



AI Agent 的发展一直备受瞩目。今天,我们就来深入探讨一种全新的架构——Plan-and-Execute,它正悄然改变着 AI Agent 解决复杂任务的方式。
传统 ReAct 架构的困境
曾经,ReAct(推理 + 行动)架构在 AI 领域占据着重要的一席之地,然而其在实际应用中却暴露出一些关键的短板。
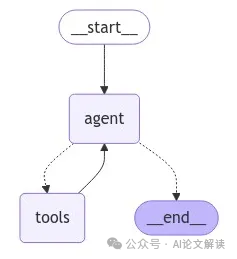
就执行效率而言,它就像一辆在每个路口都要重新启动的老爷车。**传统的 ReAct 风格架构在每完成一个动作后都需要停下来进行思考,才能决定下一步的行动,这使得整个任务执行过程变得极为缓慢,严重影响了工作效率。**就好比你在驾驶一辆汽车,却要在每个交通灯处都重新打火启动,这无疑是一场效率的噩梦。
再看记忆方面,这些 Agent 就如同患上了严重的短期记忆丧失症。一旦任务完成,它们就会把之前学到的所有信息统统忘掉。 这就好比你有一个助手,在完成一项工作后,就把之前积累的经验和知识全部清零,这对于需要长期知识积累和经验复用的复杂任务来说,是一个致命的缺陷。
Plan-and-Execute 架构的优势与组成
优势显著
Plan-and-Execute 架构的出现,为解决这些问题带来了曙光,它具有多方面的显著优势。
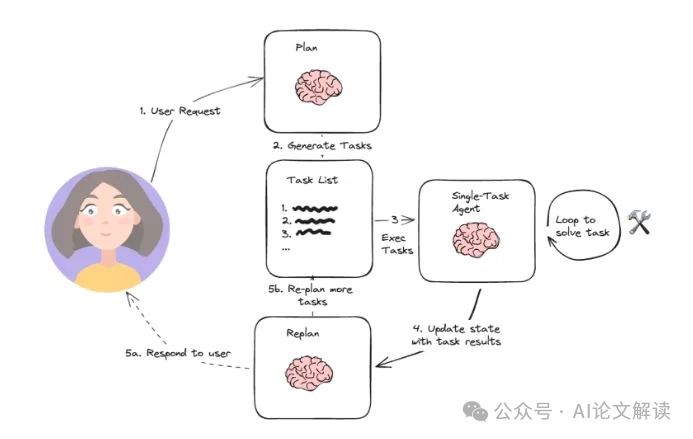
首先,在执行速度上实现了质的飞跃。它能够快速地执行多步工作流程,因为在执行过程中无需在每一个行动后都去咨询大型的 Agent,从而大大减少了不必要的等待时间,使得任务能够高效地推进。
其次,在成本控制上表现出色。相较于 ReAct 架构的 Agent,如果在子任务中使用大型语言模型(LLM)调用,Plan-and-Execute 架构通常可以采用更小的、特定领域的模型。这不仅降低了对计算资源的需求,还能有效减少成本开销,为企业和开发者提供了更经济实惠的解决方案。
最后,在整体性能上更胜一筹。通过强制规划器明确地“思考”完成整个任务所需的所有步骤,它在任务完成率和质量方面都有了显著的提升。这种全面的规划能力使得它能够更好地应对复杂任务,提高任务成功的概率和结果的质量。
核心组件
Plan-and-Execute 架构主要由两个基本组件构成。
一是规划器(Planner),其作用至关重要,它能够促使大型语言模型(LLM)生成一个完成大型任务的多步计划。 在实际的代码实现中,我们可以通过以下方式进行初始化和规划步骤的定义:
planner_prompt = ChatPromptTemplate.from_messages(
"system",
"""For the given objective, come up with a simple step by step plan. \
This plan should involve individual tasks, that if executed correctly will yield the correct answer. Do not add any superfluous steps. \
The result of the final step should be the final answer. Make sure that each step has all the information needed - do not skip steps.""",
),
("placeholder", "{messages}"),
planner = planner_prompt | model.with_structured_output(Plan)
二是执行器(Executor),它负责接受用户查询和计划中的一个步骤,并调用一个或多个工具来完成相应的任务。 以下是执行器的部分代码示例:
async def execute_step(state: PlanExecute):
plan = state["plan"]
plan_str = "\n".join(f"{i+1}. {step}" for i, step in enumerate(plan))
task = plan[0]
agent_response = await agent_executor.ainvoke(
{"messages": [("user", f"""For the following plan:
{plan_str}\n\nYou are tasked with executing step {1}, {task}.""")]}
return {
"past_steps": [(task, agent_response["messages"][-1].content)],
}
工作流程与构建实践
流畅的工作流程
在 Plan-and-Execute 架构中,工作流程清晰而高效。首先,规划器会生成一个多步计划。接着,执行器按照计划中的步骤依次处理,在需要时调用相应的工具。如果在执行过程中出现问题,系统会启动重新规划的机制,确保任务能够顺利进行。这种灵活的工作流程使得该架构能够适应各种复杂多变的任务场景。
构建自己的 Plan-and-Execute Agent
下面我们来看一下如何使用 Python 和 LangGraph 构建一个简单的 Plan-and-Execute Agent。
规划器的构建代码如下:
async def plan_step(state: PlanExecute):
plan = await planner.ainvoke({"messages": [("user", state["input"])]})
return {"plan": plan.steps}
执行器的实现代码为:
async def execute_step(state: PlanExecute):
plan = state["plan"]
plan_str = "\n".join(f"{i+1}. {step}" for i, step in enumerate(plan))
task = plan[0]
