



 本文介绍了一个大规模的手势识别数据集HaGRID,旨在改善设备交互和视频会议体验。HaGRID包含554,800张图像,用于手部检测和手势分类任务,强调多样性和场景的异质性。实验表明,HaGRID在提高模型性能和处理动态手势方面具有优势,可作为预训练模型的数据源。"
112299808,7956711,京东茅台抢购脚本:Python实现保姆级教程,"['Python', '京东开发', '自动化工具', '抢购脚本']
本文介绍了一个大规模的手势识别数据集HaGRID,旨在改善设备交互和视频会议体验。HaGRID包含554,800张图像,用于手部检测和手势分类任务,强调多样性和场景的异质性。实验表明,HaGRID在提高模型性能和处理动态手势方面具有优势,可作为预训练模型的数据源。"
112299808,7956711,京东茅台抢购脚本:Python实现保姆级教程,"['Python', '京东开发', '自动化工具', '抢购脚本']
论文原文::::2206.08219.pdf (arxiv.org) https://arxiv.org/pdf/2206.08219.pdf
https://arxiv.org/pdf/2206.08219.pdf
摘要
本文介绍了一个庞大的手势识别数据集——海格(HAnd Gestrue Recognition Image dataset),以简历一个手势识别(HGR)系统,专注于与设备的交互管理。这就是为什么所选的18个手势都呗赋予了符号学功能,可以被解释为一个特定的动作。虽然这些手势是静态的,但是他们还是被选中了,尤其是因为他们能够设计出多种动态手势。它使训练好的模型,不仅能识别 "喜欢 "和 "停止 "等静态手势,还能识别 "轻扫 "和 "拖放 "等动态手势。HaGRID 包含 554,800 张图像和带有手势标签的边界框注释,可用于解决手部检测和手势分类任务。其他数据集的背景和研究对象的可变性较低,这也是我们创建不受这些限制的数据集的原因。利用众包平台,我们收集到了 37,583 个拍摄对象在至少同样多的场景中拍摄的样本,拍摄对象与相机之间的距离从 0.5 米到 4 米不等,拍摄条件也各不相同。在消融研究实验中评估了多样性特征的影响。此外,我们还展示了 HaGRID 在 HGR 任务中用于预训练模型的能力。HaGRID 和预训练模型可公开获取。
1. Introduction(简介)
手势在人类交流中发挥着至关重要的作用。手势可以在情感上强化语句,甚至能完全替代语句。由于人们在现实生活中普遍使用手势,因此在汽车领域[27]、[26]、家庭自动化系统[3]、多媒体应用、各种视频/流媒体平台(Zoom、Skype、Discord、Jazz 等)以及其他领域[10]、[5],构建 HGR 系统可以改善用户体验并加快流程。此外,该系统还可以成为虚拟助手或服务的一部分,为听力和语言障碍的手语用户提供服务[9], [24] 。
我们研究的主要目的是建立 HGR 系统,以便在带有虚拟助手的家庭自动化设备和视频会议服务 Jazz5 中实施。首先,这套手势必须直观[30]且简单明了,以便系统用户能够记住它们,进行舒适的交互。
