




一、库的导入
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.feature_selection import VarianceThreshold
from sklearn.decomposition import PCA
import jieba
import numpy as np
from sklearn.impute import SimpleImputer
二、数据的特征抽取
1、什么是数据的特征?
首先我们要了解机器学习的目的就是得到机器学习模型,而这个模型可以看成是一个公式,而特征就是影响这个公式结果的条件,就好比说,如果一个人要向银行贷款创业,而银行是否同意会根据这个人的身份,工资,学历,存款,名下产权,所借资金大小等条件进行判断借与不借,这些条件就是所谓的特征。
2、字典数据做特征抽取
a、函数名:DictVectorizer()
def dictvec():
"""
字典数据抽取
:return: None
"""
# 实例化
# sparse改为True,输出的是每个不为零位置的坐标(即稀疏矩阵),可以节省存储空间
# 矩阵中存在大量的0,sparse存储只记录非零位置,节省空间的作用
# Vectorizer中文含义是矢量器的含义,
dict1 = DictVectorizer(sparse=True) # 把sparse改为True看看
# 每个样本都是一个字典,有三个样本
data = dict1.fit_transform([{'city': '北京', 'temperature': 100},
{'city': '上海', 'temperature': 60},
{'city': '深圳', 'temperature': 30}])
print(data)
print('-' * 50)
# 字典中的一些类别数据,分别进行转换成特征
print(dict1.get_feature_names_out())
print('-' * 50)
print(dict1.inverse_transform(data)) #去看每个特征代表的含义,逆转回去
return None
dictvec()
输出结果:
(0, 1) 1.0 //(0, 1)的表示原数据在第0行,第一列,数值为1
(0, 3) 100.0
(1, 0) 1.0
(1, 3) 60.0
(2, 2) 1.0
(2, 3) 30.0
--------------------------------------------------
['city=上海' 'city=北京' 'city=深圳' 'temperature'] //特征名列表
--------------------------------------------------
[{'city=北京': 1.0, 'temperature': 100.0}, {'city=上海': 1.0, 'temperature': 60.0}, {'city=深圳': 1.0, 'temperature': 30.0}]
3、文本数据的做特征抽取
a、函数名:CountVectorizer()
函数作用:获取每个单词在文档中出现的次数,单词以空格隔开
英文单词处理:
def couvec():
# 实例化CountVectorizer
# max_df, min_df整数:指每个词的所有文档词频数不小于最小值,出现该词的文档数目小于等于max_df
# max_df, min_df小数(0-1之间的):某个词的出现的次数/所有文档数量
# min_df=2
# 默认会去除单个字母的单词,默认认为这个词对整个样本没有影响,认为其没有语义
vector = CountVectorizer(min_df=2)
# 调用fit_transform输入并转换数据
res = vector.fit_transform(
["life is short,i like python life",
"life is too long,i dislike python",
"life is short"])
# 打印结果,把每个词都分离了
print(vector.get_feature_names_out())
print('-'*50)
print(res)
print('-'*50)
print(type(res))
# 对照feature_names,标记每个词出现的次数
print('-'*50)
print(res.toarray()) #稀疏矩阵转换为数组
print('-'*50)
#拿每个样本里的特征进行显示
print(vector.inverse_transform(res))
couvec()
输出结果:
['is' 'life' 'python' 'short'] //特征列表:出现次数大于2的词
--------------------------------------------------
(0, 1) 2
(0, 0) 1
(0, 3) 1
(0, 2) 1
(1, 1) 1
(1, 0) 1
(1, 2) 1
(2, 1) 1
(2, 0) 1
(2, 3) 1
--------------------------------------------------
<class 'scipy.sparse._csr.csr_matrix'>
--------------------------------------------------
[[1 2 1 1]
[1 1 1 0]
[1 1 0 1]]
