







目录
SINTERSTORE / SUNIONSTORE / DIFFSTORE
Hash 哈希
⼏乎所有的主流编程语⾔都提供了哈希(hash)类型,它们的叫法可能是哈希、字典、关联数
组、映射。
TIPS:哈希类型中的映射关系通常称为:field-value 用于区别Redis整体的键值对key-val的关系
所以在Redis的value中使用hash类型应该是这么表示key - field - val
常用指令
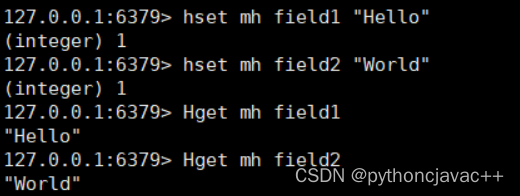
HSET
设置hash中指定的字段field 的值 value
语法:
HSET key field value [field value ...]返回值:添加的字段的个数
示例:
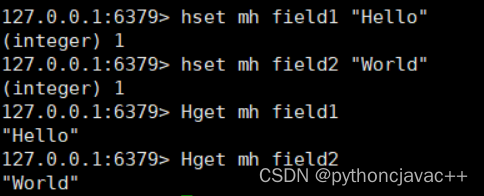
HGET
获取hash中指定字段的值
语法:
HGET key field返回值:字段对应的值或者nil
示例:
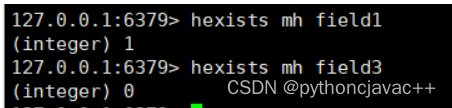
HEXISTS
判断hash中是否有指定的字段
语法:
HEXISTS key field返回值:1表示存在,0表示不存在
示例:
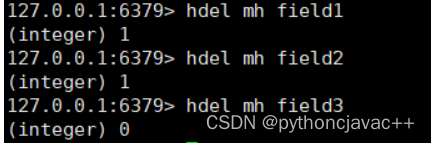
HDEL
删除hash中指定的字段
语法:
HDEL key field [field ...]返回值:本次操作删除的字段个数
示例:
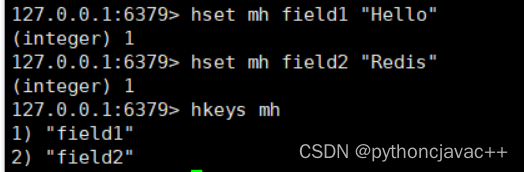
HKEYS
获取hash中的所有字段
语法:
HKEYS key返回值:字段列表
示例:
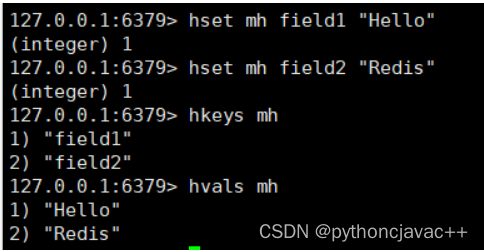
HVALS
获取hash中所有的值
语法:
HVALS key返回值:所有的值val
示例:
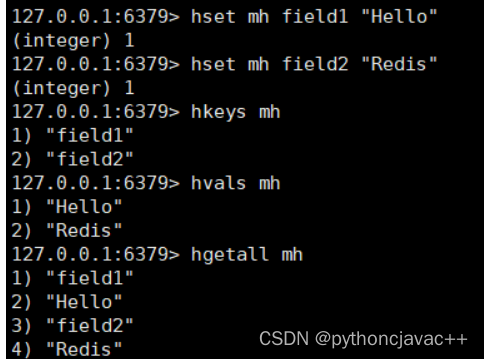
HGETALL
获取哈希汇总的所有字段以及对应的值
语法:
HGETALL key返回值:字段和其对应的值
示例:
HMGET
一次获取hash中字段的多个值
语法:
HMGET key field [field ...]返回值:字段对应的值或者nil
示例:

TIPS:在使⽤HGETALL时,如果哈希元素个数⽐较多,会存在阻塞Redis的可能。如果开发⼈员只需要获取部分field,可以使⽤HMGET
内部编码
哈希的内部编码有两种:
1.ziplist(压缩列表):当hash类型元素小于hash-max-ziplist-entries配置(默认512个)、同时所有的值都小于hash-max-ziplist-value(默认64字节),Redis会使用ziplist作为hash的内部实现,zipliost使用更加紧凑的就够实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀
2.hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现,因为此时的hashlist的读写小会下降,而hashtable的读写时间复杂度为O(1)
Hash类型和关系型数据库
- 哈希类型是稀疏的,⽽关系型数据库是完全结构化的,例如哈希类型每个键可以有不同的field,⽽关系型数据库⼀旦添加新的列,所有⾏都要为其设置值,即使为null
- 关系数据库可以做复杂的关系查询,而Reid社区模拟关系型复杂查询,例如:联表查询、聚合查询等基本不可能,维护成本高
缓存方式对比
现在有三种方法缓存用户信息
1.原生字符串类型 -- 使用字符串类型,每个属性占用一个键
set user:1:name gc
set user:1:age 22
set user:1:sex 男优点: 实现简单,针对个别属性变更也很灵活。
缺点:占⽤过多的键,内存占⽤量较⼤,同时⽤⼾信息在?Redis?中⽐较分散,缺少内聚性,所以这种⽅案基本没有实⽤性
2.序列化字符串类型,例如JSON格式
set user:1 经过序列化后的字符串~~优点:针对总是以整体为操作的信息比较合适
缺点:序列化和反序列化本身需要一定的开销,如果总是操控个别属性的话不方便
3.哈希类型
hmset user:1 name gc age 22 sex 男优点:简单直观且灵活
缺点:需要控制hash在ziplist和hashtable两种内部编码的转换,可能会造成内存开销大
List 列表
列表类型是⽤来存储多个有序的字符串,⼀个列表最多可以存储2^32-1 个元素。在Redis中,可以对列表两端插⼊(push)和弹出(pop),还可以获取指定范围的元素列表、获取指定索引下标的元素等
入图对列表两端的插入和 弹出操作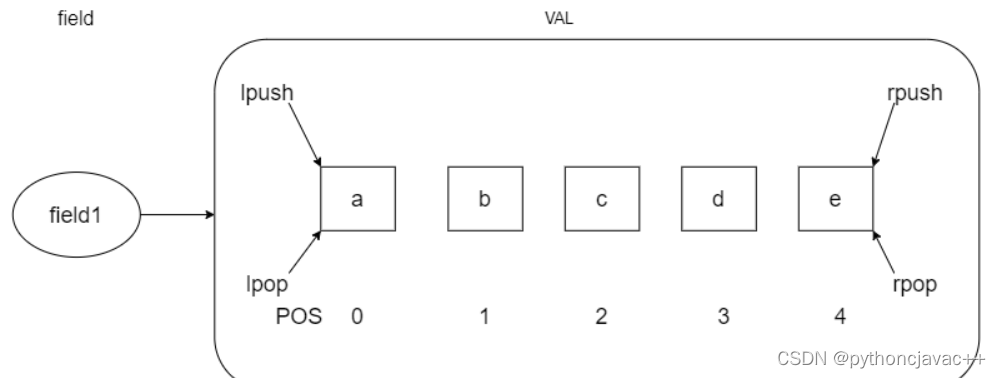
特点
- 1. 列表中元素是有序的,是可以使用索引下标获取某个元素或者某个范围的元素列表
- 2. 获取会得到该下标的元素,删除会将列表的长度减小
- 3. 列表的元素允许重复
常用命令
LPUSH
将⼀个或者多个元素从左侧放⼊(头插)到list中
返回值:插⼊后list的⻓度
示例:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











