



transformers 是由 Hugging Face 和社区维护的库,它是一个开源的自然语言处理(NLP)库,广泛用于机器学习和深度学习领域。这个库提供了许多预训练模型和工具,使得开发者和研究人员能够轻松地使用和微调最新的大模型。
在Hugging Face 网站上的模型详情页面,点击Use this model,可以弹出如何使用Transformers库使用模型。会列出pipeline和directly这两种使用方式。
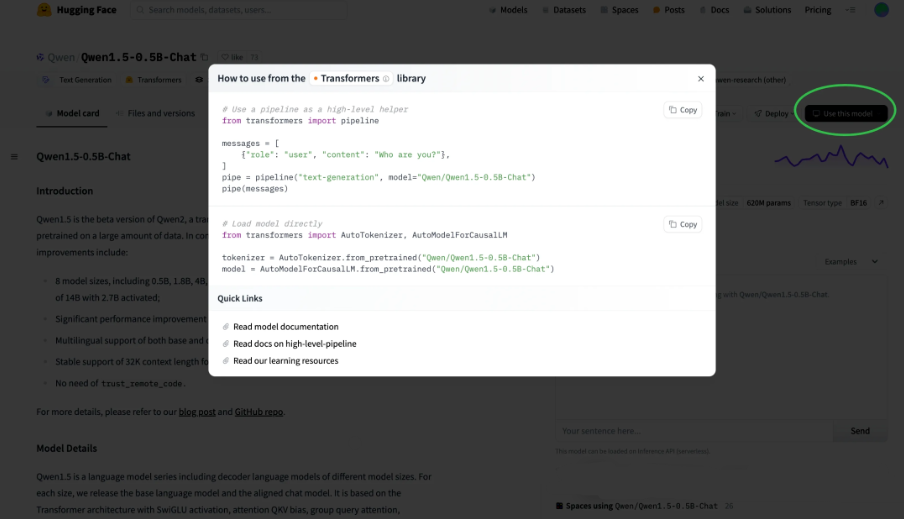
需要先安装Transformer库
pip install transformers
使用 AutoClass类进行推理
Transformers 库中的 AutoClass 提供了自动加载预训练模型和分词器的功能,简化了模型的使用过程。我们可以通过 from_pretrained() 方法快速加载所需的模型和分词器。
下面这段代码是使用AutoClass类推理的完整代码,因为国内网络访问https://huggingface.co需要使用代理服务器才行,所以要配置http_proxy和https_proxy。
核心步骤如下:
- \1. 使用
AutoModelForCausalLM加载模型 - 将会自动从huggingface下载Qwen/Qwen1.5-0.5B-Chat模型到
~/.cache/huggingface/hub中。 - \2. 使用AutoTokenizer加载分词器,加载与模型配套的分词器。
- \3. 构建消息列表messages,包含系统角色和用户角色的消息。
- \4.
tokenizer.apply_chat_template将对话消息格式化为一个适合模型输入的字符串,并在格式化后添加一个生成提示,这个提示告诉模型接下来你应该生成一个回复消息。 - \5. 将文本字符串转换成模型可以处理的PyTorch张量。
- \6. 使用
model.generate生成模型的回复,并制定了模型回复的最大长度是512个token。 - \7. 从生成的token中提取新的文本内容,忽略原始输入的token,只保留输出的token。
- \8. 使用分词器的 batch_decode 方法将生成的token解码回文本
import os
import time
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cpu" # the device to load the model onto
# 需要指定链接https://huggingface.co代理
os.environ["http_proxy"]="http://your.domain.com:8080"
os.environ["https_proxy"]="http://your.domain.com:8080"
# ①从预训练模型库中加载一个名为 "qwen/Qwen1.5-0.5B-Chat" 的因果语言模型,device_map="auto" 参数表示自动选择设备(这里是GPU)
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen1.5-0.5B-Chat",
device_map="auto",
)
# ②加载与模型配套的分词器。
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-0.5B-Chat")
# 定义一个提示(prompt),这是一个问题,要求模型对大型语言模型进行简短介绍。
prompt = "Give me a short introduction to large language model."