--------------------------------------------------
[array(['life', 'is', 'short', 'python'], dtype='<U6'), array(['life', 'is', 'python'], dtype='<U6'), array(['life', 'is', 'short'], dtype='<U6')]
中文处理:还需用到jieba库
def cutword():
"""
通过jieba对中文进行分词
:return:
"""
con1 = jieba.cut("今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。")
con2 = jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。")
con3 = jieba.cut("如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。")
# 转换成列表
print(type(con1))
print('-' * 50)
# 把生成器转换成列表
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
print(content1)
print(content2)
print(content3)
# 把列表转换成字符串,每个词之间用空格隔开
print('-' * 50)
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1, c2, c3
def hanzivec():
"""
中文特征值化
:return: None
"""
c1, c2, c3 = cutword() #jieba分词好的中文文本
print('-'*50)
print(c1)
print(c2)
print(c3)
print('-'*50)
cv = CountVectorizer()
data = cv.fit_transform([c1, c2, c3])
print(cv.get_feature_names_out())
print(data.toarray())
return None
# cutword()
hanzivec()
输出结果:
<class 'generator'>
--------------------------------------------------
['今天', '很', '残酷', ',', '明天', '更', '残酷', ',', '后天', '很', '美好', ',', '但', '绝对', '大部分', '是', '死', '在', '明天', '晚上', ',', '所以', '每个', '人', '不要', '放弃', '今天', '。']
['我们', '看到', '的', '从', '很', '远', '星系', '来', '的', '光是在', '几百万年', '之前', '发出', '的', ',', '这样', '当', '我们', '看到', '宇宙', '时', ',', '我们', '是', '在', '看', '它', '的', '过去', '。']
['如果', '只用', '一种', '方式', '了解', '某样', '事物', ',', '你', '就', '不会', '真正', '了解', '它', '。', '了解', '事物', '真正', '含义', '的', '秘密', '取决于', '如何', '将', '其', '与', '我们', '所', '了解', '的', '事物', '相', '联系', '。']
--------------------------------------------------
--------------------------------------------------
今天 很 残酷 , 明天 更 残酷 , 后天 很 美好 , 但 绝对 大部分 是 死 在 明天 晚上 , 所以 每个 人 不要 放弃 今天 。
我们 看到 的 从 很 远 星系 来 的 光是在 几百万年 之前 发出 的 , 这样 当 我们 看到 宇宙 时 , 我们 是 在 看 它 的 过去 。
如果 只用 一种 方式 了解 某样 事物 , 你 就 不会 真正 了解 它 。 了解 事物 真正 含义 的 秘密 取决于 如何 将 其 与 我们 所 了解 的 事物 相 联系 。
--------------------------------------------------
['一种' '不会' '不要' '之前' '了解' '事物' '今天' '光是在' '几百万年' '发出' '取决于' '只用' '后天' '含义'
'大部分' '如何' '如果' '宇宙' '我们' '所以' '放弃' '方式' '明天' '星系' '晚上' '某样' '残酷' '每个'
'看到' '真正' '秘密' '绝对' '美好' '联系' '过去' '这样']
[[0 0 1 0 0 0 2 0 0 0 0 0 1 0 1 0 0 0 0 1 1 0 2 0 1 0 2 1 0 0 0 1 1 0 0 0]
[0 0 0 1 0 0 0 1 1 1 0 0 0 0 0 0 0 1 3 0 0 0 0 1 0 0 0 0 2 0 0 0 0 0 1 1]
[1 1 0 0 4 3 0 0 0 0 1 1 0 1 0 1 1 0 1 0 0 1 0 0 0 1 0 0 0 2 1 0 0 1 0 0]]
