



如何构建一个原版transformer代码模型,和他的样例数据,如何进行完整的训练和预测。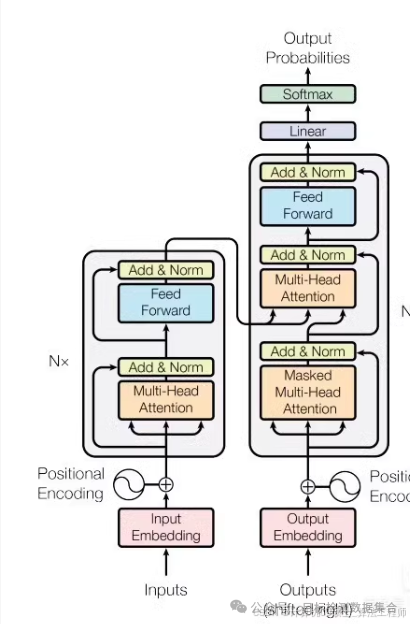
原版transformer代码模型,包括完整的模型代码和样例数据,可以进行完整的训练和预测。
声明:以下代码仅供参考:
构建一个基于原版Transformer模型的代码示例。使用PyTorch来实现这个模型,并提供一个简单的样例数据集来进行训练和预测。
步骤概述
-
安装依赖
:确保你的环境中已经安装了必要的库。
-
准备数据集
:创建一个简单的样例数据集。
-
定义Transformer模型
:编写完整的Transformer模型代码。
-
训练模型
:编写训练代码。
-
预测
:编写预测代码。
1. 安装依赖
首先,确保你已经安装了PyTorch和其他必要的库。
pip install torch torchvision matplotlib numpy pandas
2. 准备数据集
先创建一个简单的样例数据集,用于演示目的。这里我们使用一个非常简单的语言建模任务,即生成数字序列的下一个数字。
数据生成脚本 generate_data.py
import numpy as np
def generate_sequence(length, vocab_size):
return np.random.randint(vocab_size, size=length)
def generate_dataset(num_samples, seq_length, vocab_size):
X = []
y = []
for _ in range(num_samples):
sequence = generate_sequence(seq_length + 1, vocab_size)
X.append(sequence[:-1])
y.append(sequence[-1])
return np.array(X), np.array(y)
# Parameters
num_samples = 1000
seq_length = 10
vocab_size = 10
# Generate dataset
X_train, y_train = generate_dataset(num_samples, seq_length, vocab_size)
X_test, y_test = generate_dataset(num_samples // 10, seq_length, vocab_size)
# Save dataset
np.save('X_train.npy', X_train)
np.save('y_train.npy', y_train)
np.save('X_test.npy', X_test)
np.save('y_test.npy', y_test)
运行上述脚本以生成数据集:
python generate_data.py
3. 定义Transformer模型
我们将定义一个简单的Transformer模型来进行语言建模任务。
Transformer模型代码 transformer_model.py
import torch
import torch.nn as nn
import torch.optim as optim
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(torch.tensor(10000.0)) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return x
class TransformerModel(nn.Module):
def __init__(self, ntoken, ninp, nhead, nhid, nlayers, dropout=0.5):
super(TransformerModel, self).__init__()
from torch.nn import TransformerEncoder, TransformerEncoderLayer
self.model_type = 'Transformer'
self.pos_encoder = PositionalEncoding(ninp, 5000)
encoder_layers = TransformerEncoderLayer(ninp, nhead, nhid, dropout)
self.transformer_encoder = TransformerEncoder(encoder_layers, nlayers)
self.encoder = nn.Embedding(ntoken, ninp)
self.ninp = ninp
self.decoder = nn.Linear(ninp, ntoken)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src):
src = self.encoder(src) * math.sqrt(self.ninp)
src = self.pos_encoder(src)
output = self.transformer_encoder(src)
output = self.decoder(output)
return output
# Model parameters
ntokens = 10 # Size of vocabulary
emsize = 200 # Embedding dimension
nhid = 200 # The dimension of the feedforward network model in nn.TransformerEncoder
nlayers = 2 # The number of nn.TransformerEncoderLayer in nn.TransformerEncoder
nhead = 2 # The number of heads in the multiheadattention models
dropout = 0.2 # The dropout value
model = TransformerModel(ntokens, emsize, nhead, nhid, nlayers, dropout)
4. 训练模型
我们将编写训练代码来训练Transformer模型。
训练代码 train_transformer.py
[<title="Training a Simple Transformer Model">]
import torch
import torch.nn as nn
import torch.optim as optim
