




一、先提前导入相关库
import os
# 加利福尼亚的房屋的数据,自带,用于练习
from sklearn.datasets import fetch_california_housing
# 回归算法所用到的模型
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge, Lasso, LogisticRegression
# 将我们所掌握的数据划分为训练集和测试集
from sklearn.model_selection import train_test_split
# 对特征和目标值进行标准化,一般只有回归时用到标准化,因为标准化要求特征或者目标值连续,而分类属于离散的
from sklearn.preprocessing import StandardScaler
# mean_sqared_error求均方误差,误差越小代表预测越准。
# classification_report的作用是计算分类模型的性能指标,包括precision、recall、f1-score等。
# roc_auc_score也是一种模型的评估方式:ROC曲线
from sklearn.metrics import mean_squared_error, classification_report, roc_auc_score
# 加载和导出模型,还有一些其他对模型的操作
import joblib
# 这俩老演员了
import pandas as pd
import numpy as np
二、线性回归之正规方程LinearRegression
1、原理介绍:
对于原理,我觉得用代码一起讲解是最好的,我们所获取到的加利福尼亚的房子的数据有八个特征值,而每个样本的八个特征值都不相同,我们就是要自己写一个线性公式,没错,是自己写,也可以说是自己简单预测一个线性公式,来假设这个公式符合:y = Xβ + ϵ
目标值(房屋价值)y和回归系数β表示的都是列向量,而X表示的是所有样本(所有房子)的特征值(每行都表示一个房子的8个特征值),即X为特征矩阵
我们所掌握的样本数据中已知的是y和X,我们所要求的就是回归系数β和误差ϵ(误差在模型训练结束后并不包含在公式中,只是评估模型的一种关键指标)
☆ 注意:误差是评估模型好坏的关键,评判方法有:均方误差(MSE),绝对误差(MAE)等。而我们采用的是均方误差,公式为:
我们的目标是要得到最小的均方误差,所以可以引出代价函数:
所以我们的目标就明确为要去最小化代价函数J(β)
- m:训练样本的数量(为什么分母不是m而是2m,是因为当对损失函数求导时可以抵消求导后由二次幂求导所产生的2)
:表示第 i 个样本的预测值
:表示第 i 个样本的真实值
2、公式推导(需要一定的线性代数的基础)
既然要求出β,我们就需要得到β的公式,
为了最小化J(β),所以我们要找到使J(β)最小的β值。可以通过对J(β)关于 β 求导并令其导数为零
第一步(求导):
第二步(令导数为0):
第三步(代入导数为0): ,可得:
第四步(左乘 ):
即最后的公式为:
所以,函数LinearRegression中对模型的训练其实就是按照这个公式来求回归系数的
3、相关代码
"""
线性回归直接预测房子价格,房子有八个特征,最终的目标值就是房子的价格
"""
# 获取数据
fe_cal = fetch_california_housing(data_home='./data')
# print(fe_cal.DESCR)
print("获取特征值:")
print(fe_cal.data.shape)
print("-" * 100)
print(fe_cal.data[0])
print("-" * 100)
print(fe_cal.target.shape)
print("-" * 100)
print(fe_cal.feature_names)
print("-" * 100)
x_train, x_test, y_train, y_test = train_test_split(fe_cal.data, fe_cal.target, test_size=0.25, random_state=42)
print("训练集大小:", x_train.shape[0])
print("测试集大小:", x_test.shape[0])
# 对特征值进行标准化
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
# 对目标值进行标准化:(回归的时候,目标值是连续的,需要进行标准化。但是分类的时候,目标值是离散的,不需要进行标准化)
std_y = StandardScaler()
print("转换前:", y_train.shape)
y_train = std_y.fit_transform(y_train.reshape(-1, 1)) # reshape(-1, 1)是为了将y_train转换为二维数组
y_test = std_y.transform(y_test.reshape(-1, 1))
print("转换后:", y_train.shape)
# 训练模型
# LinearRegression线性回归,正规方程求解方式预测结果
# 除了LinearRegression,还可以选择SGDRegressor随机梯度下降法、Ridge、Lasso、LogisticRegression逻辑回归等
# 1、选择估计器
lr = LinearRegression()
# 2、训练模型
lr.fit(x_train, y_train)
print("回归系数:", lr.coef_)
# 3、预测结果
y_pred = lr.predict(x_test)
# 由于目标值之前进行过标准化,所以要想得到真实数据,需要进行反标准化
print("正规方程测试集里面每个房子的预测价格:", std_y.inverse_transform(y_pred[0:5]))
# mean_squared_error计算均方误差,均方误差的计算公式是(y_true - y_pred) ** 2
print("正规方程的均方误差:", mean_squared_error(y_test, y_pred))
输出结果:
获取特征值:
(20640, 8)
----------------------------------------------------------------------------------------------------
[ 8.3252 41. 6.98412698 1.02380952 322.