此外,在设计 HGR 系统时,还应配上适合控制该系统的手势,以及 "fergotic "功能[8]。在我们的例子中,语义手势的目的是人与计算机之间共享信息,以获得系统的响应,可以是静态的,也可以是动态的。我们也注意到了其他姿态识别使用者的体验。例如,节奏舞者使用我们的设备时候,需要识别到画面中的双手,这在box markup当中是不可能的。此外,在极端光照和被摄体与摄像机距离较大等挑战性条件下,边界框标注比关键点标注更稳定。
在本文的第 5 部分,我们提供了一组数据集消融实验,以探索数据集特征对作为分类和检测问题的 HGR 解算结果的影响程度。此外,我们还通过实验证明,HaGRID 可以作为预训练 HGR 模型的充分数据集,并进行了如下微调。
2.Related Work(相关工作)
2.1. Hand Gesture Datasets
至少有50个与手部动作相关的数据集,这些数据集大体上可以分为三类:手语、旗语、和操作手势。第一类——手语,第一组数据集提出了复杂的动态手势,这些手势更适用于其原始目的,而对于我们要求直接动作的目标来说则是多余的。后两组数据应用于家庭自动化系统和人机交互,并相应地发挥了符号学和人机工程学的作用。 由于我们的目标是建立一个以符号作用为主的 HGR 系统,仅使用启发式方法添加操作性手势,因此本节仅对具有静态手势的数据集进行回顾。
由于 HGR 系统的用户可能会在距离设备较远的地方显示手势,因此模型需要捕捉整个画面,并在其中搜索人的手。然而,一些包含静态手势的数据集是为独立于人的系统设计的,包含的样本中没有人体,只有手的部分,即经过裁剪的手部图像 [16] [18],这就是为什么它们不适合我们的原因。静态手势数据集经常使用以下标记类型或其组合进行标记:类别标签、边界框、关键点和分割标记。
我们需要在multiple-hand画面上无差错地工作,因此只有类别标记是不够的。分割掩码是多余的,不适合这项任务,因为它们无法很好地对与手势如此相似的物体进行分类,而关键点则无法使用,因为它们在长距离内会粘连在一起。据我们所知,目前仅有 4 个数据集可用于带有背景和适当注释的静态手势识别,包括 HANDS [25]、SHAPES [2]、OUHANDS [22] 和 LaRED [13]。
它们的区别在于样本数量、图像分辨率、类别数量、负样本的存在、场景的同质性以及摄像机与每个被摄体之间的距离。SHAPE 和 OUHANDS 用边界框和分割掩码标记;LaRED 仅用掩码标记,而 HANDS 仅用边界框标记,上述数据集不适合用于构建我们的 HGR 系统,原因是场景和被摄体等特征的异质性不足,这对照明条件和被摄体到摄像机距离的异质性产生了负面影响。 在消融研究(第 5 节)中,实验证明了这些特征对于神经网络泛化的必要性。
-
LaRED 数据集[13]分为 27 个主要手势类别和 54 个通过围绕两个轴旋转主要手势而创建的附加类别。该数据集由短距深度相机采集,这意味着图像中的背景数量较少;因此,当主体与相机之间的距离较大时,模型会误认。此外,每个受试者每类动作拍摄 300 张图像,这些图像中手部仅有轻微动作变化,因此这些图像几乎完全相同。遗憾的是,由于链接过期,我们无法获得该数据集。
- OUHANDS 数据集[22]是为了简化人机交互(HCI)工具的测试过程而创建的,共有 10 个独特的类别,每个类别包含 300 张图片。不同的记录条件只能改善部分情况。此外,大部分拍摄对象的手都离摄像机很近。