# ③创建一个消息列表
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
# ④将对话消息格式化为一个适合模型输入的字符串
text = tokenizer.apply_chat_template(
messages,
tokenize=False, # 表示不对输入进行分词,
add_generation_prompt=True # 表示添加生成提示。
)
# ⑤将字符串转换为模型需要的输入格式,这里指定返回的格式为PyTorch张量,然后将张量移动到之前定义的设备上。
model_inputs = tokenizer([text], return_tensors="pt").to(device)
# ⑥使用模型的 generate 方法生成文本,max_new_tokens=512 限制生成的token数量最多为512个。
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
print(time.time())
# ⑦从生成的token中提取新的文本内容,忽略原始输入的token,只保留输出的token。
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
# ⑧使用分词器的 batch_decode 方法将生成的token解码回文本,并使用 skip_special_tokens=True 忽略特殊的token,然后获取解码后的文本作为模型的响应。
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
print(time.time())
通过统计时间,在我电脑上这段推理需要耗时500秒左右。
如果你没有连接https://huggingface.co的代理,可以提前下载模型,然后在AutoModelForCausalLM.from_pretrained函数中指定模型的本地路径。为了加快下载速度,可以指定从国内镜像地址下载模型。
from huggingface_hub import snapshot_download
snapshot_download(repo_id="Qwen/Qwen1.5-0.5B-Chat", # 指定hf-mirror的repo_id
local_dir="Qwen/Qwen1.5-0.5B-Chat", # 指定文件存储位置
max_workers=8,
endpoint="https://hf-mirror.com" # 指定使用国内镜像地址下载【重要】
)
使用 Pipeline 进行推理
HuggingFace 的 Pipeline 是一种高级工具,它简化了多种常见自然语言处理(NLP)任务的使用流程,使得用户不需要深入了解模型细节,也能够很容易地利用预训练模型来做任务。
Pipeline功能封装了常用任务的处理流程,下面举几个例子:
- \1. 本文生成Pipeline
>>> import os
# 注意os.environ得在import huggingface库相关语句之前执行。
>>> os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
>>> from transformers import pipeline
>>> generator = pipeline(model="openai-community/gpt2")
>>> generator("I can't believe you did such a ", do_sample=False)
# 生成四个不同的输出,只输出新增加续写的部分。
outputs = generator("My tart needs some", num_return_sequences=4, return_full_text=False)
在 transformers 库的 pipeline 功能中,do_sample 参数用于控制生成文本时的行为。当使用生成模型(如GPT系列)时,这个参数特别重要。
- • 如果
do_sample=True,则模型在生成文本时会采用采样策略,这意味着模型在预测下一个词时会考虑其概率分布,并从中随机选择一个词。这种方法可以增加生成文本的多样性,但也可能导致结果的不确定性和不稳定性。 - • 如果
do_sample=False,则模型会采用贪婪策略(greedy decoding)来生成文本,即在每一步选择概率最高的词。这种方法生成的文本可能更加流畅和连贯,但可能缺乏多样性。
do_sample 参数只适用于生成类任务,如文本续写、对话生成等。对于不需要生成文本的任务(如文本分类),这个参数不适用。此外,pipeline 默认使用的是 do_sample=False。
2.情感分类Pipeline
>>> import os
# 注意os.environ得在import huggingface库相关语句之前执行。
>>> os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
>>> from transformers import pipeline
>>> classifier = pipeline(model="distilbert/distilbert-base-uncased-finetuned-sst-2-english")
>>> classifier("This movie is disgustingly good !")
[{'label': 'POSITIVE', 'score': 0.9998536109924316}]
>>> classifier("Director tried too much.")
