



最近看大模型方向的秋招面经,发现一个很有意思的现象:面试官们对 PPO、DPO、GRPO、DAPO 简直是“爱不释手”,几乎成了大模型岗的必考题。
我去知乎或者翻博客想搞懂这几个“O”的演进关系时,往往一头扎进复杂的数学公式里,看得头皮发麻。
为什么我们先有了 PPO,又去卷 DPO,现在怎么又冒出来个 GRPO 和 DAPO?它们到底在解决什么问题?
今天我们就来扒一扒大模型偏好对齐(Alignment)算法的演进内幕。不讲复杂的公式推导,我们只聊核心逻辑:它们到底在解决什么痛点,又引入了什么新坑?
一、PPO:早期的神,也是永远的痛
提到 RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习),我们得先搞清楚它到底解决了什么问题。
传统的 SFT(监督微调)教会了模型“如何回答”,但没教会它“如何答得好”。
什么是“好”?比如更安全、更幽默、更符合逻辑、拒绝有害问题。这个“好”的标准是模糊且复杂的,很难用 SFT 的数据来定义。
RLHF 的天才之处在于它引入了“品味裁判”:
- 收集偏好:先让人类对模型的各种答案进行排序(比如,A 答案比 B 答案好)。
- 训练裁判:用这些排序数据训练一个奖励模型。这个 RM 就像一个“AI 裁判”,它学会了模拟人类的复杂品味和价值观。
- 强化学习:最后,让大模型(LLM)通过强化学习的方式,不断生成答案,并由这个“AI 裁判”来打分。LLM 的目标就是调整自己(优化策略),去专门生成那些能从“AI 裁判”那里拿高分的答案。
而 PPO(Proximal Policy Optimization,近端策略优化),就是实现这“最后一步”最经典、最正统的强化学习算法。ChatGPT 最初的惊艳效果,功勋章里有它的一半。
但如果你亲手训过 PPO,你大概率经历过显存爆炸和 Loss 横跳的绝望。
为什么?因为标准的 PPO 实在太“重”了。为了让 LLM 学会“像人一样说话”(用奖励信号指导生成),PPO 直接拉来了四个模型凑了一桌麻将:
- Policy Model(策略模型,Actor):干活的,负责生成回答(我们要训的就是它)。
- Value Model(价值模型,Critic):当裁判的,预估当前状态未来能拿多少分。
- Reference Model(参考模型):照镜子的,防止 Actor 练歪了,得时不时回头看看原始模型咋说的(KL 散度约束)。
- Reward Model(奖励模型):打分的,代替人类给最终生成的答案打分。
划重点:这四个模型在训练时都要塞进显存里。对于千亿参数的模型来说,这简直是工程噩梦。
PPO 的核心哲学是标准的强化学习:它极其强调探索。通过 Critic 模型的辅助,它不仅看最终结果,还试图评估每一步 Token 生成的“潜在价值”。
二、DPO:一场极简主义的“反叛”
就在大家被 PPO 折磨得死去活来时,DPO(Direct Preference Optimization,直接偏好优化)横空出世。
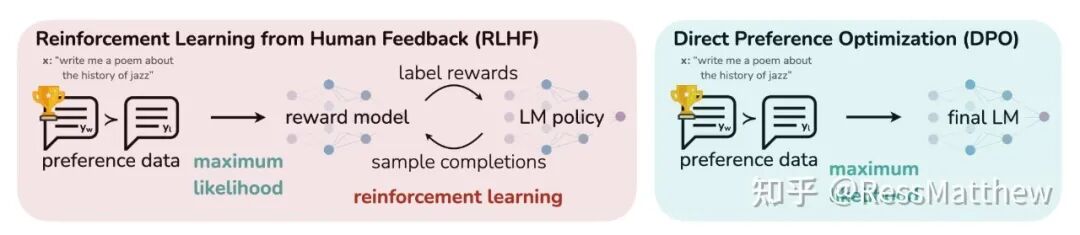
图 1. DPO:在避免使用强化学习的同时,优化语言模型以符合人类偏好
DPO 的思路极其性感:既然我们只想让模型偏好 A 答案胜过 B 答案,为什么非要训练一个复杂的 Reward 模型和 Critic 模型呢?
