



DeepSeek-V3.2-Exp是实验性大模型,基于V3.1-Terminus构建并引入DeepSeek稀疏注意力(DSA)机制。该技术实现了细粒度稀疏注意力,将计算复杂度从O(L²)降至O(Lk),显著提升长文本处理效率,同时保持模型性能不变。模型已在多个平台开源,提供HuggingFace、SGLang和vLLM等多种部署方案,API价格下调超50%,降低了开发者使用门槛,适合长文本处理场景的高效应用。
【DeepSeek 论文精读】13. DeepSeek-V3.2-Exp 技术报告与部署实践
0. DeepSeek-V3.2-Exp 模型发布
DeepSeek 已于今日(2025年9月29日)正式发布了 DeepSeek-V3.2-Exp 模型。、
这是一个实验性(Experimental)的版本。作为迈向新一代架构的中间步骤,V3.2-Exp 在 V3.1-Terminus 的基础上引入了 DeepSeek Sparse Attention(一种稀疏注意力机制),针对长文本的训练和推理效率进行了探索性的优化和验证。目前,官方 App、网页端、小程序均已同步更新为 DeepSeek-V3.2-Exp,同时 API 大幅度降价。
0.1 技术特性
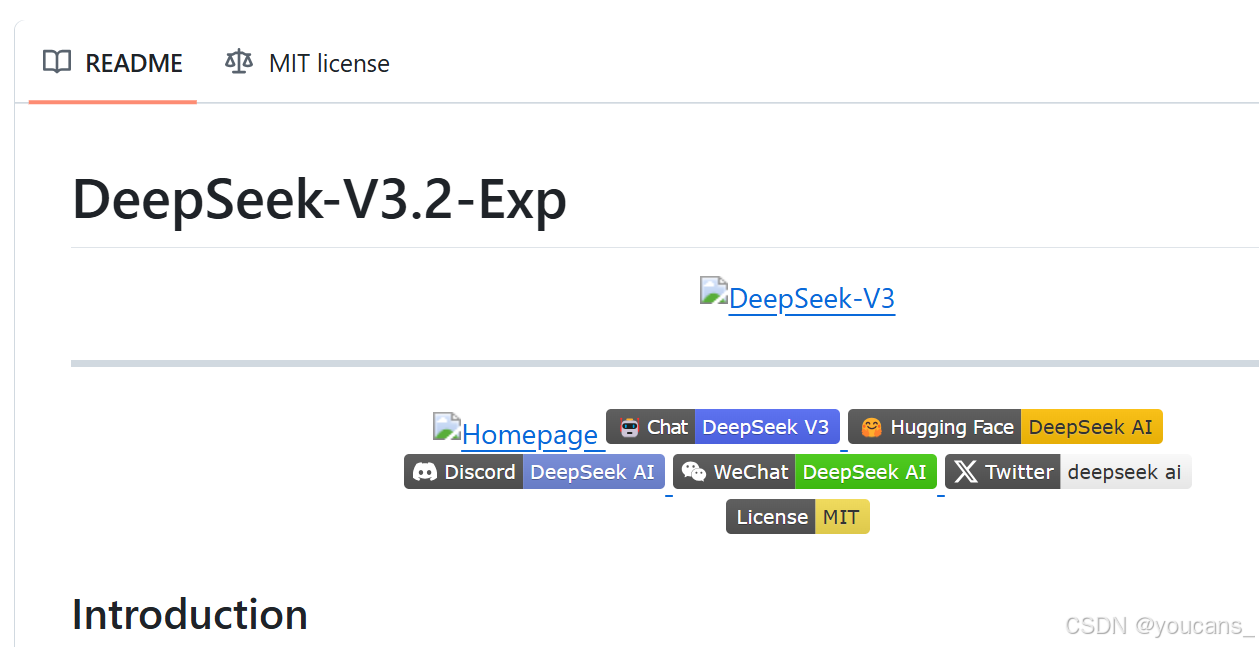
- 基础架构:基于V3.1-Terminus构建,保持671B参数规模
- 创新机制:首次实现细粒度稀疏注意力,突破传统Transformer架构限制
- 效率提升:在长文本处理场景中显著降低计算成本和内存使用
- 质量保证:输出质量与V3.1-Terminus几乎完全一致
0.2 核心技术:稀疏注意力机制 (DSA)
核心技术:稀疏注意力机制 (DSA)
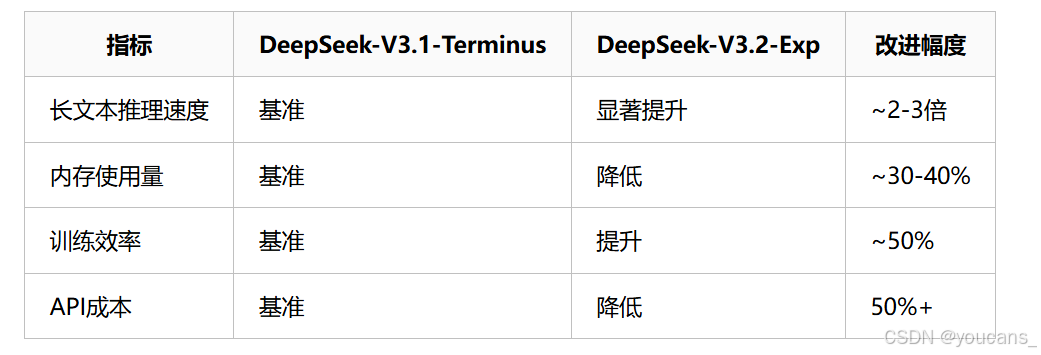
DeepSeek Sparse Attention(DSA)首次实现了细粒度稀疏注意力机制,这项技术旨在解决传统Transformer模型在处理长文本时计算复杂度高的问题。
- 工作原理:传统的注意力机制需要计算序列中每个token与所有其他token的关系,导致计算量随文本长度呈平方级增长。而DSA首次实现了细粒度的稀疏注意力,通过选择性计算注意力权重,有效突破了这一限制。
- 带来的好处:这意味着在处理长上下文(如128K长度)时,模型的推理速度更快,内存使用更少,从而显著降低了计算成本。在几乎不影响模型输出效果的前提下,实现了长文本训练和推理效率的大幅提升。