b、函数名:TfidfVectorizer():
函数作用:Term Frequency-Inverse Document Frequency(词频-逆文档频率),目的是在文档中找出“有代表性”的词。
1. TF-IDF 的公式
TF-IDF 是两个部分的组合:TF 和 IDF。
(1) TF(Term Frequency,词频)
TF(t) = 该词在当前文档中出现的次数 / 当前文档中所有词出现的总数
-
描述某个词 ttt 在当前文档中出现的频率。
-
假设文档长度为 100 个词,其中某个词 ttt 出现了 5 次,则 TF(t)=5/100=0.05。
(2) IDF(Inverse Document Frequency,逆文档频率)
smooth_idf = True时所用公式:
smooth_idf = False时所用公式:
-
N:文档总数。
-
DF(t):包含词 t 的文档数量。
IDF 的作用是降低那些在大多数文档中频繁出现但对区分文档意义不大的词(如“the”, “is”, “and”)的权重。
(3) TF-IDF 的最终值
TF-IDF(t)=TF(t)×IDF(t)
-
词 t 的重要性不仅依赖于它在当前文档中的频率,还受其他文档的频率影响。
# 规范{'l1','l2'},默认='l2'
# 每个输出行都有单位范数,或者:
#
# 'l2':向量元素的平方和为 1。当应用 l2 范数时,两个向量之间的余弦相似度是它们的点积。
#
# 'l1':向量元素的绝对值之和为 1。参见preprocessing.normalize。
# smooth_idf布尔值,默认 = True
# 通过在文档频率上加一来平滑 idf 权重,就好像看到一个额外的文档包含集合中的每个术语恰好一次。防止零分裂。
# 比如训练集中有某个词,测试集中没有,就是生僻词,就会造成n(x)分母为零,log(n/n(x)),从而出现零分裂
def tfidfvec():
"""
中文特征值化,计算tfidf值
:return: None
"""
c1, c2, c3 = cutword()
print(c1, c2, c3)
# print(type([c1, c2, c3]))
tf = TfidfVectorizer(smooth_idf=True)
data = tf.fit_transform([c1, c2, c3])
print(data)
print('-'*50)
print(tf.get_feature_names_out())
print('-'*50)
print(type(data))
print('-'*50)
print(data.toarray())
return None
tfidfvec()
输出结果:
<class 'generator'>
--------------------------------------------------
['今天', '很', '残酷', ',', '明天', '更', '残酷', ',', '后天', '很', '美好', ',', '但', '绝对', '大部分', '是', '死', '在', '明天', '晚上', ',', '所以', '每个', '人', '不要', '放弃', '今天', '。']
['我们', '看到', '的', '从', '很', '远', '星系', '来', '的', '光是在', '几百万年', '之前', '发出', '的', ',', '这样', '当', '我们', '看到', '宇宙', '时', ',', '我们', '是', '在', '看', '它', '的', '过去', '。']
['如果', '只用', '一种', '方式', '了解', '某样', '事物', ',', '你', '就', '不会', '真正', '了解', '它', '。', '了解', '事物', '真正', '含义', '的', '秘密', '取决于', '如何', '将', '其', '与', '我们', '所', '了解', '的', '事物', '相', '联系', '。']
--------------------------------------------------
今天 很 残酷 , 明天 更 残酷 , 后天 很 美好 , 但 绝对 大部分 是 死 在 明天 晚上 , 所以 每个 人 不要 放弃 今天 。 我们 看到 的 从 很 远 星系 来 的 光是在 几百万年 之前 发出 的 , 这样 当 我们 看到 宇宙 时 , 我们 是 在 看 它 的 过去 。 如果 只用 一种 方式 了解 某样 事物 , 你 就 不会 真正 了解 它 。 了解 事物 真正 含义 的 秘密 取决于 如何 将 其 与 我们 所 了解 的 事物 相 联系 。
['一种' '不会' '不要' '之前' '了解' '事物' '今天' '光是在' '几百万年' '发出' '取决于' '只用' '后天' '含义'
'大部分' '如何' '如果' '宇宙' '我们' '所以' '放弃' '方式' '明天' '星系' '晚上' '某样' '残酷' '每个'
'看到' '真正' '秘密' '绝对' '美好' '联系' '过去' '这样']
--------------------------------------------------
<class 'scipy.sparse._csr.csr_matrix'>
--------------------------------------------------
[[0. 0. 0.21821789 0. 0. 0.