2.55555556 37.88 -122.23 ] // 第一栋房子(第一个样本)的8个特征值
----------------------------------------------------------------------------------------------------
(20640,)
----------------------------------------------------------------------------------------------------
['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude'] // 这就是8个特征值
----------------------------------------------------------------------------------------------------
训练集大小: 15480
测试集大小: 5160
转换前: (15480,)
转换后: (15480, 1)
回归系数: [[ 0.73767583 0.10445214 -0.26153484 0.30179038 -0.00142379 -0.03563558 -0.77320342 -0.7512954 ]] // 8个特征值在公式中所表示的系数(也叫回归系数)
正规方程测试集里面每个房子的预测价格: [[0.72412832]
[1.76677807]
[2.71151581]
[2.83601179]
[2.603755 ]
正规方程的均方误差: 0.40554801530203366
三、保存和加载模型
1、保存模型
# 保存模型,通常在fit之后,以便后续使用
os.unlink('./tmp/test.pkl') # 删除之前的模型文件
joblib.dump(lr, './tmp/test.pkl') # 保存模型
2、加载模型
# 模拟上线时,加载保存的模型
model = joblib.load('./tmp/test.pkl')
# 因为目标值之前进行过标准化,所以要想得到真实数据,需要进行反标准化
y_pred = model.predict(x_test)
print("加载模型预测的房子价格:", std_y.inverse_transform(y_pred[0:5]))
print("加载模型的均方误差:", mean_squared_error(y_test, y_pred))
输出结果:
加载模型预测的房子价格: [[0.72412832]
[1.76677807]
[2.71151581]
[2.83601179]
[2.603755 ]]
加载模型的均方误差: 0.40554801530203366
四、 线性回归之随机梯度下降法SGDRegressor
1、原理介绍:
同正规方程一样,梯度下降仍然需要用到代价函数:
只是不同的是对β的求解方式,在梯度下降的方法中是通过方程:(α代表学习率,也是梯度下降的速度)来不断更新回归系数β的,相当于不断地往下走,来找到J(β)最接近于最小值的回归系数
2、相关代码:
fe_cal = fetch_california_housing(data_home='./data')
x_train, x_test, y_train, y_test = train_test_split(fe_cal.data, fe_cal.target, test_size=0.25, random_state=42)
print("训练集大小:", x_train.shape[0])
print("测试集大小:", x_test.shape[0])
# 对特征值进行标准化
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
# 对目标值进行标准化:(回归的时候,目标值是连续的,需要进行标准化。但是分类的时候,目标值是离散的,不需要进行标准化)
std_y = StandardScaler()
# reshape(-1, 1)是为了将y_train转换为二维数组.flatten()是为了将y_train转换为一维数组
y_train = std_y.fit_transform(y_train.reshape(-1, 1)).flatten()
y_test = std_y.transform(y_test.reshape(-1, 1)).flatten()
# 训练模型
# 梯度下降去进行房价预测,数据量大要用这个
# learning_rate的不同方式,代表学习率变化的算法不一样,比如constant,invscaling,adaptive
# 默认可以去调 eta0 = 0.008,会改变learning_rate的初始值
# learning_rate='optimal',alpha是正则化力度,但是会影响学习率的值,由alpha来算学习率
# penalty代表正则化,分为l1和l2
# 1、选择估计器
sgd = SGDRegressor(eta0=0.01, penalty='l2', max_iter=1000)
# 2、开始训练
sgd.fit(x_train, y_train)
print("梯度下降法的回归系数:", sgd.coef_)
# 3、预测结果
y_pred = sgd.predict(x_test)
# 4、反标准化:将预测值转换为真实值,梯度下降得到的是一维数组,需要reshape(-1, 1)转为二维数组才能进行反标准化
print("梯度下降法测试集里面每个房子的预测价格:", std_y.inverse_transform(y_pred.reshape(-1, 1)).flatten()[0:5])
print("梯度下降法的均方误差:", mean_squared_error(y_test, y_pred))
输出结果:
训练集大小: 15480
测试集大小: 5160
梯度下降法的回归系数: [ 0.72603921 0.10797634 -0.2822245 0.28763139 0.01149968 -0.01166055
-0.78129554 -0.75805535]
梯度下降法测试集里面每个房子的预测价格: [0.74149518 1.77028419 2.71977342 2.81252755 2.59795199]
梯度下降法的均方误差: 0.4012287531063081
五、其他回归方式(我也不是特别了解的,只是学到了,补充一下)
1、Ridge回归(岭回归)
fe_cal = fetch_california_housing(data_home='./data')
x_train, x_test, y_train, y_test = train_test_split(fe_cal.data, fe_cal.target, test_size=0.25, random_state=42)
print("训练集大小:", x_train.shape[0])
print("测试集大小:", x_test.shape[0])
# 对特征值进行标准化
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
# 对目标值进行标准化:(回归的时候,目标值是连续的,需要进行标准化。但是分类的时候,目标值是离散的,不需要进行标准化)
std_y = StandardScaler()
# reshape(-1, 1)是为了将y_train转换为二维数组.flatten()是为了将y_train转换为一维数组
y_train = std_y.fit_transform(y_train.reshape(-1, 1))
y_test = std_y.transform(y_test.reshape(-1, 1))