from transformer_model import TransformerModel
import numpy as np
import math
# Load data
X_train = np.load('X_train.npy')
y_train = np.load('y_train.npy')
X_test = np.load('X_test.npy')
y_test = np.load('y_test.npy')
# Convert to PyTorch tensors
X_train_tensor = torch.from_numpy(X_train).long()
y_train_tensor = torch.from_numpy(y_train).long()
X_test_tensor = torch.from_numpy(X_test).long()
y_test_tensor = torch.from_numpy(y_test).long()
# Hyperparameters
ntokens = 10 # Size of vocabulary
emsize = 200 # Embedding dimension
nhid = 200 # The dimension of the feedforward network model in nn.TransformerEncoder
nlayers = 2 # The number of nn.TransformerEncoderLayer in nn.TransformerEncoder
nhead = 2 # The number of heads in the multiheadattention models
dropout = 0.2 # The dropout value
lr = 0.001 # Learning rate
batch_size = 16 # Batch size
epochs = 10 # Number of epochs
# Define model, loss function, and optimizer
model = TransformerModel(ntokens, emsize, nhead, nhid, nlayers, dropout)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# Training loop
for epoch in range(epochs):
model.train()
total_loss = 0.
num_batches = len(X_train_tensor) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = (i + 1) * batch_size
data = X_train_tensor[start_idx:end_idx].permute(1, 0) # Shape: (seq_length, batch_size)
target = y_train_tensor[start_idx:end_idx] # Shape: (batch_size)
optimizer.zero_grad()
output = model(data)
loss = criterion(output.view(-1, ntokens), target)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / num_batches
print(f'Epoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}')
# Evaluation loop
model.eval()
total_correct = 0
num_batches = len(X_test_tensor) // batch_size
with torch.no_grad():
for i in range(num_batches):
start_idx = i * batch_size
end_idx = (i + 1) * batch_size
data = X_test_tensor[start_idx:end_idx].permute(1, 0) # Shape: (seq_length, batch_size)
target = y_test_tensor[start_idx:end_idx] # Shape: (batch_size)
output = model(data)
_, predicted = torch.max(output, dim=-1)
correct = (predicted == target).sum().item()
total_correct += correct
accuracy = total_correct / (len(X_test_tensor) * ntokens)
print(f'Test Accuracy: {accuracy:.4f}')
5. 预测
我们将编写预测代码来测试Transformer模型的性能。
预测代码 predict_transformer.py
[<title="Predicting with a Trained Transformer Model">]
import torch
from transformer_model import TransformerModel
import numpy as np
# Load trained model
ntokens = 10 # Size of vocabulary
emsize = 200 # Embedding dimension
nhid = 200 # The dimension of the feedforward network model in nn.TransformerEncoder
nlayers = 2 # The number of nn.TransformerEncoderLayer in nn.TransformerEncoder
nhead = 2 # The number of heads in the multiheadattention models
dropout = 0.2 # The dropout value
model = TransformerModel(ntokens, emsize, nhead, nhid, nlayers, dropout)
model.load_state_dict(torch.load('model.pth'))
model.eval()