0.43643578 0. 0. 0. 0. 0.
0.21821789 0. 0.21821789 0. 0. 0.
0. 0.21821789 0.21821789 0. 0.43643578 0.
0.21821789 0. 0.43643578 0.21821789 0. 0.
0. 0.21821789 0.21821789 0. 0. 0. ]
[0. 0. 0. 0.2410822 0. 0.
0. 0.2410822 0.2410822 0.2410822 0. 0.
0. 0. 0. 0. 0. 0.2410822
0.55004769 0. 0. 0. 0. 0.2410822
0. 0. 0. 0. 0.48216441 0.
0. 0. 0. 0. 0.2410822 0.2410822 ]
[0.15698297 0.15698297 0. 0. 0.62793188 0.47094891
0. 0. 0. 0. 0.15698297 0.15698297
0. 0.15698297 0. 0.15698297 0.15698297 0.
0.1193896 0. 0. 0.15698297 0. 0.
0. 0.15698297 0. 0. 0. 0.31396594
0.15698297 0. 0. 0.15698297 0. 0. ]]
三、特征处理(将特征值拉到一个量纲)
1、归一化处理
- 目的:将数据按比例缩放在一个指定范围(通常为[0, 1] 或者[-1, 1])
- 公式:
- X:原始数据
- Xmin,Xmax:特征的最小值和最大值
def mm():
"""
归一化处理
:return: NOne
"""
# 归一化缺点 容易受极值的影响
#feature_range代表特征值范围,一般设置为(0,1),或者(-1,1),默认是(0,1)
mm = MinMaxScaler(feature_range=(0, 1))
data = mm.fit_transform([[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]])
print(data)
print('-'*50)
out=mm.transform([[1, 2, 3, 4],[6, 5, 8, 7]])
print(out)
return None
#transform和fit_transform不同是,transform用于测试集,而且不会重新找最小值和最大值
# transform相当于把公式上的特征值都确定好了,也可以理解为得到了公式上的参数进而固定公式,而transform就是利用这个公式计算结果
mm()
输出结果:
[[1. 0. 0. 0. ]
[0. 1. 1. 0.83333333]
[0.5 0.5 0.6 1. ]]
--------------------------------------------------
[[-1.96666667 0. -1.4 -6. ]
[-1.8 1.5 -0.4 -5.5 ]]
2、标准化处理
- 目的:将数据调整为均值为0,标准差为1的分布。
- 公式:
- X:原始数据
- μ:特征的均值
- σ:特征的标准差
def stand():
"""
标准化缩放,不是标准正太分布,只均值为0,方差为1的分布
:return:
"""
std = StandardScaler()
data = std.fit_transform([[1., -1., 3.], [2., 4., 2.], [4., 6., -1.]])