它直接跳过了中间商,用一个简单的分类损失函数,直接在偏好数据对上做微调(其中 P_θ 是策略模型,P_ref 是参考模型):
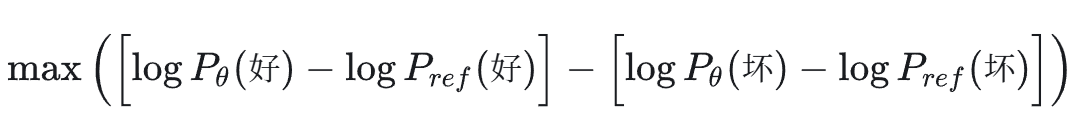
一夜之间,RLHF 变得像 SFT(监督微调)一样简单稳定,显存占用也大幅下降。
但好景不长,工业界很快发现 DPO 的局限性:它太依赖 SFT 基座模型的能力了。
因为它本质上是在做“对比学习”,而不是真正的“强化探索”。如果基座模型从来没生成过某个高分答案,DPO 很难凭空“悟”出来。
三、GRPO:DeepSeek 的实用主义回归
这时候,DeepSeek 在其系列模型中采用的 GRPO(Group Relative Policy Optimization,组相对策略优化)开始受到关注。
GRPO 的核心洞察是:PPO 的 Critic 模型太占资源了,能不能把它干掉?
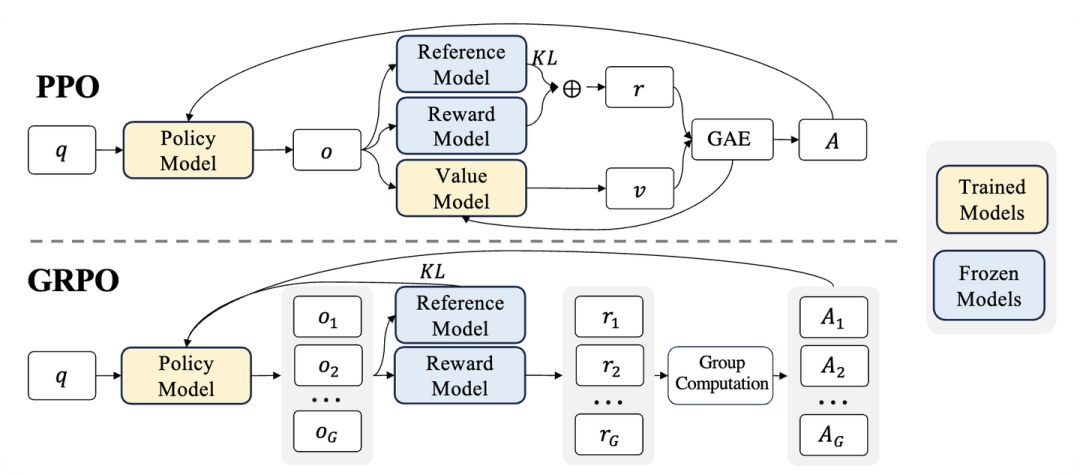
图 2. PPO vs. GRPO: GRPO 不再使用价值模型,而是通过组得分来估计基线,从而显著减少训练所需的计算资源
答案是可以。GRPO 采用了一种“组团打分”的策略:
- 组团生成:对于同一个问题,让模型一口气生成一组(比如 8 个)不同的答案。
- 组内竞争:用 Reward 模型给这 8 个答案分别打分。
- 相对优势:算出这组答案的平均分。比平均分高的,奖励;比平均分低的,惩罚。
妙在哪? 它用“组平均值”代替了 PPO 中那个昂贵的 Critic 模型来充当 Baseline。
这就好比考试,我不要求你达到一个绝对的 90 分(Critic 的预估值),我只要求你比你们班这次考试的平均分高就行。
GRPO 成功地在 PPO 的“探索能力”和 DPO 的“训练效率”之间找到了一个极其漂亮的平衡点:它保留了 RL 的探索精神,却甩掉了 Critic 这个沉重的包袱。
四、DAPO:更精细的手术刀
当然,技术永远在迭代。GRPO 也有自己的问题:
- 无效内卷:如果一组 8 个答案都非常完美,或者都烂得一塌糊涂,它们相对于“组平均分”的差异就很小。这时候模型学不到什么有效信息,浪费了算力。
- 保守陷阱:为了防止模型训崩,PPO 和 GRPO 都会用 Clipping(裁剪)机制,限制模型每次更新的幅度。但这有时候会“误伤”那些模型灵光一现生成的绝妙答案。
于是,DAPO(Decoupled Clip and Dynamic sAmpling Policy Optimization,解耦裁剪与动态采样策略优化)登场了,它对 GRPO 进行了两处关键的“手术”:
手术一:动态采样(拒绝无效内卷)
DAPO 加了一个过滤器,太简单(全对)和太难(全错)的数据组直接跳过不练,只死磕那些模型“似懂非懂”的数据。
手术二:解耦裁剪(允许灵光一现)
传统的 Clipping 是双向限制的。DAPO 说:如果模型这次更新是往“好”的方向大步迈进,我们为什么要拦着?