- HANDS[25]是一个用于人机交互的数据集,由 29 种适合该应用的手势组成,这些手势简单易用。不过,其中大多数手势差别不大,使 HGR 系统的使用变得复杂。作者考虑了光照条件;然而,光照条件无法满足仅有 5 个背景的数据集的可变性。
- HANDS[25]是一个用于人机交互的数据集,由 29 种适合该应用的手势组成,这些手势简单易用。不过,其中大多数手势差别不大,使其在 HGR 系统的使用变得复杂。作者考虑了光照条件;然而,光照条件无法满足仅有 5 个背景的数据集的可变性。
- SHAPE 数据集的手势类别在选择时重点考虑了其含义;然而,某些手势在文化方面具有特殊性,这限制了它们对其他国家的人的实用性。作者在收集样本时改变了外部因素,并通过改变拍照的角度使其适应移动相关开发的特定领域。 尽管如此,SHAPE 的主题并不多样化,有些手势对设备用户来说并不直观,请注意,SHAPE 并不公开,我们无法向作者索取。
上述局限性促使我们创建一个新的 HGR 数据集,以消除这些缺点。从表 1 中可以看出,我们给出的数据集样本数量最多,并且在不同主体和场景之间的多样性得分最高,这有助于避免过拟合。
2.2 Dataset Creation Pipeline(数据集创建流程)
由于数据集创建pipeline是我们的贡献之一,我们审查了收集和注释 HGR 数据集的现有pipeline。以下创建方法在受试者的选择和数量上有所不同,取决于受试者的数量、记录和传输样本的方法以及数据多样化和注释方法。
所审查的大多数数据集都是通过手动记录创建的,这使得数据集的异质性更高,也无法包含足够的样本。为了略微改善这种情况,数据集的作者试图使数据多样化。举例来说,HANDS 数据集的多样性是通过以下方式实现的:(1) 5 种不同的背景;(2) 当被摄体静止或移动时,存在杂乱和统一的背景(3) 人工和自然光。SHAPE 数据集则通过改变被摄体到摄像机的距离、背景和服装来实现多样化。LaRED 数据集的作者利用他们的软件工具优化了数据记录。不过,由于要求受试者对每个手势记录 100 帧图像三次,因此数据可变性较低。在这种有限的条件下,"HANDS "和 "SHAPE "是创建数据的诀窍之一,即用双手做出相同的手势,以优化图像的收集和注释,并将类别数量增加 2 倍(右手和左手手势是 2 个不同的类别)。关于标注过程,我们知道,只有 SHAPE 数据集是人工标注的。OUHANDS 和 LaRED 中的分割掩码是使用深度图像生成的,这就导致了标记的粗糙。
现有的静态手势数据集最大的局限性在于语境单一、受试者数量有限以及样本数量不足以训练出稳健的 HGR 模型。此外,在受控实验室环境中手动记录数据集也会影响数据集的创建[14]。我们利用众包平台来克服这些限制,建立接近真实分布的变异数据。作者[14]强调,选择这种数据创建方法可以提高识别性能。
3.HaGRID Dataset
HaGRID 需要结合以下特点:(1)高分辨率图像;(2)图像场景、主体、年龄和性别、光线、主体与摄像机距离的异质性;(3)足够数量的样本;(4)静态和功能性手势。该数据集由 50 多万张全高清 RGB 图像组成,其中最适合我们领域的有 18 种手势和一种 "无手势 "类别。(18+1),该数据集记录了 37 583 个受试者和至少同等数量的独特场景,在其他特征方面也显示出异质性。除了分类,HaGRID还为手部检测问题标注了边界框,每帧图像中有 n 只手对应n个边界框,其中 n ∈ [1, 2]。