task_formatted = f"""For the following plan:
{plan_str}\n\nYou are tasked with executing step {1}, {task}."""
agent_response = await agent_executor.ainvoke(
{"messages": [("user", task_formatted)]}
return {
"past_steps": [(task, agent_response["messages"][-1].content)],
}
重新规划机制的设置代码如下:
class Response(BaseModel):
"""Response to user."""
response: str
class Act(BaseModel):
"""Action to perform."""
action: Union[Response, Plan] = Field(
description="Action to perform. If you want to respond to user, use Response. "
"If you need to further use tools to get the answer, use Plan."
)
replanner_prompt = ChatPromptTemplate.from_template(
"""For the given objective, come up with a simple step by step plan. \
This plan should involve individual tasks, that if executed correctly will yield the correct answer. Do not add any superfluous steps. \
The result of the final step should be the final answer. Make sure that each步 has all the information needed - do not skip steps.
Your objective was this:
{input}
Your original plan was this:
{plan}
You have currently done the follow steps:
{past_steps}
Update your plan accordingly. If no more steps are needed and you can return to the user, then respond with that. Otherwise, fill out the plan. Only add steps to the plan that still NEED to be done. Do not return previously done steps as part of the plan."""
)
replanner = replanner_prompt | model.with_structured_output(Act)
asyncdef replan_step(state: PlanExecute):
output = await replanner.ainvoke(state)
if isinstance(output.action, Response):
return {"response": output.action.response}
else:
return {"plan": output.action.steps}
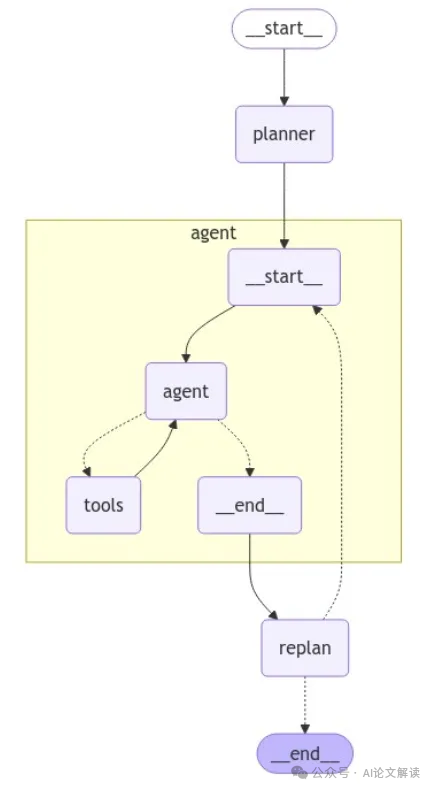
最后,将这些组件整合为一个完整的工作流:
workflow = StateGraph(PlanExecute)
workflow.add_node("planner", plan_step)
workflow.add_node("agent", execute_step)
workflow.add_node("replan", replan_step)
workflow.add_edge(START, "planner")
workflow.add_edge("planner", "agent")
workflow.add_edge("agent", "replan")
workflow.add_conditional_edges(
"replan",
should_end,
["agent", END]
)
app = workflow.compile()
重要意义与应用前景
开启智能新时代
与传统的 AI Agent 相比,Plan-and-Execute 架构具有革命性的意义。传统的 AI Agent 就像按照固定脚本行动的刚性机器人,而 Plan-and-Execute 架构则更像是一位灵活的战略家。它能够预先制定全面的计划,在任务执行过程中遇到意外情况时迅速适应和调整,并且在整个任务执行过程中保持上下文信息,减少了计算开销,极大地提高了任务处理的效率和质量。
希望这篇文章能够帮助大家深入了解 Plan-and-Execute 架构在 AI Agent 领域的重要性和应用潜力。如果您对人工智能感兴趣,欢迎持续关注我们的公众号,获取更多前沿技术资讯!
以上就是今天的全部内容,感谢您的阅读!
如何学习大模型
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍!

四、AI大模型各大场景实战案例

五、AI大模型面试题库

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 1730
1730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