# 训练模型
# L1 与 L2 的区别?
# L1正则化产生稀疏的权值, L2正则化产生平滑的权值,
# L1正则化偏向于稀疏,它会自动进行特征选择,去掉一些没用的特征,也就是将这些特征对应的权重置为0.
# L2主要功能是为了防止过拟合,当要求参数越小时,说明模型越简单,而模型越简单则,越趋向于平滑,从而防止过拟合。
# 正则化力度: 大: 参数趋近于0
# 小: 参数变化小(高阶项权重没变)
# 1、选择估计器
# 岭回归,L2正则化,L2正则化会使得系数更小,防止过拟合
ridge = Ridge(alpha=0.02)
# 2、开始训练
ridge.fit(x_train, y_train)
print("岭回归的回归系数:", ridge.coef_)
# 3、预测结果
y_pred = ridge.predict(x_test)
print(y_pred.shape)
# 4、结果评估
print("岭回归的均方误差:", mean_squared_error(y_test, y_pred))
输出结果:
训练集大小: 15480
测试集大小: 5160
岭回归的回归系数: [[ 0.7376747 0.10445357 -0.26153087 0.30178548 -0.00142332 -0.03563565
-0.77318956 -0.75128135]]
(5160, 1)
岭回归的均方误差: 0.405547543599716
2、 Lasso回归
fe_cal = fetch_california_housing(data_home='./data')
x_train, x_test, y_train, y_test = train_test_split(fe_cal.data, fe_cal.target, test_size=0.25, random_state=42)
print("训练集大小:", x_train.shape[0])
print("测试集大小:", x_test.shape[0])
# 对特征值进行标准化
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
# 对目标值进行标准化:(回归的时候,目标值是连续的,需要进行标准化。但是分类的时候,目标值是离散的,不需要进行标准化)
std_y = StandardScaler()
# reshape(-1, 1)是为了将y_train转换为二维数组.flatten()是为了将y_train转换为一维数组
y_train = std_y.fit_transform(y_train.reshape(-1, 1))
y_test = std_y.transform(y_test.reshape(-1, 1))
# 训练模型
# # # Lasso回归去进行房价预测
#alpha就是补偿的系数,越大,则系数越小,越趋向于0
# 1、选择估计器
# Lasso回归,L1正则化,L1正则化会使得系数更小,防止过拟合
lasso = Lasso(alpha=0.001)
# 2、开始训练
lasso.fit(x_train, y_train)
# 3、预测结果
y_pred = lasso.predict(x_test)
# 4、结果评估
print("Lasso回归的均方误差:", mean_squared_error(y_test, y_pred))
输出结果:
训练集大小: 15480
测试集大小: 5160
Lasso回归的均方误差: 0.4045663920429236
3、逻辑回归
原理:
在了解逻辑回归的原理前,我们要先了解一下sigmoid函数,下图即使sigmoid函数图像:
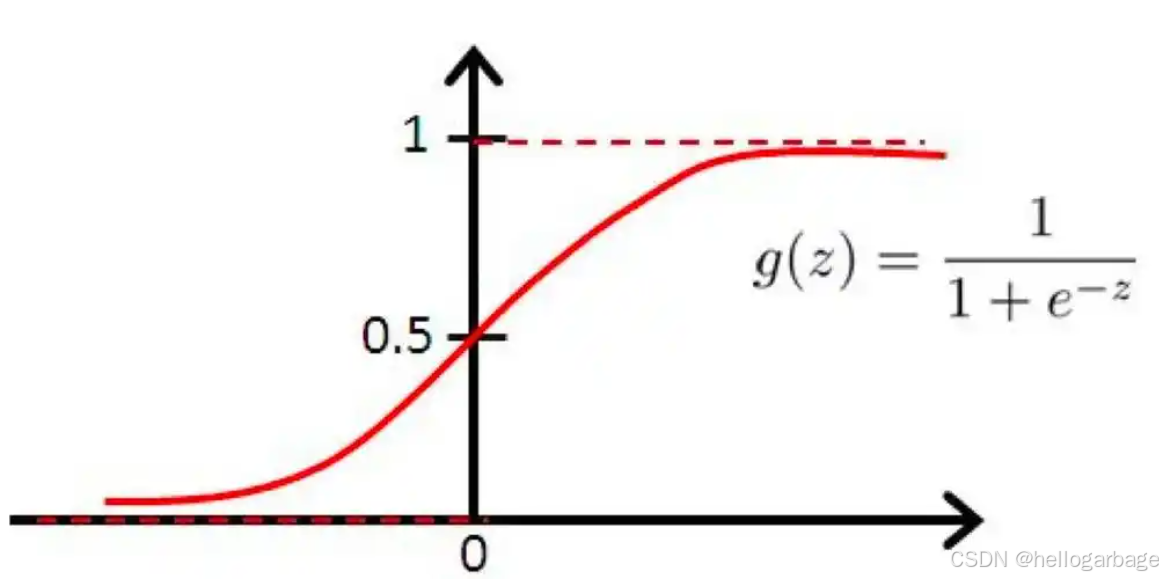
sigmoid函数:
- z:表示目标值,即z=Xβ,也就是说,我们把预测的目标值放到了sigmoid函数上,以此来判断预测值是属于类别0还是类别1
- g(z):可以说是sigmoid函数的值,但是本质上是z=Xβ为类别1的概率
逻辑回归主要用于做二分类,因为预测的目标值为某类别的概率(值在0到1之间),所以说很容易就能通过sigmoid公式得到一个样本是属于类别0还是类别1。也就是说可以通过sigmoid公式来求得概率,然后判断一个人是否患病,或者一个人是否会点击这个广告等
注意:虽然逻辑回归是用于分类,但是实际上还是用到了回归思想,还是要求出β