3.1 Dataset Creating Pipeline
我们将逐步描述数据集创建的pipeline,以便展现其异质性,并提供数据集内容和质量的详细信息。这个数据集的创建分为四个阶段:(1)图像收集阶段,成为挖掘;(2) 验证阶段,对挖掘规则和一些条件进行检查;(3) 过滤不适当的图像;(4) 标记边界框的标注阶段。 分类阶段是通过为每个手势类别划分成pools的方式,挖掘、验证和标记pipeline。我们使用两个俄罗斯众包平台: Yandex.Toloka(1、2 和 4 个步骤)和 ABC Elementary(3 和 4 个步骤)来完成这些阶段。请注意,所有人群工作者都知道禁止将个人数据传输给第三方以及存在可疑内容。 在注释阶段使用两个平台,由于两个不同注释领域的注释者的参与,我们可以提高最终注释的可信度。每一个步骤的详细信息如下:
1. 图片挖掘。拍摄者的任务是按照任务描述中的特定手势为自己拍照。我们定义了以下标准: (1) 标注者必须与相机保持 0.5 - 4 米的距离,(2) 带有手势的手必须完全在取景框内。有时,我们会改变照明条件,从弱光改为强光,以使神经网络能够适应极端情况。在众包平台的挖掘任务中,我们会定期更换国家,以涵盖更多国家和民族。此外,还使用图像哈希比对[4]对所有接收到的图像进行重复检查。挖掘任务附有说明,并警告不得进一步公布拍摄者的照片。
2. 验证。我们实施了验证阶段,通过剔除不符合挖掘阶段条件的图像,来实现高置信度图像。验证阶段的目的是在挖掘阶段偏向于正确执行的图像,即把它们分为 "正确 "和 "不正确 "两类;只有 "正确 "的图像才能进入数据集。在高质量验证方面,我们采用了一些技巧,如在培训和考试后进入再进行主要的拍摄任务,以及使用控制任务来防止人群工作者作弊。在这一阶段,我们在系统中为每幅图像设置了 3 至 5 名执行者的动态重叠,即每项任务至少由三名crowd workers完成。 根据少数服从多数的原则,一些照片被剔除,而其他照片则进入过滤阶段。在验证阶段之后,每个手势都保留了约 70% 的图片。
3. 过滤。出于道德原因,在此阶段从 HaGRID 中删除了儿童、不穿衣服的人和有纹身的图像。在过滤阶段,我们采用了一条严格的规则--每张图片应由 5 名工作人员进行过滤。一个可通过的图片必须获得至少四位工作人员的赞成票才能被接受。与验证阶段类似,注释者在过滤阶段也要通过全面的考试、培训和控制任务。 超过 85% 的图像通过了过滤阶段。
4. 注释。在注释阶段,通过考试后,人群工作者应在每张图像上的手势周围画一个边界框,如果手势完全在框内,则在没有手势的手周围画一个边界框,并标注特定的标签("手势 "或 "无手势")。 在每个众包平台中,注释重叠度从 3 到 5 不等。所有标注(从 6 到 10 不等)均从两个平台收集,并通过硬聚合算法和软聚合算法中的一种进行聚合(见图 2)。在最大重叠度之后,约有 5%的图片未被聚合到数据集中。
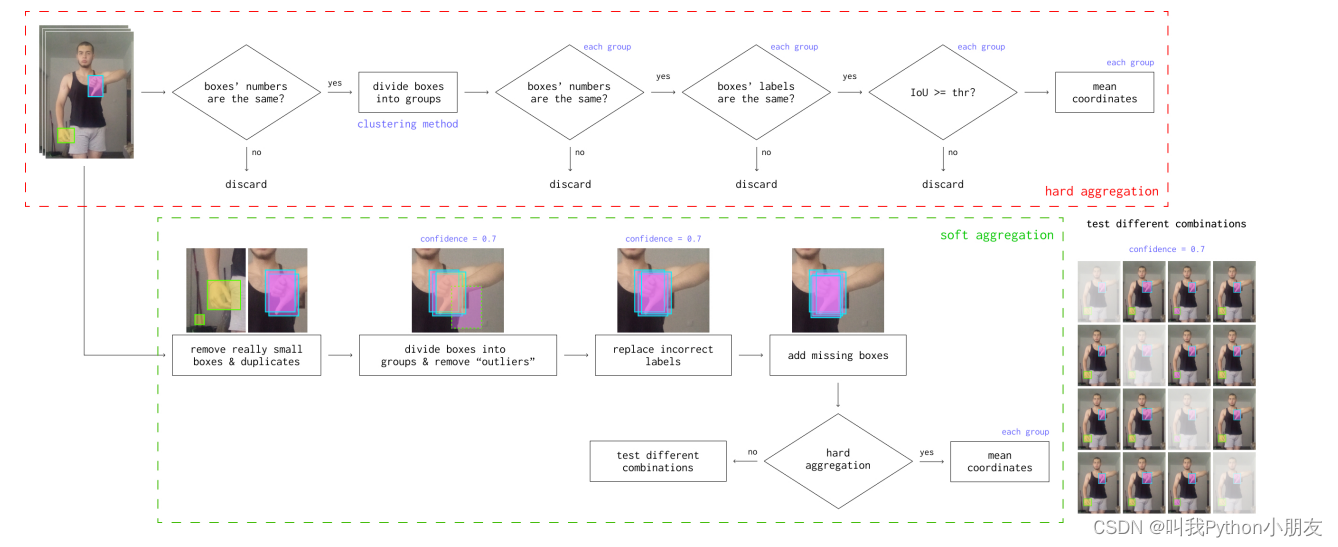
图二: 边界框聚合pipeline。对于硬聚合,在平均之前会对所有标记进行一致性检查。如果失败,软聚合将为成功的硬聚合做准备。
