



一、Ollama介绍
1 基本介绍
Ollama是一个支持在Windows、Linux和MacOS上本地运行大语言模型的工具。它允许用户非常方便地运行和使用各种大语言模型,比如Qwen模型等。用户只需一行命令就可以启动模型。
主要特点包括:
- 跨平台支持
Windows、Linux、MacOS系统。 - 提供了丰富的模型库,包括
Qwen、Llama等1700+大语言模型,可以在官网model library中直接下载使用。 - 支持用户上传自己的模型。用户可以将
huggingface等地方的ggml格式模型导入到ollama中使用。也可以将基于pytorch等格式的模型转换为ggml格式后导入。 - 允许用户通过编写
modelfile配置文件来自定义模型的推理参数,如temperature、top_p等,从而调节模型生成效果。 - 支持多
GPU并行推理加速。在多卡环境下,可以设置环境变量来指定特定GPU。 - 强大的技术团队支持,很多模型开源不到24小时就能获得支持。
总的来说,Ollama降低了普通开发者使用大语言模型的门槛,使得本地部署体验大模型变得简单易行。对于想要搭建自己的AI应用,或者针对特定任务调优模型的开发者来说,是一个非常有用的工具。它的一些特性,如允许用户自定义模型参数,对模型进行个性化适配提供了支持。
2 官网
- Ollama 下载:https://ollama.com/download
- Ollama 官方主页:https://ollama.com
- Ollama 官方 GitHub 源代码仓库:https://github.com/ollama/ollama/

二、window 安装
直接从下载页面下载相对应系统的安装程序,Windows安装程序选择Windows的安装包,点击“Download for Windows(Preview)”

下载好以后一路install 安装即可。

安装完成之后,打开一个cmd命令窗口,输入“ollama”命令,如果显示ollama相关的信息就证明安装已经成功了!

三、Mac 安装
直接从下载页面下载相对应系统的安装程序,Windows安装程序选择Windows的安装包,点击“Download for Mac”

下载好后打开安装命令行

四、 Linux 安装
在Linux系统上,可以通过脚本安装或源码编译的方式来安装Ollama。下面分别介绍这两种安装方法。
4.1 脚本安装
Ollama提供了一键安装脚本,可以快速在Linux系统上安装Ollama。安装步骤如下:
- 打开终端,执行以下命令下载安装脚本:
curl -fsSL https://ollama.com/install.sh | sh
- 等待安装完成。安装脚本会自动下载所需的组件,并完成
Ollama的安装与配置。 - 安装完成后,可以通过以下命令启动
Ollama:
ollama serve
4.2 二进制安装
- 将 Ollama 的二进制文件下载到 PATH 中的目录:
sudo curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/bin/ollama sudo chmod +x /usr/bin/ollama
- 将 Ollama 添加为自启动服务,首先,为 Ollama 创建用户:
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollama
- 然后在该位置:
/etc/systemd/system/ollama.service创建服务文件
[[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
[Install]
WantedBy=default.target
- 设置开机自启动
sudo systemctl daemon-reload sudo systemctl enable ollama
- 启动 Ollama,使用以下命令启动 Ollama:
systemd
sudo systemctl start ollama
4.3 安装特定版本
设置 OLLAMA_VERSION字段,,可以安装对应的版本
curl -fsSL https://ollama.com/install.sh | OLLAMA_VERSION=0.3.13 sh
4.4 查看日志
查看作为启动服务运行的 Ollama 的日志:
journalctl -e -u ollama
4.5 更新
通过shell 脚本更新 Ollama:
curl -fsSL https://ollama.com/install.sh | sh
或者下载 Ollama 二进制文件:
sudo curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/bin/ollama sudo chmod +x /usr/bin/ollama
4.6 卸载
- 删除 Ollama 服务:
sudo systemctl stop ollama sudo systemctl disable ollama sudo rm /etc/systemd/system/ollama.service
- 从 bin 目录中删除 Ollama 二进制文件:
/usr/local/bin,/usr/bin,/bin
sudo rm $(which ollama)
- 删除下载的模型和 Ollama 服务用户和组:
sudo rm -r /usr/share/ollama sudo userdel ollama sudo groupdel ollama
unsetunset三、命令参数unsetunset
以下是 Ollama 使用常见的指令:
ollama serve #启动ollama
ollama create #从模型文件创建模型
ollama show #显示模型信息
ollama run #运行模型
ollama pull #从注册表中拉取模型
ollama push #将模型推送到注册表
ollama list #列出模型
ollama cp #复制模型
ollama rm #删除模型
ollama help #获取有关任何命令的帮助信息
unsetunset四、设置自定义模型下载路径unsetunset
默认情况下,ollama模型的存储目录如下:
- macOS:
~/.ollama/models - Linux:
/usr/share/ollama/.ollama/models - Windows:
C:\Users\<username>\.ollama\models
4.1 Windows 更改 Ollama 模型存放位置
在Windows系统中,若要更改Ollama模型的存放位置,可以按照以下步骤操作:
- 打开环境变量编辑界面。可以通过以下方式:
- 右键点击“此电脑”或“我的电脑”,选择“属性”。
- 在系统窗口中选择“高级系统设置”。
- 在系统属性窗口中点击“环境变量”按钮。
- 在环境变量窗口中,点击“新建”创建一个新的系统变量或用户变量。
- 变量名:
OLLAMA_MODELS - 变量值:输入你希望设置的新模型存放路径,例如:
D:\Ollama\Models
- 点击“确定”保存设置。
- 重启任何已经打开的Ollama相关应用程序,以便新的路径生效。