公式推导:
① 单个样本的概率:假设我们从样本集合中取出第一个样本,
所以第一个样本预测的分类为1的概率为:
第一个样本预测的分类为0的概率为:
所以单个样本的概率可以写为:(似然函数)
② 由似然函数,我们可以得到整个样本集合的似然联合,相当于前面的“代价函数”,公式为:
由于我们的目的是清楚的划分两种类别,所以我们希望单个样本的概率越大越好,所以引出我们的目标就是要最大化联合似然函数
③ 直接最大化联合似然函数,所以通常会对函数取对数,使其具有更好的数值稳定性和计算效率,可得对数似然函数:(ln是底数为e的log)
接下来要开始计算对数似然函数的关于β的导数了,这一部分非常的繁琐
④ 用 对β的求导:
⑤ 链式法则:
⑥ Sigmoid函数求导:
⑦ 代入并化简,即可得:
⑧ 所以可得最终的梯度上升公式(求β)为:
相关代码:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
"""
逻辑回归做二分类预测,进行癌症预测(根据细胞的特征属性)
"""
# 数据下载网址如下
# https://archive.ics.uci.edu/dataset/15/breast+cancer+wisconsin+original
# 构造列标签名字
column = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin', 'Normal Nucleoli',
'Mitoses', 'Class']
# 读取数据
data = pd.read_csv(
"./data/breast-cancer-wisconsin.csv",
names=column)
# print(data.info())
# print("-" * 100)
# print(data.describe(include='all'))
# print("-" * 100)
# 从info中发现,Bare Nuclei是object类型,所以数据中存在缺失值,需要进行处理
print(data['Bare Nuclei'].unique())
data = data.replace(to_replace='?', value=np.nan) # 将?替换为nan
data = data.dropna() # 删除有缺失值的样本
# print(data.info())
# print("-" * 100)
print(data.shape)
# 把第6列的字符串类别转换为数字类别
data[column[6]] = data[column[6]].astype('int16')
# 进行数据的分割,第0列式编号,不可作为特征,所以从第1列开始
x_train, x_test, y_train, y_test = train_test_split(data.iloc[:, 1:10], data.iloc[:, 10], test_size=0.25, random_state=42)
# 进行标准化处理
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
# 逻辑回归模型
lg = LogisticRegression()
lg.fit(x_train, y_train)
print(lg.coef_)
y_pred = lg.predict(x_test)
print("-" * 100)
print("准确率:", lg.score(x_test, y_test))
输出结果:
['1' '10' '2' '4' '3' '9' '7' '?' '5' '8' '6']
(683, 11)
[[1.1619079 0.20642914 0.82309595 0.53589744 0.1256408 1.34610939
1.09376888 0.44268965 0.59488211]]
----------------------------------------------------------------------------------------------------
准确率: 0.9532163742690059


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