3.2. Dataset Characteristics(数据集特征)
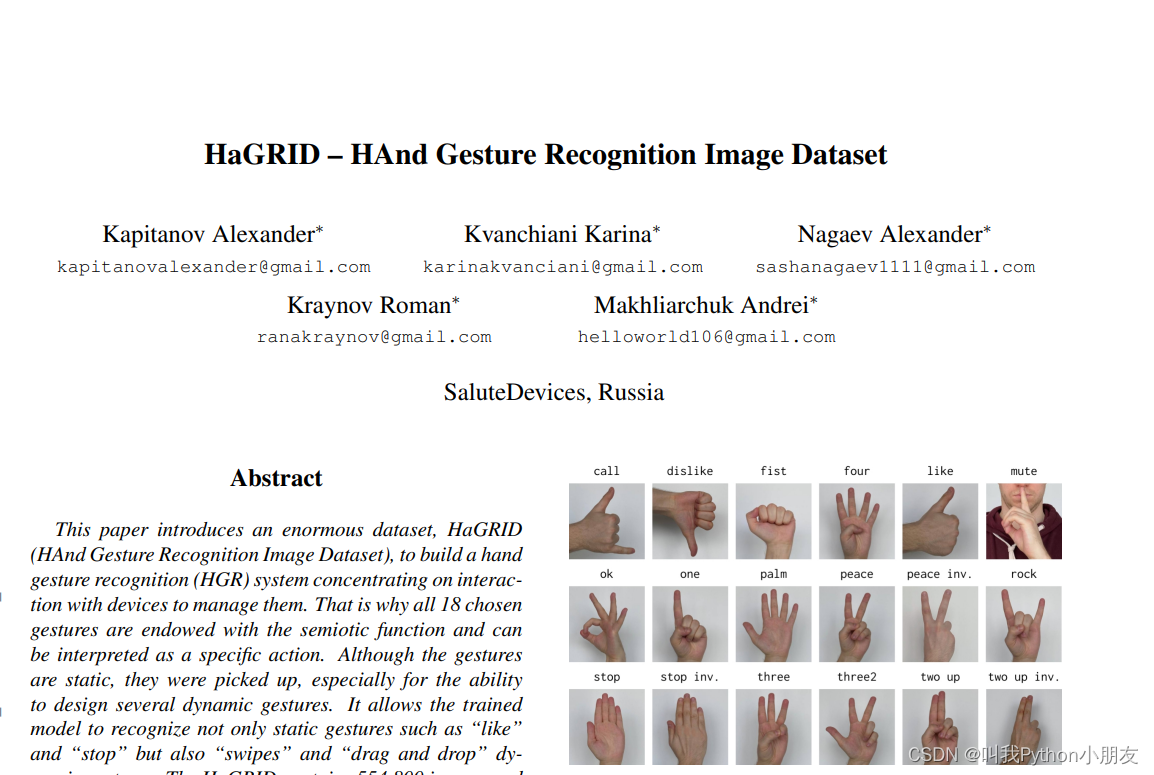
大小和质量。HaGRID 的大小约为 770GB,包括 55 万多张图片,分为 18 类最直观的手势: "呼叫"、"不喜欢"、"拳头"、"四"、"喜欢"、"静音"、"OK"、"一"、"手掌"、"和平"、"和平倒置"、"石头"、"停止"、"停止倒置"、"三"、"三2"、"二上"、"二上倒置" “call”,( “dislike”, “fist”, “four”, “like”, “mute”, “ok”, “one”, “palm”,“peace”, “peace inverted”, “rock”, “stop”, “stop inverted”, “three”, “three2”, “two up”, “two up inverted”)(如图 1 所示)。 由于 HaGRID 是为控制设备或设备应用程序而设计的,手势因其意义而被赋予了特定的联想(见补充材料中的表 3)。 通过这些手势,我们可以解决一些特殊的问题,如用相关的手势表示喜欢/不喜欢某样东西,用 play/stop来播放/停止录音,用 "peace "和 "mute"来打开/关闭声音,用"one"、"peace"、"three"、"four"、"palm"及其组合来控制可调节的刻度(如音量刻度),等等。此外,用户还可以将一些静态手势组合起来,创建数据集中未包含的新动态手势(第 4.3 节)。每个手势类别包含 30,000 多张高分辨率 RGB 图像(图 3a)。
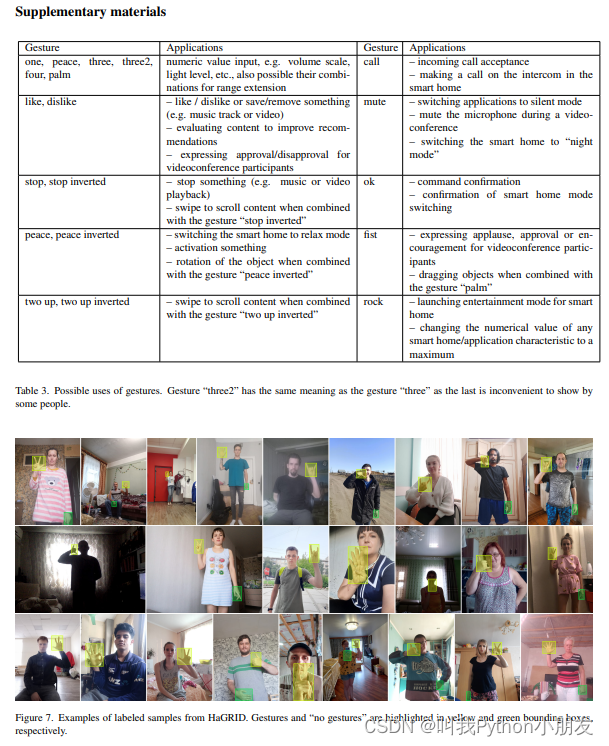
内容。在至少同样多的独特场景中,37,583 张独特的面孔记录了 HaGRID。研究对象的年龄从 18 岁到 65 岁不等,性别均衡。受试者主要来自俄罗斯,其次是其他国家115;具体分布见图 3h。我们考虑了家庭自动化和视频会议服务等应用场景的具体情况,主要选择了照明变化较大的室内环境,包括人造光和自然光。 此外,数据集还包括在极端条件下拍摄的图像,如面向窗户和背对窗户站立(见图 3g)。此外,受试者还在距离智能手机、个人电脑或平板电脑摄像头(图 3f)或平板电脑(图 3b)不同的距离展示了手势。所有图像都包含对我们的应用非常重要的上下文信息(见补充材料中的图 7)。HaGRID 图像像素值的平均值和标准偏差分别为 [0.54, 0.499, 0.473] 和 [0.231, 0.232, 0.229]。
标注。HaGRID 采用了边界框注释,这是我们应用的最佳注释类型。这种选择使我们能够训练轻量级手势检测器或识别轻扫和其他动态手势,以便与设备屏幕上的对象进行交互。每幅图像至少有一个方框用于标注带有手势的手。如果第二只手出现在画面中,则会为其提供带有额外类别 "无手势 "的绑定框。虽然 "无手势 "的手主要是被动的,因此彼此相似,但这足以消除原始的假阳性错误(请参阅资源库中的演示)。我们计划在未来的数据集版本中加入与目标手势类似的自然手部动作样本,从而使额外类别更加多样化。只有 108 056 张图像包含额外类别的边界框。边界框注释以 COCO [21] 格式提出,采用归一化相对坐标。