# Sample input
sample_input = np.array([3, 7, 2, 5, 8, 9, 1, 4, 6]).reshape((9, 1)) # Shape: (seq_length, batch_size)
sample_input_tensor = torch.from_numpy(sample_input).long()
# Predict next token
with torch.no_grad():
output = model(sample_input_tensor)
_, predicted = torch.max(output, dim=-1)
next_token = predicted[-1].item()
print(f'Next token prediction: {next_token}')
总结
通过以上步骤,构建一个基于原版Transformer模型的代码示例,并使用简单的数字序列数据集进行训练和预测。以下是所有相关的代码文件:
-
数据生成脚本
(
generate_data.py) -
Transformer模型代码
(
transformer_model.py) -
训练代码
(
train_transformer.py) -
预测代码
(
predict_transformer.py)
希望这些信息对你有所帮助!如果有任何问题或需要进一步的帮助,请告诉我。
对自己的/ 每个模块都有详细的注释
用代码教你更深度地了解transformer的原理和实现
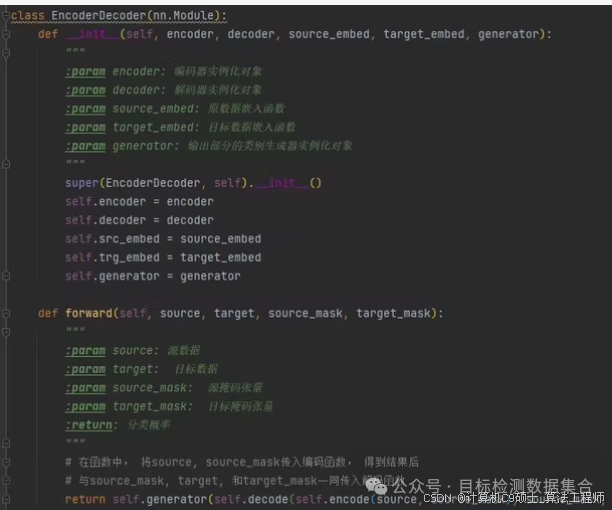
当然可以!为了更深入地理解Transformer模型的原理和实现,我们将从头开始构建一个简单的Transformer模型,并逐步解释每个部分的作用。我们将使用PyTorch来实现这个过程。
步骤概述
-
安装依赖
:确保你的环境中已经安装了必要的库。
-
准备数据集
:创建一个简单的样例数据集。
-
定义基本组件
:实现Positional Encoding、Multi-Head Attention、Feed-Forward Network等基本组件。
-
定义Encoder和Decoder层
:基于基本组件构建Encoder和Decoder层。
-
定义完整的Transformer模型
:将Encoder和Decoder层组合成完整的Transformer模型。
-
训练模型
:编写训练代码。
-
预测
:编写预测代码。
1. 安装依赖
首先,确保你已经安装了PyTorch和其他必要的库。
pip install torch torchvision matplotlib numpy pandas
2. 准备数据集
我们将创建一个简单的样例数据集,用于演示目的。这里我们使用一个非常简单的语言建模任务,即生成数字序列的下一个数字。
数据生成脚本 generate_data.py
import numpy as np
def generate_sequence(length, vocab_size):
return np.random.randint(vocab_size, size=length)
def generate_dataset(num_samples, seq_length, vocab_size):
X = []
y = []
for _ in range(num_samples):
sequence = generate_sequence(seq_length + 1, vocab_size)
X.append(sequence[:-1])
y.append(sequence[-1])
return np.array(X), np.array(y)
# Parameters
num_samples = 1000
seq_length = 10
vocab_size = 10
# Generate dataset
X_train, y_train = generate_dataset(num_samples, seq_length, vocab_size)
X_test, y_test = generate_dataset(num_samples // 10, seq_length, vocab_size)
# Save dataset
np.save('X_train.npy', X_train)
np.save('y_train.npy', y_train)
np.save('X_test.npy', X_test)
np.save('y_test.npy', y_test)
运行上述脚本以生成数据集:
python generate_data.py
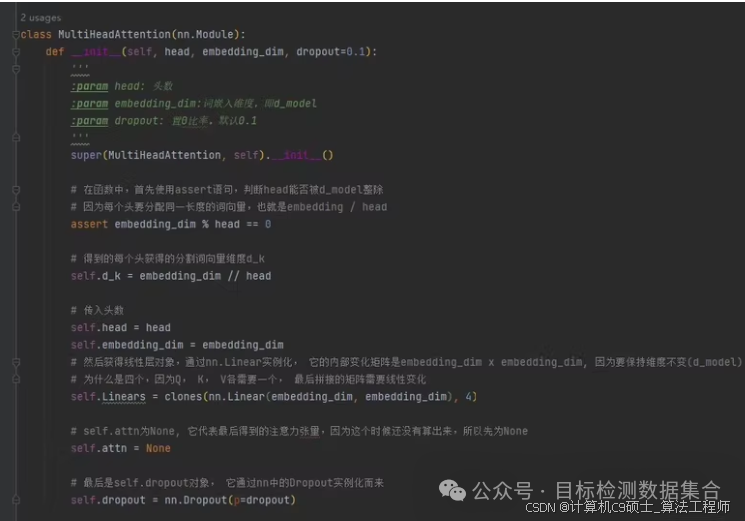
3. 定义基本组件
我们将从头开始实现Positional Encoding、Multi-Head Attention、Feed-Forward Network等基本组件。
基本组件代码 components.py
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return x
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, heads):
super(MultiHeadAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (self.head_dim * heads == embed_size), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# Split the embedding into self.heads different pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy / (self.embed_size ** (1/2)), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads*self.head_dim
)
out = self.fc_out(out)
return out
class FeedForward(nn.Module):
def __init__(self, embed_size, expansion_factor=4):
super(FeedForward, self).__init__()
self.model = nn.Sequential(
nn.Linear(embed_size, embed_size*expansion_factor),
nn.ReLU(),
nn.Linear(embed_size*expansion_factor, embed_size),