print(data)
print('-' * 50)
print(std.mean_) # 原始数据中每列特征的平均值
print('-' * 50)
print(std.var_) # 原始数据每列特征的方差,标准差是方差的平方根
print(std.n_samples_seen_) # 样本数
return data
data=stand()
输出结果:
[[-1.06904497 -1.35873244 0.98058068]
[-0.26726124 0.33968311 0.39223227]
[ 1.33630621 1.01904933 -1.37281295]]
--------------------------------------------------
[2.33333333 3. 1.33333333]
--------------------------------------------------
[1.55555556 8.66666667 2.88888889]
3
四、缺失值处理
#下面是填补,针对删除,可以用pd和np
def im():
"""
缺失值处理
:return:NOne
"""
# NaN, nan,缺失值必须是这种形式,如果是?号(或者其他符号),就要replace换成这种
# 缺失值处理,如果缺失数据是nan就用均值填补
im = SimpleImputer(missing_values=np.nan, strategy='mean')
data = im.fit_transform([[1, 2], [np.nan, 3], [7, 6], [3, 2]])
print(data)
return None
im()
输出结果:
[[1. 2. ]
[3.66666667 3. ]
[7. 6. ]
[3. 2. ]]
五、特征的降维
1、根据方差的阈值进行降维
def var():
"""
特征选择-删除低方差的特征
:return: None
"""
# 默认只删除方差为0,threshold是方差阈值,删除比这个值小的那些特征
var = VarianceThreshold(threshold=0.1)
# 数据按列进行处理,不同列代表不同特征
data = var.fit_transform([[0, 2, 0, 3],
[0, 1, 4, 3],
[0, 1, 1, 3]])
print(data)
# 获得剩余的特征的列编号
print('The surport is %s' % var.get_support(True))
return None
var()
输出结果:
[[2 0]
[1 4]
[1 1]]
The surport is [1 2]
2、根据主成分分析进行降维
def pca():
"""
主成分分析进行特征降维
:return: None
"""
# n_ components:小数 0~1 90% 业界选择 90~95%
# 当n_components的值为0到1之间的浮点数时,表示我们希望保留的主成分解释的方差比例。方差比例是指 得到输出的每一列的方差值和除以原有数据方差之和。
# 具体而言,n_components=0.9表示我们希望选择足够的主成分,以使它们解释数据方差的90%。
# n_components如果是整数 减少到的特征数量
# 原始数据方差
original_value = np.array([[2, 8, 4, 5], [6, 3, 0, 8], [5, 4, 9, 1]])
print(np.var(original_value, axis=0).sum()) #最初数据的方差
print('-'* 50)
pca = PCA(n_components=0.9)
data = pca.fit_transform(original_value)
print(data)
print(type(data))
#计算data的方差
print(np.var(data, axis=0).sum())
print('-'*50)
print(pca.explained_variance_ratio_)
# 计算data的方差占总方差的比例
print(pca.explained_variance_ratio_.sum())
return None
pca()
输出结果:
29.333333333333336
--------------------------------------------------
[[ 1.28620952e-15 3.82970843e+00]
[ 5.74456265e+00 -1.91485422e+00]
[-5.74456265e+00 -1.91485422e+00]]
<class 'numpy.ndarray'>
29.333333333333332