分割。数据集按受试者分为训练集(74%)、验证集(10%)和测试集(16%)。训练集、验证集和测试集中的受试者分别为 33,966 人、1,908 人和 1,709 人。图 3c-e 表明,为了获得最具代表性的结果,测试集和验证集在设计上特意比训练集的受试者更不均匀。由于是随机抽样,因此每个集都保留了亮度、受试者到摄像机的距离、年龄和性别的原始分布。
此外,还在标注文件中提出了匿名用户 ID 哈希值,研究人员可借此自行拆分 HaGRID。由于数据集规模较大,我们设计了一个带注释的小版本(每类 100 个样本)HaGRID,可在链接上预览,让用户感到舒适。出于同样的原因,还提供了缩小版本(最大图像尺寸为 512),大小为 26 GB。数据集用户可以利用 MediaPipe [1]自动生成的关键点注释来训练手部估计模型。此外,关键点注释还可用于在 HaGRID 上对模型进行预训练,并对其他手势类别进行微调。
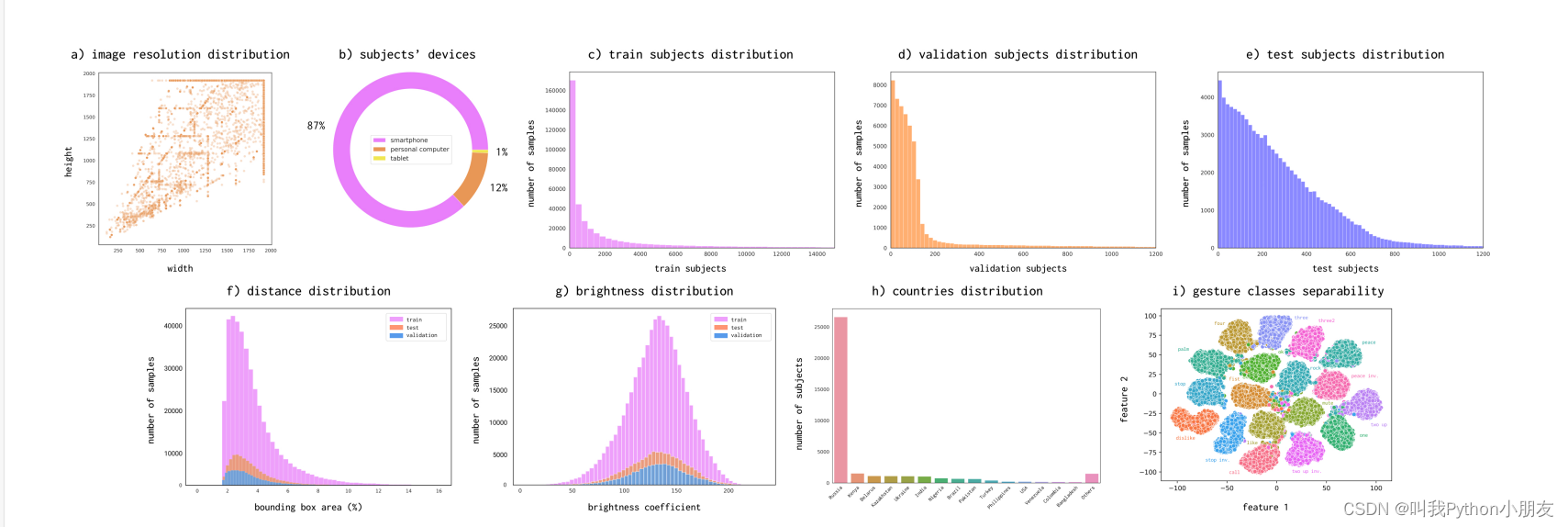
图三:分辨率、亮度、主体与相机距离、主体和类别可分性分析。a) 图像分辨率分布:样本以相同的透明度和密度重叠显示数量,90% 图像的最小维度为 1,080;b) 受试者设备:记录时仅使用智能手机、个人电脑和平板电脑;c)、d)、e) 受试者分别在训练集、验证集和测试集中的图像分布;f) 受试者与相机距离分布: 距离以相对于整幅图像的边框面积计算(边框最多占图像的 16%);g) 亮度分布:图像转换为灰度,并获得平均像素亮度;h) 受试者的国家分布;i) ResNet-18 特征的 t-SNE 图。
4.Base Expirements
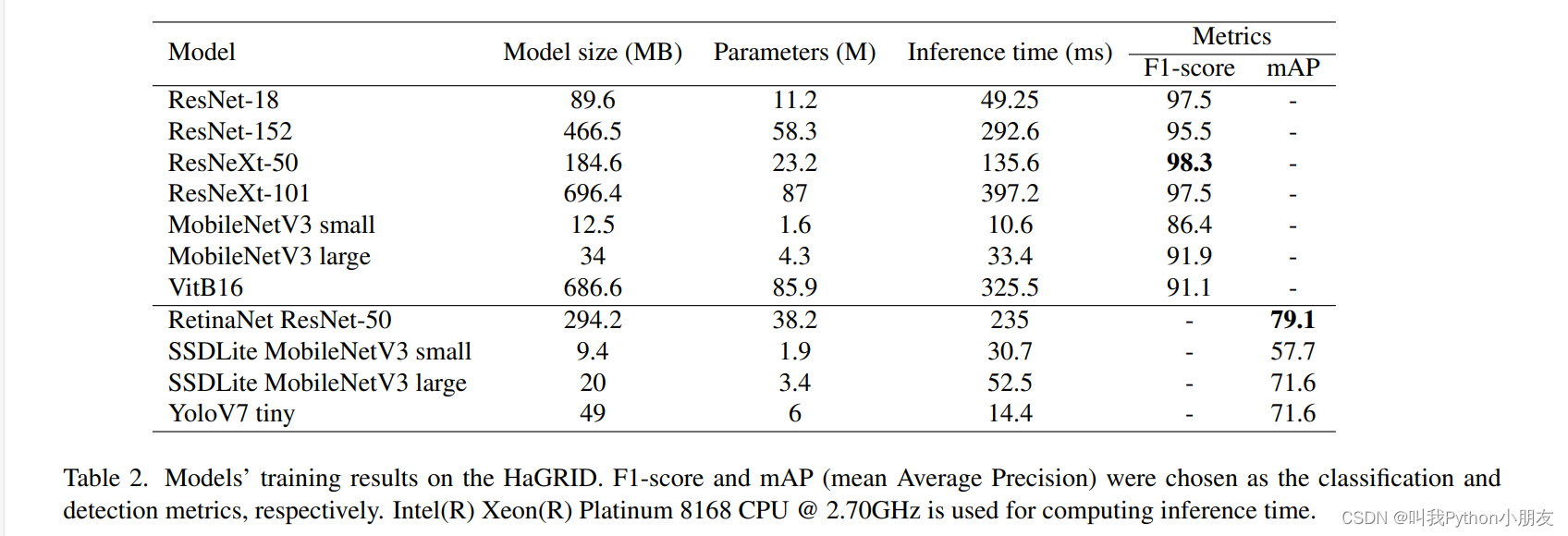
为了评估数据集的能力,我们针对手部检测和手势分类这两项 HGR 任务,评估了 11 种不同规模和参数数量的流行架构。 我们选择带有 MobileNetV3 小型和大型骨干网的 SSDLite [28]、带有 ResNet50 骨干网的 RetinaNet [20] 和 YoloV7 tiny [32] 作为检测器,并选择由 ResNet-18、ResNet152 [11]、ResNeXt-50、ResNeXt-101 [33]、ViTB16、MobileNetV3 small 和 MobileNetV3 large [12] 组成的 7 个架构作为分类器。
4.1 Experiment Setup(实验设置)
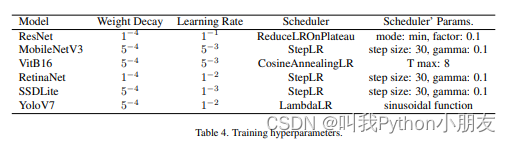
由于数据集规模庞大,除了在 ImageNet ViTB16 上进行预训练外,每个模型都是在全帧图像上从头开始训练的,以下指标是在包含 90,000 张图片的测试集上计算得出的。我们将图像最大边的采样率降低到 224,并将最小边的采样率填充到 224,这些模型在一台 32GB 的 Tesla V100 上进行训练,训练批量为 128 次,直到收敛为止--如果 10 个历时后指标没有增加至少 0.01,就会触发提前停止训练。模型的训练设置汇总于补充材料中的表 4。请注意,"无手势 "类别仅在检测任务中使用,而全帧分类则基于 18 个主要类别,因为每张图像都包含一个目标手势。