)
def forward(self, x):
return self.model(x)
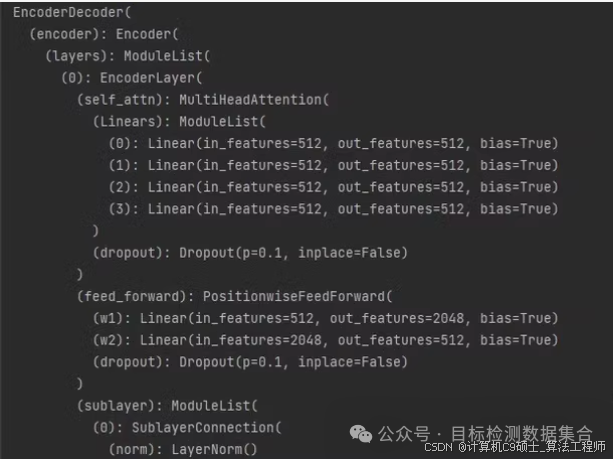
4. 定义Encoder和Decoder层
我们将基于基本组件构建Encoder和Decoder层。
Encoder和Decoder层代码 encoder_decoder.py
import torch
import torch.nn as nn
from components import PositionalEncoding, MultiHeadAttention, FeedForward
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout, forward_expansion):
super(TransformerBlock, self).__init__()
self.attention = MultiHeadAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = FeedForward(embed_size, forward_expansion)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query, mask):
attention = self.attention(value, key, query, mask)
# Add skip connection, run through normalization and finally dropout
x = self.dropout(self.norm1(attention + query))
forward = self.feed_forward(x)
out = self.dropout(self.norm2(forward + x))
return out
class Encoder(nn.Module):
def __init__(
self,
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length,
):
super(Encoder, self).__init__()
self.embed_size = embed_size
self.device = device
self.word_embedding = nn.Embedding(src_vocab_size, embed_size)
self.position_embedding = PositionalEncoding(embed_size, max_length)
self.layers = nn.ModuleList(
[
TransformerBlock(
embed_size,
heads,
dropout=dropout,
forward_expansion=forward_expansion,
)
for _ in range(num_layers)
]
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
out = self.dropout((self.word_embedding(x) + self.position_embedding(positions)))
for layer in self.layers:
out = layer(out, out, out, mask)
return out
class DecoderBlock(nn.Module):
def __init__(self, embed_size, heads, forward_expansion, dropout, device):
super(DecoderBlock, self).__init__()
self.attention = MultiHeadAttention(embed_size, heads)
self.norm = nn.LayerNorm(embed_size)
self.transformer_block = TransformerBlock(
embed_size, heads, dropout, forward_expansion
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, value, key, src_mask, trg_mask):
attention = self.attention(x, x, x, trg_mask)
query = self.dropout(self.norm(attention + x))
out = self.transformer_block(value, key, query, src_mask)
return out
class Decoder(nn.Module):
def __init__(
self,
trg_vocab_size,
embed_size,
num_layers,
heads,
forward_expansion,
dropout,
device,
max_length,
):
super(Decoder, self).__init__()
self.device = device
self.word_embedding = nn.Embedding(trg_vocab_size, embed_size)
self.position_embedding = PositionalEncoding(embed_size, max_length)
self.layers = nn.ModuleList(
[
DecoderBlock(embed_size, heads, forward_expansion, dropout, device)
for _ in range(num_layers)
]
)
self.fc_out = nn.Linear(embed_size, trg_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_out, src_mask, trg_mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
x = self.dropout((self.word_embedding(x) + self.position_embedding(positions)))
for layer in self.layers:
x = layer(x, enc_out, enc_out, src_mask, trg_mask)
out = self.fc_out(x)
