 Mac部署新版Qwen3-30B模型指南
Mac部署新版Qwen3-30B模型指南




前言:
-
先讨论一个灵魂问题:御三家旗舰模型那么好的情况下,为什么还要部署本地版的小模型?
确实是这样,除非迫不得已,否则我还是不推荐大家使用开源模型。生产力场景,模型能力差一点,就会多N个错误,增加的Debug和代码review的时间成本和隐藏风险,是大家不愿意承受的。
那么哪些情况是必须要本地模型的呢?
-
我自己思考了一下,个人用户最先考虑的就是NSFW的场景,这些内容一方面不适合传出去,另外一方面,商业模型也会有比较强的拒绝限制。比如说,我一直想做AI女友,那么我肯定也不希望这些数据传到别人的服务器上。
-
生产力方面,一些个人的隐私数据,也不太适合外传,比如说个人本机文件的一些RAG,一些个人的聊天记录的处理;
-
代码生成这块,暂时还是很难在个人电脑上有一个vibe coding的模型。我个人认为至少得达到sonnet4的水平,才能做好vibe coding。具体来说,它可以支持200K左右的上下文输入,支持64K的输出,支持多轮持续对话智力下降不明显。四千行的输入,五百行的输出无报错,一些报错情况,可以通过报错信息,一次性改对。这样的模型能力,才好做托管。我能想到的只有代码补全这一个场景。但我目前也很少用代码补全,因为我基本上都是整段输入,整段输出。
7月新发布的qwen3-235b旗舰模型也许可以做到一些,但30B的我估计还是不太行的。
-
第二个问题,我前段时间一直在纠结,如果本地跑LLM,那么该买什么设备?
我自己有一个24G的3090,一个20G的3080魔改版,但实际上这两张显卡,都只能跑点很小的模型,14B的int8就顶天了,14B的int8的智力又很有限,别说生产力了,连基础的文本处理能力都没有。
由于被美帝和老黄狠狠制裁,大显存的NVIDIA显卡基本上都是金子做的,目前来看性价比比较高的只有2.2w左右的魔改版48G-4090,但多数都是涡轮版,噪声较大,就不太方便个人使用了,即便如此,这个也只能跑点30B-int8,或者勉强部署70B-int4的模型。
前段时间看朋友提到了老黄的陈年老饼,DGX Spark,说的是两万多人民币的个人小主机,可以跑200B大模型,给我唬的一愣一愣的。后面有朋友给我泼了一盆冷水,我也查了一下,dgx是统一128G内存,功耗低,体积小,但显存带宽比较低,只有273 GB/秒,最关键的是它到现在还是期货,而且可能会对中国禁售。
相比之下,4090的带宽是1008 GB/s。同样是统一内存,MacBook Pro的M3 Pro是150GB/s,M3 Max的内存带宽则是有300-400GB/s,最新的M4 Pro 芯片的则为273GB/s。另外一个就是AMD的统一内存,但这个我不太了解,以及A家的卡,生态我不好评价。
前几天刚好千问3的新版发布了,榜刷的吓人,我又担心像上次那样,只是针对榜单的优化,但几个群友给的反馈都还好,尤其是@博洋说Mac本地部署int4的模型,都可以有接近GPT4o的水平。这下不得不试试了,准备系统测试一下Mac部署千问3-30B的使用。
闲话到此为止,后面按照下面的大纲介绍部署和测试的内容:
个人玩家-Mac部署新版Qwen3-30B模型不完全指南:
-
硬件配置: MacBook Pro14英寸,芯片TApple M3 Pro内存 36 GB
-
软件下载: https://lmstudio.ai 官网下载M系芯片对应的安装包,正常安装即可。 七月最新改变:支持个人和商业免费试用。
-
安装后,点击右下角的设置,APP setting,语言,选择简体中文,方便后面操作。
-
在Model search 里面搜索模型下载,推荐qwen3-coder-30b和qwen3-30b-a3b-2507,选择MLX格式的。 这个下载还要等一会儿的,看大家的网络条件了。
下载完后,进入主界面
-
左下角,选择开发者模式。正上方,选择模型,点击模型,设置上下文长度,如果内存够的话,可以拉高一点,勾选保存设置,加载模型即可。
-
正常的对话界面进行文本对话。
-
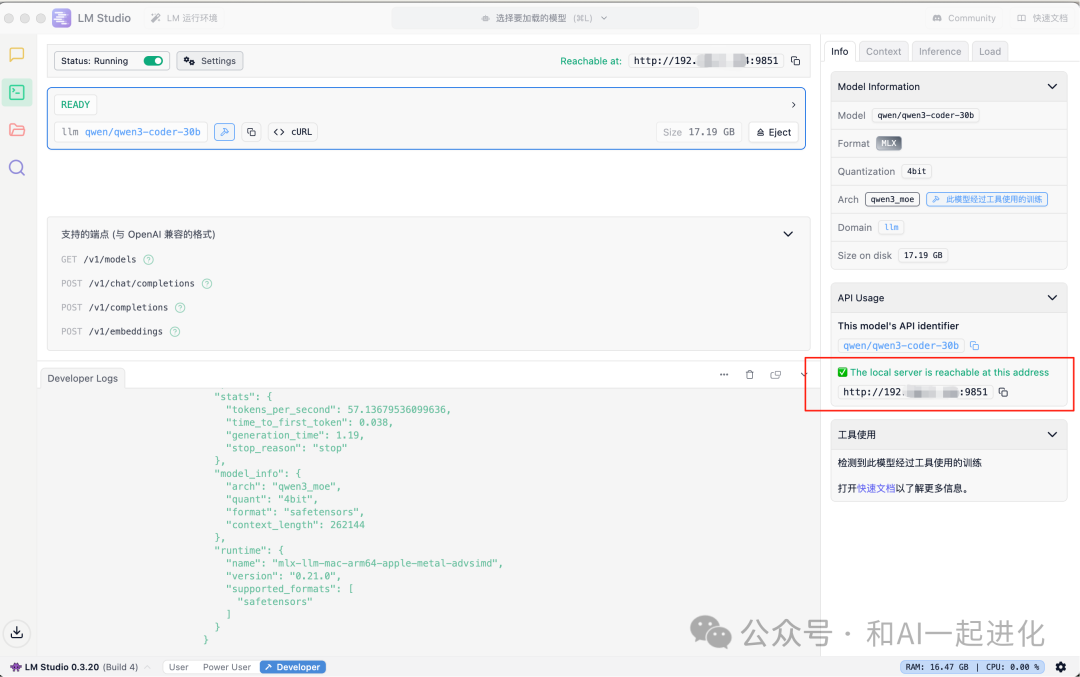
左边一列的第二个是开发者,用于设置API访问的内容。
首先打开Status: Running,然后点击settings,配置访问端口,可以点击cros跨域访问;右边是你的局域网的访问域名和端口;
配置API访问的界面
-
贴一下API访问的Python代码:
# -*- coding: utf-8 -*-
# ai_models/lm_model.py —— LM Studio 本地部署 Qwen 模型调用(支持流式回调 + token & 耗时统计)
import asyncio
import os
import inspect
from typing import Optional, Callable, Dict, Any
import aiohttp
import json
import time
class QwenModelConfig:
"""