--------------------------------------------------
[0.75 0.25]
1.0
六、机器学习分类算法
1、划分训练集和测试集
- 函数:train_test_split(特征数组, 目标值, test_size, random_state)
- 特征数组:相当于我们已知的条件,当我们训练完模型后,就能通过输入特征来得到目标值。
- 目标值:用来进行分类,不同的目标值代表不同的类别
- test_size:代表输入的特征数组中有多少作为测试集
注意:①特征数组的样本数和目标值的样本数要一一对应
②要清楚知道,此处还处于训练阶段,所以我们既要给出条件(特征)也要给出结果(目标值),而训练完成之后,就可以通过条件来得到目标值。即假设是做猫和狗的分类,开始我们要给出猫的狗的特征样本,并且给出这些特征样本是属于猫还是狗,然后训练完成后,就可以根据特征样本来让模型直接推断是猫还是狗了
#鸢尾花数据集,查看特征,目标,样本量
li = load_iris()
print(li.data.shape)
print(type(li.data))
# 150个样本的4个特征
print(li.data)
print("-" * 100)
print("目标值(分类情况):")
print(li.target)
#print("-" * 100)
#print(li.DESCR) # 数据集的一些描述
print("-" * 100)
print(li.feature_names)
print(li.target_names)
print("-" * 100)
# 注意返回值, 训练集 train x_train, y_train 测试集test x_test, y_test,顺序千万别搞错了
# 默认是乱序的,random_state为了确保两次的随机策略一致,就会得到相同的随机数据,往往会带上
# test_size=0.25代表测试集占比为0.25,训练集占比为0.75
x_train, x_test, y_train, y_test = train_test_split(li.data, li.target, test_size=0.3, random_state=1)
print("划分后的训练集特征:")
print(x_train) # 划分后的训练集特征
print("-" * 100)
print("划分后的训练集目标值:")
print(y_train) # 划分后的训练集目标值
print("-" * 100)
print("划分后的测试集特征:")
print(x_test) # 划分后的测试集特征
print("-" * 100)
print("划分后的测试集目标值:")
print(y_test) # 划分后的测试集目标值
(150, 4)
<class 'numpy.ndarray'>
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
.......................... //太长了,150个样本,我删掉了一些
[6.7 3.3 5.7 2.5]
[6.7 3. 5.2 2.3]
[6.3 2.5 5. 1.9]
[6.5 3. 5.2 2. ]
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
----------------------------------------------------------------------------------------------------目标值(分类情况):
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
----------------------------------------------------------------------------------------------------['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
['setosa' 'versicolor' 'virginica']
----------------------------------------------------------------------------------------------------划分后的训练集特征:
[[7.7 2.6 6.9 2.3]
[5.7 3.8 1.7 0.3]
[5. 3.6 1.4 0.2]
[4.8 3. 1.4 0.3]
.........................
[7.2 3. 5.8 1.6]
[5.7 2.6 3.5 1. ]
[6.3 2.8 5.1 1.5]
[6.4 3.1 5.5 1.8]
[6.3 2.5 4.9 1.5]