[{'label': 'NEGATIVE', 'score': 0.9963769316673279}]
3.图片识别Pipeline
>>> import os
# 注意os.environ得在import huggingface库相关语句之前执行。
>>> os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
>>> from transformers import pipeline
>>> captioner = pipeline(model="ydshieh/vit-gpt2-coco-en",
task="image-to-text",
device=0)
>>> captioner("https://modelscope.cn-beijing.oss.aliyuncs.com/open_data/sa-1b-cot-qwen/sa_297788.jpg")
[{'generated_text': 'a man standing in front of a large white building '}]
代码解释:
- \1. task参数的可选值Transformers帮助文档。
- \2. device参数表示在 CPU 或 GPU 上运行模型,
-1通常用于表示使用 CPU。如果你设置一个正整数,模型将在对应的 CUDA 设备(GPU)上运行。例如,如果你有 4 个 GPU,你可以设置 device 为 0 到 3 之间的任何一个数字来指定使用哪个 GPU。
更多用法参考Transformers的pipeline_tutorial。
模型微调
🤗 Transformers 除了可以使用各种任务的预训练模型,也支持针对您特定任务的数据集上进行训练,这种方法称为微调。可以使用🤗 Transformers 的Trainer 对预训练模型进行微调。
第一步,准备一个数据集
这里加载一个美国在线城市指南网站Yelp的评论数据,该数据集可以用于text-classification , sentiment-classification等任务。
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
from datasets import load_dataset
dataset = load_dataset("yelp_review_full") # https://hf-mirror.com/datasets/Yelp/yelp_review_full
dataset["train"][100]
# {'label': 0, 'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
第二步,数据集预处理
在输入模型之前,需要使用分词器tokenizer来处理文本,将它们调整到相同的长度。因此,需要采用填充和截断策略来处理不同长度的序列。填充是指在较短的序列末尾添加特定的标记(如 ),直到它们达到所需的长度。截断则是将较长的序列缩短,去除超出长度限制的部分。
为了高效地处理整个数据集,可以使用Hugging Face的datasets数据集库中的map方法来处理数据集。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
代码解释:
- \1. 从 Hugging Face 的
transformers库中导入了AutoTokenizer类。AutoTokenizer是一个通用的分词器类,可以根据预训练模型的名称自动加载相应的分词器。 - \2. 使用
AutoTokenizer.from_pretrained方法加载了一个预训练的 BERT 分词器。参数"google-bert/bert-base-cased"指定了要加载的预训练模型的名称。bert-base-cased是一个大小写敏感的 BERT 基础模型。 - \3. 定义tokenize_function,调用分词器对数据集中的每个文本(text)进行分词处理。
- •
padding="max_length":将所有输入序列填充到最大长度,以确保所有输入序列的长度相同。 - •
truncation=True:如果输入序列超过最大长度,则将其截断。
使用 dataset.map 方法将 tokenize_function 应用到整个数据集 dataset 上。
- •
batched=True:表示tokenize_function将以批量方式处理数据集中的样本,这通常可以提高处理速度。
也可以选择整个数据集中的一个较小部分来进行微调,创建一个小规模的训练集和测试集,以便在实验或调试过程中减少计算资源的消耗。比如从已经分词处理的数据集tokenized_datasets中分别选择训练集和测试集的前 1000 个样本:
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
通过shuffle对这些样本进行随机打乱。同时,通过设置固定的随机种子 seed=42,确保每次运行时选择的样本顺序一致,便于复现实验结果。
第三步,配置训练参数
🤗 Transformers库提供了一个名为Trainer的类,这个类是专门为训练🤗 Transformers模型而优化的。使用这个Trainer类可以让训练过程变得更简单,因为你不需要手动编写自己的训练循环。
训练开始前,需要加载模型并指定预期的标签数量。以yelp_review_full数据集为例,该数据集有五个标签(label分为0~4),因此在创建模型时需要指定num_labels=5,标签就是模型输出内容一共有5种情况。
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased",
num_labels=5)
接着,你需要创建一个TrainingArguments类的实例,调整所有超参数以及激活不同训练选项。
from transformers import TrainingArguments
training_args = TrainingArguments(output_dir="test_trainer",
eval_strategy="epoch")
output_dir指定了保存训练过程中的检查点(checkpoints) 位置。如果现在微调(fine-tuning)模型的过程中想要监控评估指标(evaluation metrics),可以指定eval_strategy参数,这样做可以在每个训练周期(epoch)结束时报告评估指标。
保存检查点允许训练过程中的任何时刻恢复训练,或者在训练完成后进一步分析模型的性能。
第四步,设置评估函数
在训练模型的过程中,可以手动指定一个评估函数来衡量模型在训练过程中的表现,Evaluate库中提供了模型评估函数,例如精准率(accuracy)函数。
import numpy as np
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
这里的“logits”是指模型输出的未经处理的数值,所有的🤗 Transformers模型返回的都是logits,而不是直接的预测结果。在计算预测准确率之前,通过np.argmax先将模型的原始输出logits转换为具体的预测结果。
第五步,开始训练
创建一个Trainer对象,传入模型、训练参数、训练数据集、测试数据集和评估函数。通过调用Trainer对象的train()方法开始微调模型。
# 定义训练参数
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
# 开始微调
trainer.train()
总结
Transformers库提供了模型推理、微调能力,大大简化了使用模型的复杂度和难度。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