封装 LM Studio 本地部署的 Qwen 模型(支持 qwen3-30b-a3b-2507 和 qwen3-coder-30b)。
使用 LM Studio 的 REST API (beta) 接口。
支持流式输出、同步/异步回调、token 统计与耗时分析。
"""
def __init__(
self,
model_name: str = "qwen/qwen3-30b-a3b-2507", # 可选: "qwen/qwen3-30b-a3b-2507" 或 "qwen/qwen3-coder-30b"
host: str = "192.168.1.104",
port: int = 9851,
system_prompt: str = "You are a helpful assistant.",
timeout: int = 300
):
self.host = host
self.port = port
self.base_url = f"http://{host}:{port}"
self.model_name = model_name
self.system_prompt = system_prompt
self.timeout = timeout
self.session: Optional[aiohttp.ClientSession] = None
# 模型名验证
valid_models = [
"qwen/qwen3-30b-a3b-2507",
"qwen/qwen3-coder-30b"
]
if model_name not in valid_models:
raise ValueError(
f"不支持的模型名称!请从以下模型中选择:{valid_models}"
)
async def __aenter__(self):
self.session = aiohttp.ClientSession(timeout=aiohttp.ClientTimeout(total=self.timeout))
return self
async def __aexit__(self, exc_type, exc_val, exc_tb):
if self.session:
await self.session.close()
async def _get_available_models(self) -> list:
"""获取 LM Studio 本地加载的模型列表"""
url = f"{self.base_url}/api/v0/models"
try:
async with self.session.get(url) as resp:
if resp.status != 200:
raise ConnectionError(f"获取模型列表失败: {resp.status} - {await resp.text()}")
data = await resp.json()
return [m["id"] for m in data.get("data", [])]
except Exception as e:
raise ConnectionError(f"连接 LM Studio API 失败: {e}")
async def _check_model_loaded(self) -> bool:
"""检查指定模型是否已加载"""
available_models = await self._get_available_models()
return self.model_name in available_models
async def _get_model_info(self) -> Dict[str, Any]:
"""获取指定模型的详细信息"""
url = f"{self.base_url}/api/v0/models/{self.model_name}"
try:
async with self.session.get(url) as resp:
if resp.status != 200:
raise ConnectionError(f"获取模型信息失败: {resp.status} - {await resp.text()}")
return await resp.json()
except Exception as e:
raise ConnectionError(f"连接模型信息接口失败: {e}")
async def _estimate_tokens(self, text: str) -> int:
"""简单的 token 估算(中文约 1.5 字符/token,英文约 4 字符/token)"""
if not text:
return 0
# 统计中文字符数
chinese_chars = sum(1 for char in text if '\u4e00' <= char <= '\u9fff')
other_chars = len(text) - chinese_chars
