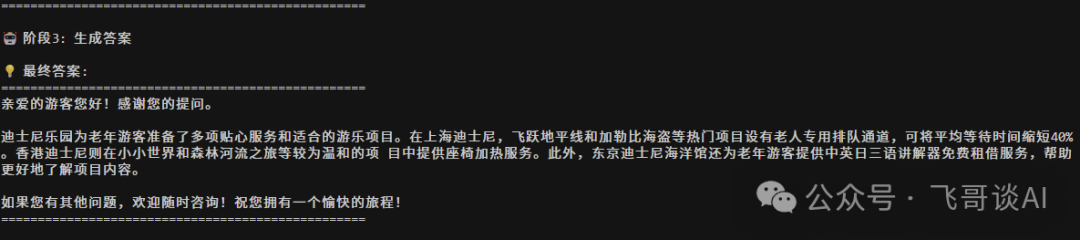
用迪士尼公开资料搭好知识库后,我们试下这个问题:“迪士尼有适合老人玩项目嘛?”
第一步: 构建知识库
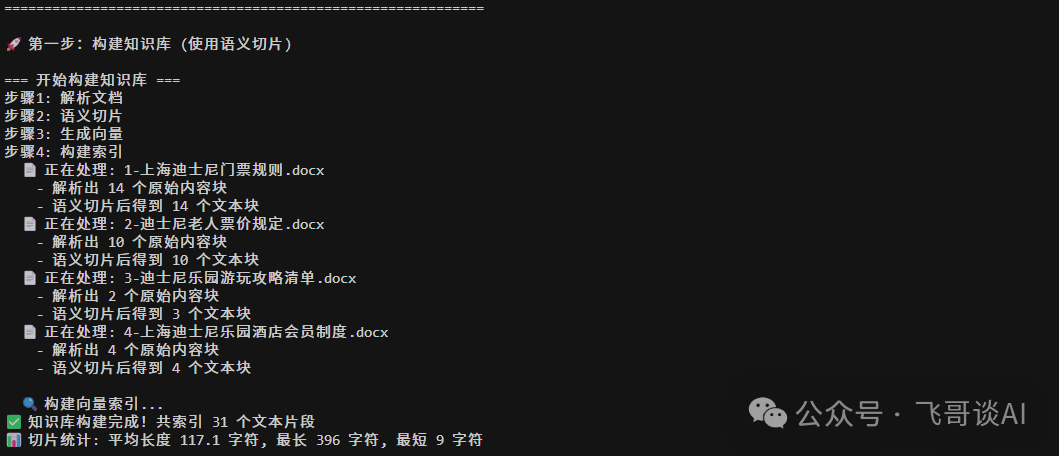
第二步:检索到 3 个相关 chunk
知识库构建好后,就是问答演示。此处以用户问题:“我想了解一下迪士尼门票的退款流程“为例。
根据用户问题,在向量数据库中检索到最相关的三个chunk。

第三步: 重构Prompt
告诉大模型该怎么回答用户问题
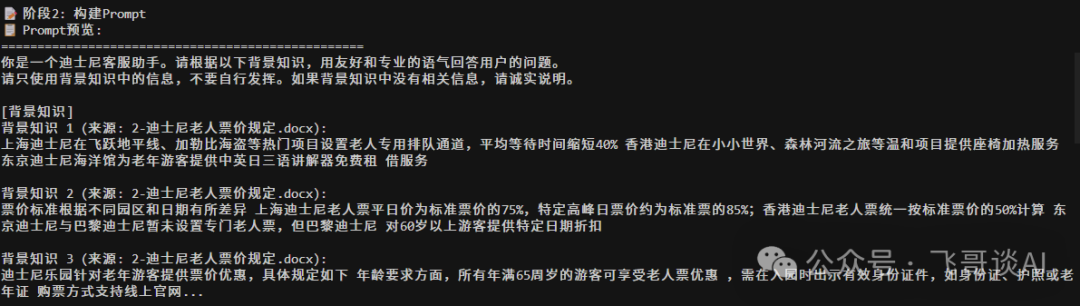
第四步:生成答案!
大模型根据规定的输出格式输出答案
总结:3 步搭好自己的 RAG 系统
- 文档处理
:拆文档、切 chunk、加标签;
- 向量化与索引
:转向量、存 FAISS;
- 检索增强
:搜资料、写 Prompt、生成答案。
至此一个完整的RAG问答系统构建完成。是不是没想象中难?哪怕是 AI 小白,跟着步骤走也能搭起来。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
第一不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