4.2 Linux/Mac 更改 Ollama 模型存放位置
在Linux或Mac系统中,更改Ollama模型存放位置的步骤如下:
- 打开终端。
- 创建一个新的目录作为模型存放位置,例如:
mkdir -p /path/to/your/new/ollama/models
- 设置环境变量。在Linux系统中,可以通过编辑
~/.bashrc或~/.bash_profile文件(对于bash shell)或~/.zshrc文件(对于zsh shell)。在Mac系统中,可以通过编辑~/.bash_profile或~/.zshrc文件。使用以下命令编辑文件:
nano ~/.bashrc # 或者使用其他的文本编辑器,如vim
- 在文件末尾添加以下行来设置
OLLAMA_MODELS环境变量:
export OLLAMA_MODELS="/path/to/your/new/ollama/models"
- 保存并关闭文件。如果你使用的是nano编辑器,可以按
Ctrl + X,然后按Y确认保存,最后按Enter键。 - 使环境变量生效。在终端中运行以下命令:
source ~/.bashrc # 或者source ~/.bash_profile,取决于你编辑的文件
- 重启任何已经打开的Ollama相关应用程序,以便新的路径生效。
五、导入 huggingface 模型
Ollama 从最新版0.3.13开始支持从 Huggingface Hub 上直接拉取各种模型,包括社区创建的 GGUF 量化模型。用户可以通过简单的命令行指令快速运行这些模型。
可以使用如下命令:
ollama run hf.co/{username}/{repository}
请注意,您可以使用
hf.co或huggingface.co作为域名。

cover
要选择不同的量化方案,只需在命令中添加一个标签:
ollama run hf.co/{username}/{repository}:{quantization}
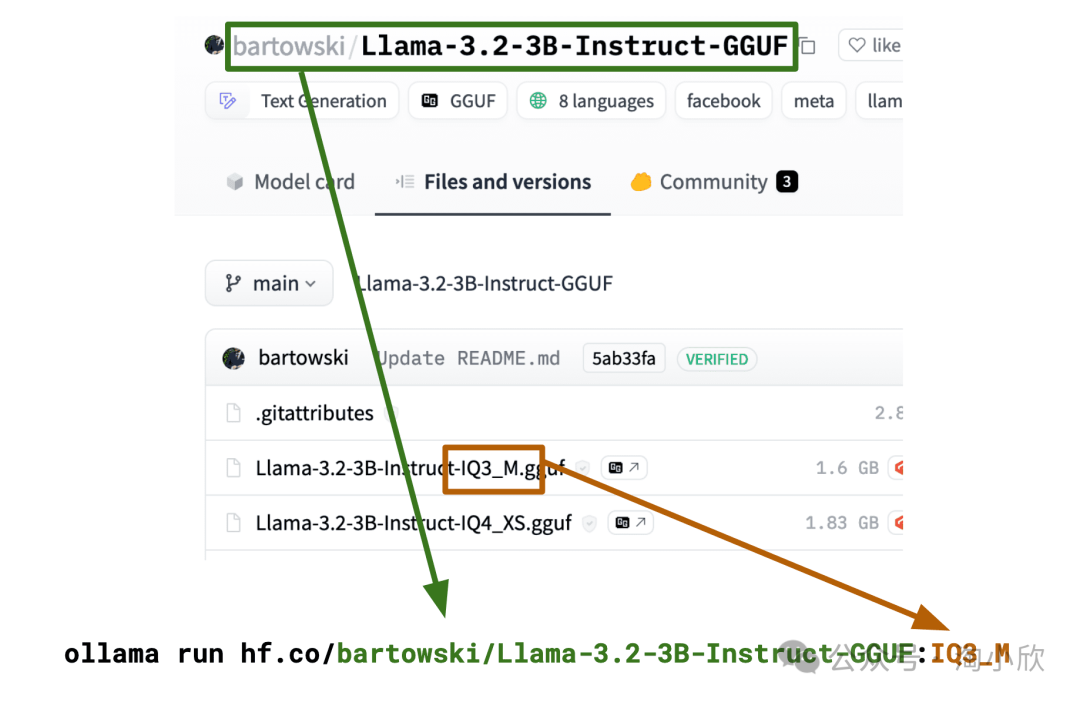
例如:
ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:IQ3_M ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0
量化名称不区分大小写,因此以下命令同样有效:
ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:iq3_m
您还可以直接使用完整的文件名作为标签:
ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:Llama-3.2-3B-Instruct-IQ3_M.gguf

程序员为什么要学大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