# 估算 token 数:中文 1.5 字符/token,其他 4 字符/token
estimated_tokens = int(chinese_chars / 1.5 + other_chars / 4)
return max(estimated_tokens, 1)
async def process_input(
self,
prompt: str,
model_name: Optional[str] = None,
temperature: float = 0.7,
max_tokens: int = 1024,
stream: bool = True,
on_stream: Optional[Callable[[str], None]] = None
) -> "QwenResponse":
model = model_name or self.model_name
messages = [
{"role": "system", "content": self.system_prompt},
{"role": "user", "content": prompt}
]
# 检查模型是否可用
if not await self._check_model_loaded():
raise RuntimeError(
f"模型 '{model}' 未加载到 LM Studio,请先在 LM Studio 中加载该模型。"
)
# 构造请求体
payload = {
"model": model,
"messages": messages,
"temperature": temperature,
"max_tokens": max_tokens,
"stream": stream
}
url = f"{self.base_url}/api/v0/chat/completions"
collected_text = ""
headers = {"Content-Type": "application/json"}
# 开始计时
start_time = time.time()
ttf_time = None
first_token_received = False
try:
async with self.session.post(url, json=payload, headers=headers) as resp:
if resp.status != 200:
error_text = await resp.text()
raise ConnectionError(f"API 请求失败: {resp.status} - {error_text}")
if not stream:
data = await resp.json()
return QwenResponse(data, start_time)
# 流式处理
final_data = {}
usage = {}
output_token_count = 0 # 手动计算输出 token 数
async for line in resp.content:
if not line.strip():
continue
if line.startswith(b"data: "):
line = line[6:].strip()
if line == b"[DONE]":
break
try:
json_line = json.loads(line)
# 处理流式内容
if "choices" in json_line and len(json_line["choices"]) > 0:
choice = json_line["choices"][0]
delta = choice.get("delta", {}).get("content", "")
if delta:
if not first_token_received:
ttf_time = time.time() - start_time
first_token_received = True
collected_text += delta
output_token_count += await self._estimate_tokens(delta)
if on_stream:
result = on_stream(delta)
if inspect.isawaitable(result):
await result
# 检查是否有 finish_reason
finish_reason = choice.get("finish_reason")
if finish_reason:
final_data["finish_reason"] = finish_reason
# 尝试从流式数据中提取 usage(通常在最后一个数据包中)
if "usage" in json_line:
usage.update(json_line["usage"])
print(f"🔍 从流式数据中获取到 usage: {usage}")
except json.JSONDecodeError as e:
print(f"JSON 解析错误: {e}, 原始数据: {line}")