它解耦了裁剪范围,允许更高的上限(Upside),鼓励模型更大胆地探索高分区域。
更有意思的是,DAPO 在实践中甚至开始尝试去掉 KL 散度约束。
这是一个非常大胆的举动,意味着它允许模型更大幅度地偏离原始基座,去探索全新的解空间——这对于追求极高推理能力(如数学证明、复杂代码)的场景可能至关重要。
五、总结
如果把大模型比作一个学生:
- PPO 是请了 4 个私教(模型)全方位辅导,效果好但学费极其昂贵。
- DPO 是直接刷《五年高考三年模拟》,只看标准答案,效率高但缺乏举一反三的能力。
- GRPO 是搞“学习小组”,大家互相批改作业,比平均分好的受表扬,既省了老师又保持了竞争。
- DAPO 则是升级版的“精英学习小组”,只攻坚难题,并且鼓励尖子生“抢跑”。
光有比喻还不够,为了让大家看得更清楚(也方便面试时快速回忆),我把这四种算法的核心‘进化’和‘取舍’浓缩成了下面这张表:
PPO,DPO,GRPO,DAPO 核心对比:
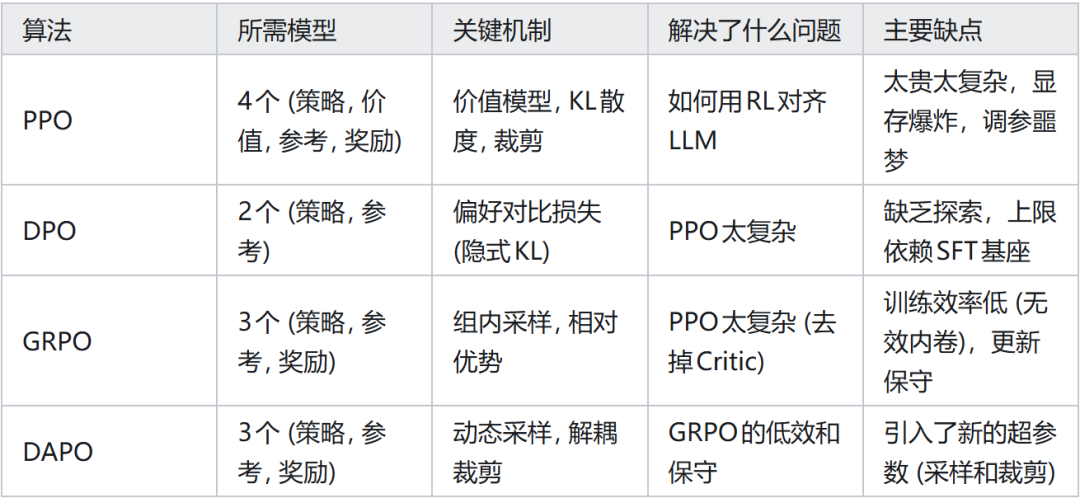
从目前的趋势看,回归强化学习(RL)本质、增强模型的自主探索能力,正在成为新的共识。
GRPO 及其后续变体,很可能在未来一段时间内取代 DPO,成为高性能大模型训练标配。
六、如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
0基础怎么入门AI大模型?
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习_,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

















 1291
1291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