4.2.Results
表 2 列出了所选模型架构在解决手势检测和分类问题方面的评估结果。如此高的性能表明,该数据集有能力在不增加训练阶段复杂性的情况下训练模型。
4.3 Dynamic Gesture Recognition
通过遵守特定规则,利用仅包含静态手势的数据集构建动态手势识别器。 这种方法的本质是将动态手势分为两个部分:初始手势和最终手势。例如,动态手势 "向右轻扫(swipe right) "分别由一个左旋和一个右旋手势 "停止 (stop)"作为起始和结束,而手势 "拖放(drag and drop) "则可由 "fist "和 "palm "作为起始和结束对来表示(见图 4)。
我们开发了手势预测队列,将动态手势作为具有一定深度的空列表来实现,并在每一帧中填充事件,队列可验证动态手势执行的正确性。队列由手检测器发现的边界框和分类器提供的相应手势类别进行补充。识别取决于队列中的动作顺序、开始和结束手势之间的时间限制以及开始和结束手势的位置。在识别出一个动态手势后,队列会被重置,然后继续定义静态手势。由于我们需要同时检测手势和手的中间状态,并识别旋转手势,因此演示中分别使用了 YoloV7 微型检测器和 LeNet [19] 作为轻量级分类器。
5.Ablation Study for HaGRID(HaGRID 的消融研究)
我们进行了一项消融研究,以单独评估主要异质性特征的影响。我们通过改变这些特征并冻结其他特征,测试了大量数据、亮度多样性、受试者到摄像机的距离以及受试者数量的必要性。在消融研究中,我们使用 ResNet-18、ViTB16 和 MobileNetV3(小型和大型版本)进行分类任务,并使用 SSDLite 和小型和大型 MobileNetV3 以及 RetinaNet 和 ResNet50 进行检测。 针对所描述的每种特征,我们都采样了几种训练数据修改,以便为所有模型找到最佳数据,验证集和测试集在所有实验中均保持不变。
除了检查特征对 HaGRID 检验的影响外,我们还决定对其他数据--OUHANDS--进行评估。由于 HaGRID 数据集和 OUHANDS 数据集在手势类别上没有交集,因此我们在 OUHANDS 上对通过不同训练数据修改学习到的所有模型进行了微调,并在其测试集上进行了测试。结果还表明,HaGRID 是用于静态 HGR 任务模型预训练的可接受数据集。

5.1. Quantitative Necessity
为了评估数据量的影响,我们对每个架构的 5 个模型进行了训练,每个类别的样本数量从 5,000 个到所有样本,每 5,000 个为一个步骤。确定性切片用于训练集扩展,即 n[i] 集中的图像包含在 n[i+ 1] 集中。由于数据的预混合,其他异质性特征保持了均匀分布,从而限制了它们的影响,并提供了可解释的结果。
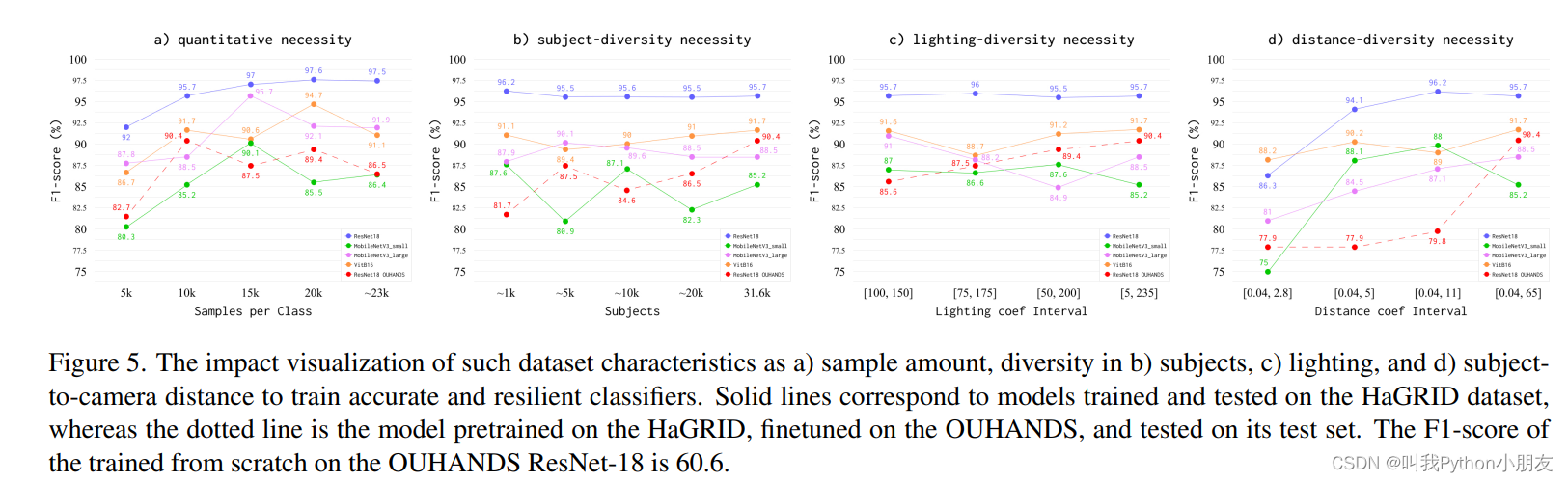
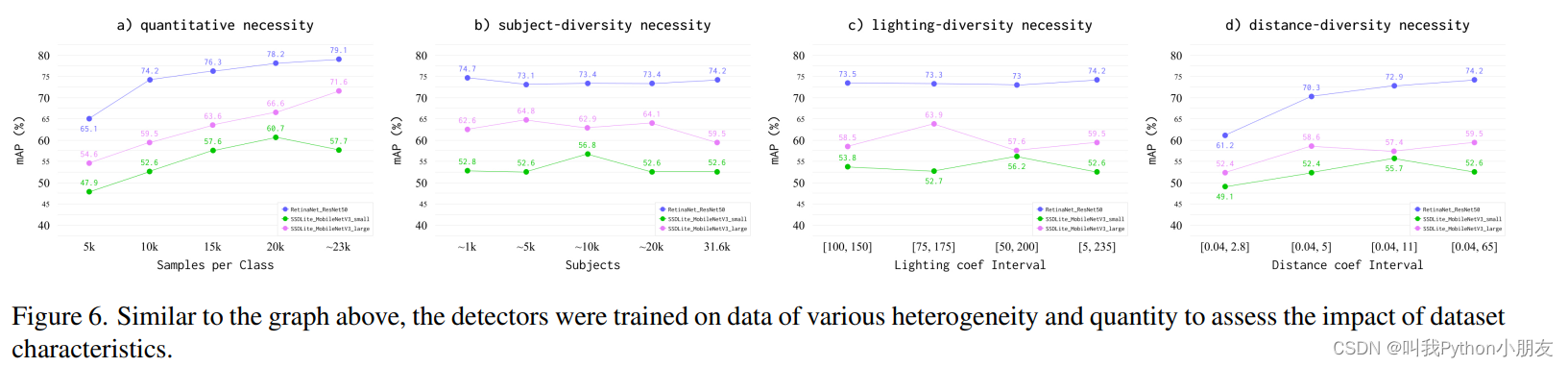
定量必要性结果。分类器和检测器的定量必要性结果(见图 5a 和图 6a)表明,随着训练集的增加,必要性呈上升趋势。平均而言,开始时增强的速度很快,到最后则不太明显。对于分类器来说,每类约有 23,000 个样本是多余的,而对于检测器来说,这些样本对于实现最佳性能是必不可少的。