except Exception as e:
print(f"解析流式数据出错: {e}")
# 如果流式数据中没有 usage,则手动估算
if not usage:
print("⚠️ 流式响应中未找到 usage 信息,使用估算值")
input_text = self.system_prompt + " " + prompt
estimated_input_tokens = await self._estimate_tokens(input_text)
estimated_output_tokens = await self._estimate_tokens(collected_text)
usage = {
"prompt_tokens": estimated_input_tokens,
"completion_tokens": estimated_output_tokens,
"total_tokens": estimated_input_tokens + estimated_output_tokens
}
print(f"📊 估算的 token 统计: {usage}")
# 构造最终响应
end_time = time.time()
generation_time = end_time - start_time
final_data = {
"choices": [{
"message": {"content": collected_text},
"finish_reason": final_data.get("finish_reason", "stop")
}],
"usage": usage
}
# 计算性能统计
raw_stats = {
"generation_time": generation_time,
"time_to_first_token": ttf_time or 0,
"tokens_per_second": usage.get("completion_tokens", 0) / generation_time if generation_time > 0 else 0
}
return QwenResponse(final_data, start_time, raw_stats)
except Exception as e:
print(f"请求异常: {e}")
return QwenResponse({"error": str(e)}, start_time)
class QwenResponse:
"""增强版 Qwen 响应对象,支持 token 与耗时统计"""
def __init__(
self,
response_data: Dict[str, Any],
start_time: float,
raw_stats: Optional[Dict[str, Any]] = None
):
self.raw_response = response_data
self.start_time = start_time
# 提取文本
if "choices" in response_data and len(response_data["choices"]) > 0:
self.text = response_data["choices"][0]["message"]["content"]
else:
self.text = str(response_data)
# 从 response_data 提取 usage
usage = response_data.get("usage", {})
self.input_tokens = usage.get("prompt_tokens", 0)
self.output_tokens = usage.get("completion_tokens", 0)
self.total_tokens = usage.get("total_tokens", 0)
# 从 raw_stats 或 response_data 的 stats 字段提取
stats = raw_stats or response_data.get("stats", {})
self.generation_time = stats.get("generation_time", time.time() - start_time)
self.time_to_first_token = stats.get("time_to_first_token", 0)
self.tokens_per_second = stats.get("tokens_per_second", 0)
# 可选:finish_reason
if "choices" in response_data and len(response_data["choices"]) > 0:
self.finish_reason = response_data["choices"][0].get("finish_reason", "unknown")