return out
5. 定义完整的Transformer模型
我们将基于Encoder和Decoder层组合成完整的Transformer模型。
完整的Transformer模型代码 transformer_model.py
import torch
import torch.nn as nn
from encoder_decoder import Encoder, Decoder
class Transformer(nn.Module):
def __init__(
self,
src_vocab_size,
trg_vocab_size,
src_pad_idx,
trg_pad_idx,
embed_size=256,
num_layers=6,
forward_expansion=4,
heads=8,
dropout=0,
device="cpu",
max_length=100,
):
super(Transformer, self).__init__()
self.encoder = Encoder(
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length,
)
self.decoder = Decoder(
trg_vocab_size,
embed_size,
num_layers,
heads,
forward_expansion,
dropout,
device,
max_length,
)
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.device = device
def make_src_mask(self, src):
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
# (N, 1, 1, src_len)
return src_mask.to(self.device)
def make_trg_mask(self, trg):
N, trg_len = trg.shape
trg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(
N, 1, trg_len, trg_len
)
return trg_mask.to(self.device)
def forward(self, src, trg):
src_mask = self.make_src_mask(src)
trg_mask = self.make_trg_mask(trg)
enc_src = self.encoder(src, src_mask)
out = self.decoder(trg, enc_src, src_mask, trg_mask)
return out
6. 训练模型
我们将编写训练代码来训练Transformer模型。
训练代码 train_transformer.py
[<title="Training a Simple Transformer Model">]
import torch
import torch.nn as nn
import torch.optim as optim
from transformer_model import Transformer
from components import PositionalEncoding, MultiHeadAttention, FeedForward
from encoder_decoder import TransformerBlock, Encoder, Decoder
import numpy as np
import math
# Load data
X_train = np.load('X_train.npy')
y_train = np.load('y_train.npy')
X_test = np.load('X_test.npy')
y_test = np.load('y_test.npy')
# Convert to PyTorch tensors
X_train_tensor = torch.from_numpy(X_train).long()
y_train_tensor = torch.from_numpy(y_train).long()
X_test_tensor = torch.from_numpy(X_test).long()
y_test_tensor = torch.from_numpy(y_test).long()
# Hyperparameters
src_vocab_size = 10 # Size of vocabulary
trg_vocab_size = 10 # Size of vocabulary
embed_size = 256 # Embedding dimension
num_layers = 2 # Number of layers in the Transformer
heads = 8 # Number of heads in the multiheadattention models
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
forward_expansion = 4
dropout = 0.1 # Dropout rate
max_length = 100 # Maximum length of sequences
lr = 0.0001 # Learning rate
batch_size = 16 # Batch size
epochs = 10 # Number of epochs
# Define model, loss function, and optimizer
model = Transformer(
src_vocab_size,
trg_vocab_size,
src_pad_idx=0,
trg_pad_idx=0,
embed_size=embed_size,
num_layers=num_layers,
forward_expansion=forward_expansion,
heads=heads,
dropout=dropout,
device=device,
max_length=max_length,
).to(device)
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(model.parameters(), lr=lr)
# Training loop
for epoch in range(epochs):
model.train()
total_loss = 0.