5.2. Subject-Diversity Necessity
此外,还可通过改变训练集中唯一个体的数量来评估主体数量的重要性。在所有多样性实验中,训练集的数量固定为每类 10,000 张图像;这个数量允许我们对不同异质性的数据进行采样,足以实现较高的性能。其他两个特征--亮度和被摄体到摄像机的距离分布--也保持不变。我们对每个类别采用了抽样算法,以改变 10,000 张图像中的主体数量。 该算法根据来自唯一主题的图像数量对列表进行排序,并以不同的速度(取决于所需主题的数量)从左侧和右侧向中间移动。
主体多样性的必然结果。尽管如此,在分类和检测任务中,HaGRID 测试的趋势几乎没有变化(如图 5b 和图 6b 所示),受试者数量对 OUHANDS 数据的额外训练有积极影响。
5.3. Lighting-Divercity Necessity
与受试者的实验类似,我们在 10,000 张图像中改变了光照的多样性。从均质光照到异质光照,我们选择了四个亮度系数窗口:[100, 150]、[75, 175]、[50, 200]、[5, 235]。由于数据量巨大,我们可以保持其余特征的分布:主体和主体到摄像机的距离。
照明多样性必要性结果。图 5c 和图 6c 显示,在同一数据集上进行测试时,照明多样性并不是一个重要特征。然而,在 OUHANDS 数据集上进行的微调在亮度异质性更明显的情况下最为有效。
5.4. Distance-Diversity Necessity
与光照多样性实验一样,烧蚀距离多样性实验也采用了窗口取样法。为了改变被摄体到摄像机距离的异质性,我们选择了静态基础接近零的窗口: [0.04, 2.8], [0.04, 5], [0.04, 11], [0.04, 65]. 距离系数按边界框面积与图像面积之比计算:
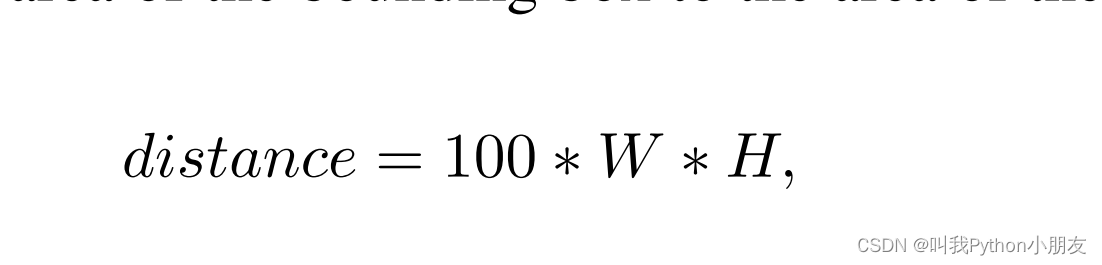
其中,W、H 分别是手势边界框的宽度和高度; 由于 HaGRID 中的边界框注释是相对性的,因此省略了图像面积的除法,为了便于感知,我们将结果乘以等于 100 的常数。与其他实验一样,每个类别的训练集为 10,000 个,其余异质特征的分布也被保存下来。
距离-多样性必要性结果。在 HaGRID 测试和 OUHANDS 微调中,分类器和检测器的性能都取决于被摄体到摄像机的距离多样性(见图 5d 和图 6d)。
6.Conclusion
在本文中,我们介绍了名为 HaGRID 的 HAnd 手势识别数据集,它是规模最大、主题和上下文最多样化的 HGR 数据集之一。 它主要用于系统控制设备,但其应用潜力相当巨大。被摄体、被摄体到摄像机的距离、场景和照明条件等特征的异质性会对弹性模型的训练产生积极影响。我们还展示了所选手势类别构建动态手势的能力,并提供了其识别演示。我们在 HaGRID 上的后续工作包括增加手势类别、与目标手势相似的用户手部自然行为样本以及不同主体的平移和旋转样本。整个数据集、其降采样版本、每类 100 张图像的试用版本、预训练模型和动态手势识别演示均可在资源库中公开获取。



















 1122
1122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