else:
self.finish_reason = "unknown"
def __str__(self) -> str:
return f"QwenResponse(text='{self.text[:50]}...')"
def print_stats(self):
"""打印 token 与耗时统计信息"""
print("\n" + "="*60)
print("📊 LM Studio 模型推理统计信息")
print("="*60)
print(f"🔹 输入 token 数量: {self.input_tokens}")
print(f"🔹 输出 token 数量: {self.output_tokens}")
print(f"🔹 总 token 数量: {self.total_tokens}")
print(f"🔹 生成耗时: {self.generation_time:.2f} 秒")
print(f"🔹 首个 token 耗时: {self.time_to_first_token:.3f} 秒")
print(f"🔹 吞吐量: {self.tokens_per_second:.1f} tokens/秒")
print(f"🔹 完成原因: {self.finish_reason}")
print("="*60)
# ======================= 自测入口 =======================
def main():
async def test():
async with QwenModelConfig(
model_name="qwen/qwen3-coder-30b",
# 将这里的域名改成你的局域网的IP即可:
host="192.168.1.xx",
port=9851
) as qwen:
print("\n>>> 流式模式测试")
def printer(delta):
print(delta, end="", flush=True)
prompt = "你好,请简单介绍一下你自己"
# 测试流式模式
response = await qwen.process_input(
prompt=prompt,
stream=True, # 改为 True 测试流式
on_stream=printer,
temperature=0.5,
max_tokens=1024
)
print("\n\n[最终汇总] ", response.text[:100] + "..." if len(response.text) > 100 else response.text)
response.print_stats()
print("\n" + "="*60)
print(">>> 非流式模式测试")
# 测试非流式模式
response2 = await qwen.process_input(
prompt=prompt,
stream=False,
temperature=0.5,
max_tokens=1024
)
print(f"[非流式结果] {response2.text[:100]}..." if len(response2.text) > 100 else response2.text)
response2.print_stats()
asyncio.run(test())
if __name__ == "__main__":
main()
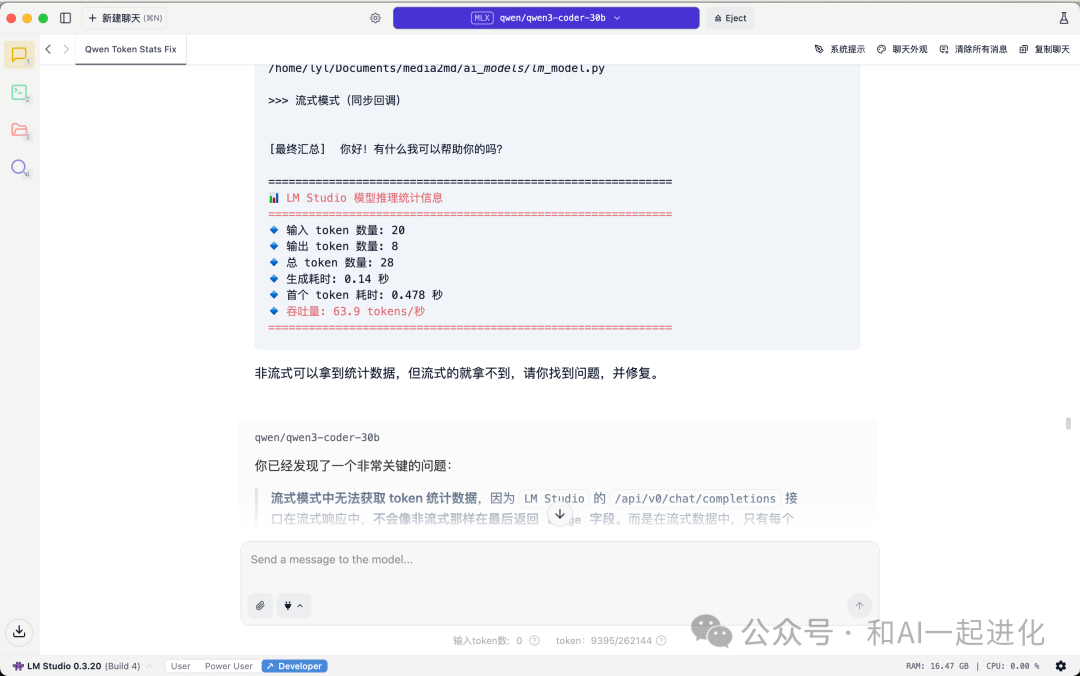
有趣的是,我把之前的一个openai格式的模型代码和LM的访问文档喂给qwen3-coder,它也确实写了一个勉强能跑的代码,但对于流式输出的token统计一直无法正确输出,哪怕给了报错信息都改不对。而同样的提示词,我喂给了sonnet4,一次性就改对了,只能说,本地量化版,目前对于代码生成,还只能处理一点简单任务,如果不是不让联网,最好还是别用本地小模型。
新版qwen/qwen3-30b-a3b-2507的尝试和指令跟随能力效果还可以,但非常多的emoji,强烈怀疑蒸了御三家的一些数据。当然,和一些朋友的观点不同,我并不排斥蒸,我只排斥蒸的不够好,不够多。 我自己没有像牙医大佬那样维护一个自己的私有测试集,所以不能给出一个较为全面的评估,欢迎大家关注他的评测。
目前我还没尝试工具调用的配置,我也暂时没遇到这方面的需求,欢迎有这方面经验的朋友讨论交流。
总结:
相比第一版的qwen3,七月底的这个新版,让我有了更多的期待,我们穷哥们的本地模型又有了希望,按照他们目前的发布节奏,估计下周会有新版的qwen3-8B?
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
第一不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

















 3047
3047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