[6.7 3.1 5.6 2.4]
[4.9 3.6 1.4 0.1]]
----------------------------------------------------------------------------------------------------
划分后的训练集目标值:
[2 0 0 0 1 0 0 2 2 2 2 2 1 2 1 0 2 2 0 0 2 0 2 2 1 1 2 2 0 1 1 2 1 2 1 0 0
0 2 0 1 2 2 0 0 1 0 2 1 2 2 1 2 2 1 0 1 0 1 1 0 1 0 0 2 2 2 0 0 1 0 2 0 2
2 0 2 0 1 0 1 1 0 0 1 0 1 1 0 1 1 1 1 2 0 0 2 1 2 1 2 2 1 2 0]
----------------------------------------------------------------------------------------------------
划分后的测试集特征:
[[5.8 4. 1.2 0.2]
[5.1 2.5 3. 1.1]
[6.6 3. 4.4 1.4]
[6.4 3.2 4.5 1.5]
[6. 2.9 4.5 1.5].........................
[4.4 3.2 1.3 0.2]
[5.7 2.8 4.1 1.3]
[5.5 4.2 1.4 0.2]
[5.1 3.8 1.5 0.3]
[6.3 2.9 5.6 1.8]
[6.6 2.9 4.6 1.3]]
----------------------------------------------------------------------------------------------------
划分后的测试集目标值:
[0 1 1 0 2 1 2 0 0 2 1 0 2 1 1 0 1 1 0 0 1 1 1 0 2 1 0 0 1 2 1 2 1 2 2 0 1
0 1 2 2 0 2 2 1]
2、使用转换器处理特征(归一化,标准化,降维等)
使用转换器(标准化)
std = StandardScaler()
x_train_transform = std.fit_transform(x_train_transform)
x_test_transform = std.transform(x_test_transform)
# 使用转换器(归一化)
# mm = MinMaxScaler()
# x_train_transform = mm.fit_transform(x_train_transform)
# x_test_transform = mm.transform(x_test_transform)
print(x_train_transform[0:10])
输出结果:
[[ 2.26050169 -1.05089682 1.77622921 1.42370971]
[-0.11897377 1.82764665 -1.14491883 -1.14263397]
[-0.95179019 1.3478894 -1.3134466 -1.27095115]
[-1.18973773 -0.09138233 -1.3134466 -1.14263397]
[-0.71384264 -0.8110182 0.0909515 0.26885505]
[-0.83281641 0.86813216 -1.25727068 -1.27095115]
[-0.35692132 1.10801078 -1.36962252 -1.27095115]
[ 2.26050169 1.82764665 1.66387736 1.29539252]
[ 1.3087115 0.14849629 0.93359035 1.16707534]
[ 1.7846066 -0.33126096 1.43917367 0.78212379]]
3、使用估计器训练模型
# 估计器:K近邻,贝叶斯,决策树
# 使用分类估计器(K近邻)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train_transform, y_train)
print("准确率:", knn.score(x_test_transform, y_test))
# 使用分类估计器(贝叶斯)
# mlb = MultinomialNB(alpha=1.0)
# x_train_transform = mlb.fit(x_train_transform, y_train)
# print("准确率:", mlb.score(x_test_transform, y_test))
# 用决策树进行预测
# dec = DecisionTreeClassifier()
# dec.fit(x_train_transform, y_train)
# print("准确率:", dec.score(x_test_transform, y_test))
输出结果:
准确率: 0.9555555555555556(其实不用标准化和归一化得到的准确率更高)
4、采用网格搜索,调整超参数
x_train, x_test, y_train, y_test = train_test_split(li.data, li.target, test_size=0.3, random_state=1)
# 采用K近邻估计器
knn = KNeighborsClassifier(n_neighbors=5)
# 定义参数网格
param_grid = {
'n_neighbors': [3, 5, 6, 10, 12],
'weights': ['uniform', 'distance'], }
# cv代表把训练集的数据分为三份,然后依次选择两份用作训练,一份用作测试
gc = GridSearchCV(knn, param_grid=param_grid, cv=3)
# 按照设置好的网格进行训练
gc.fit(x_train, y_train)
print("在测试集上准确率:", gc.score(x_test, y_test))
print("在交叉验证当中最好的结果:", gc.best_score_) #最好的结果
print("最优参数:", gc.best_params_)
输出结果:
在测试集上准确率: 0.9777777777777777
在交叉验证当中最好的结果: 0.9619047619047619
最优参数: {'n_neighbors': 5, 'weights': 'uniform'}
七、分类模型评估
1、验证准确率:
估计器.score()函数进行准确率测试
2、混淆矩阵(适用于多分类)
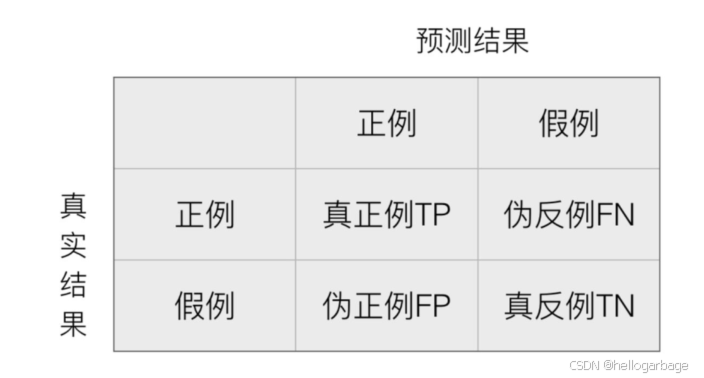
精确率:预测结果为正例样本中,真实为正例的比例(查的准)(TP/(TP+FP))
召回率:真实为正例的样本中预测结果为正例的比例(查的全,对正样本的区别能力)(TP/(TP+FN))
其他分类标准:F1-score:反映模型的稳健性(2*TP / (2 * TP + FN + FP))
相关函数:sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None )
- y_true:真实目标值
- y_pred:估计器预测目标值
- labels:指定类别对应的数组(指定要看哪些类别,相当于指定看哪些目标值的数据)
- target_names:目标类别名称(指定类别的名称,不设置的话,类别默认按照目标值返回)
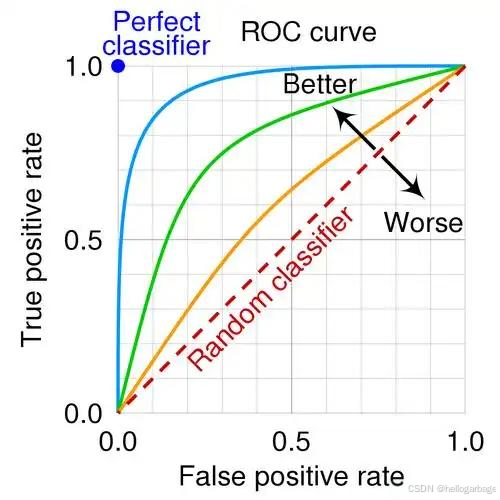
3、ROC曲线和AUC指标
AUC 是 ROC 曲线下方的面积
ROC 曲线每个点对应着一个分类器的不同阈值。 通过改变阈值, 可以得到不同的真阳性率(TPR) 和假阳性率(FPR) , 进而绘制出一条完整的 ROC 曲线。
曲线越靠近左上角,曲线下方的面积越大,代表AUC越大,模型的性能越好
ROC曲线横轴:FPR = FP / (FP + TN) 表示正类预测错误,这个值越小越好
ROC曲线纵轴:TPR = TP / (TP + FN) 表示正类预测正确,这个值越大越好
八、个人对机器学习过程的理解
1、获取原始数据:先获取数据后,对数据进行处理(清洗),通常使用pandas以及正则表达式等,包括处理缺失数据,或者噪声(噪声指的是那些对预测结果影响不大的一些特征)(注:本篇文章完全没涉及这一步,而是直接采用处理好的数据来训练模型)
2、通过TfidfVectorizer,Countvectorizer,DictVectorizer对数据进行特征提取
3、如果是非文本数据,则可能要进行归一化(MinMaxScaler)或者标准化处理(StandardScaler)
4、对数据进行降维(PCA或者VarianceThreshold),去掉一些关系不大的特征
5、划分测试集和训练集,通过train_test_split,分别获取训练集的特征和目标值,以及测试集的特征和目标值
6、选择估计器训练模型(估计器有K近邻KNeighborsClassifier,朴素贝叶斯MultinomialNB,决策树DecisionTreeClassifier)
7、使用估计器开始训练(fit)
8、通过估计器自身的score函数来测试准确率
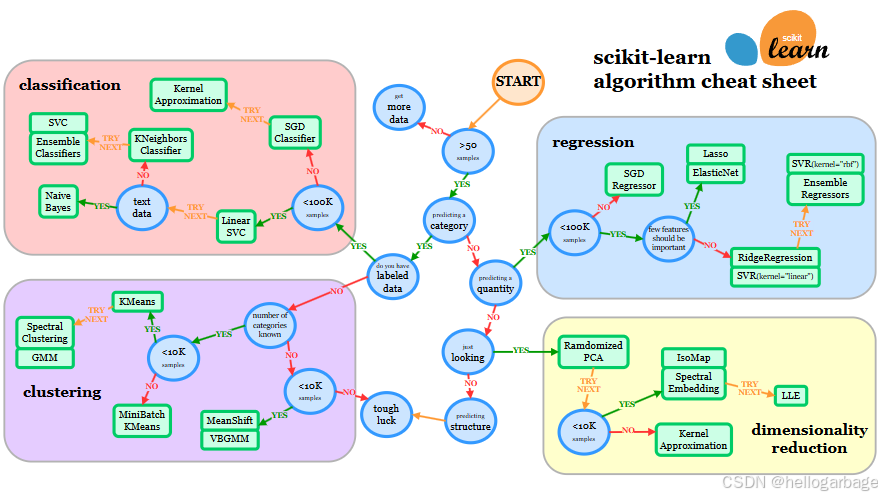
以下配上一个sklearn官网的估计器选择图,属于官方推荐

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