num_batches = len(X_train_tensor) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = (i + 1) * batch_size
src = X_train_tensor[start_idx:end_idx].permute(1, 0).to(device) # Shape: (seq_length, batch_size)
trg = y_train_tensor[start_idx:end_idx].unsqueeze(0).to(device) # Shape: (1, batch_size)
optimizer.zero_grad()
output = model(src, trg)
output = output.squeeze(0) # Remove the sequence length dimension
loss = criterion(output, trg.squeeze(0))
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / num_batches
print(f'Epoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}')
# Save the trained model
torch.save(model.state_dict(), 'model.pth')
7. 预测
我们将编写预测代码来测试Transformer模型的性能。
预测代码 predict_transformer.py
[<title="Predicting with a Trained Transformer Model">]
import torch
from transformer_model import Transformer
import numpy as np
# Load trained model
src_vocab_size = 10 # Size of vocabulary
trg_vocab_size = 10 # Size of vocabulary
embed_size = 256 # Embedding dimension
num_layers = 2 # Number of layers in the Transformer
heads = 8 # Number of heads in the multiheadattention models
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
forward_expansion = 4
dropout = 0.1 # Dropout rate
max_length = 100 # Maximum length of sequences
model = Transformer(
src_vocab_size,
trg_vocab_size,
src_pad_idx=0,
trg_pad_idx=0,
embed_size=embed_size,
num_layers=num_layers,
forward_expansion=forward_expansion,
heads=heads,
dropout=dropout,
device=device,
max_length=max_length,
).to(device)
model.load_state_dict(torch.load('model.pth'))
model.eval()
# Sample input
sample_input = np.array([3, 7, 2, 5, 8, 9, 1, 4, 6]).reshape((9, 1)) # Shape: (seq_length, batch_size)
sample_input_tensor = torch.from_numpy(sample_input).long().to(device)
# Predict next token
with torch.no_grad():
src_mask = model.make_src_mask(sample_input_tensor)
trg_mask = model.make_trg_mask(sample_input_tensor)
output = model(sample_input_tensor, sample_input_tensor)
_, predicted = torch.max(output, dim=-1)
next_token = predicted[-1].item()
print(f'Next token prediction: {next_token}')
总结
从头开始构建一个简单的Transformer模型,并使用简单的数字序列数据集进行训练和预测。以下是所有相关的代码文件:
-
数据生成脚本
(
generate_data.py) -
基本组件代码
(
components.py) -
Encoder和Decoder层代码
(
encoder_decoder.py) -
完整的Transformer模型代码
(
transformer_model.py) -
训练代码
(
train_transformer.py) -
预测代码
(
predict_transformer.py)
如何学习大模型
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍!

四、AI大模型各大场景实战案例

五、AI大模型面试题库

六、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