- 性能保持:为了严谨评估DSA的影响,DeepSeek将V3.2-Exp的训练设置与V3.1-Terminus进行了严格对齐。结果表明,新模型在MMLU-Pro、AIME、Codeforces等多个公开基准测试集上,性能与前代模型基本相当,确保了效率提升不以牺牲性能为代价。
- 成本大降:此次发布伴随着一个对开发者极其友好的举措——API价格大幅下调超过50%。这使得调用DeepSeek官方API的成本更低,极大地降低了开发者和企业的使用门槛。
0.3 开源模型
官方应用:你可以直接通过官方App、网页端或小程序体验DeepSeek-V3.2-Exp模型。
开源模型:模型已在Hugging Face和ModelScope(魔搭)等平台全面开源,方便开发者进行深入研究、部署和二次开发。
- HuggingFace:
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp - ModelScope:
https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Exp - DeepSeek-V3.2-Exp 技术报告:
https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf
0.4 论文简介
- 论文标题:DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention(DeepSeek-V3.2-Exp:通过DeepSeek稀疏注意力机制提升长上下文处理效率)
- 发布时间:2025 年 9 月
- 下载地址:Github: Deepseek-V3.2

0.5 摘要
我们推出DeepSeek-V3.2-Exp,这是一款实验性稀疏注意力模型,它通过持续训练为DeepSeek-V3.1-Terminus装备了DeepSeek稀疏注意力(DSA)。
借助DSA这一由闪电索引器驱动的细粒度稀疏注意力机制,DeepSeek-V3.2-Exp在训练和推理效率上都取得了显著提升,尤其是在长上下文场景中。模型检查点可在以下网址获取:
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp。
1. 架构
与DeepSeek-V3.1-Terminus(即DeepSeek-V3.1的最终版本)相比,DeepSeek-V3.2-Exp在架构上的唯一改动是通过持续训练引入了DeepSeek稀疏注意力(DSA)。
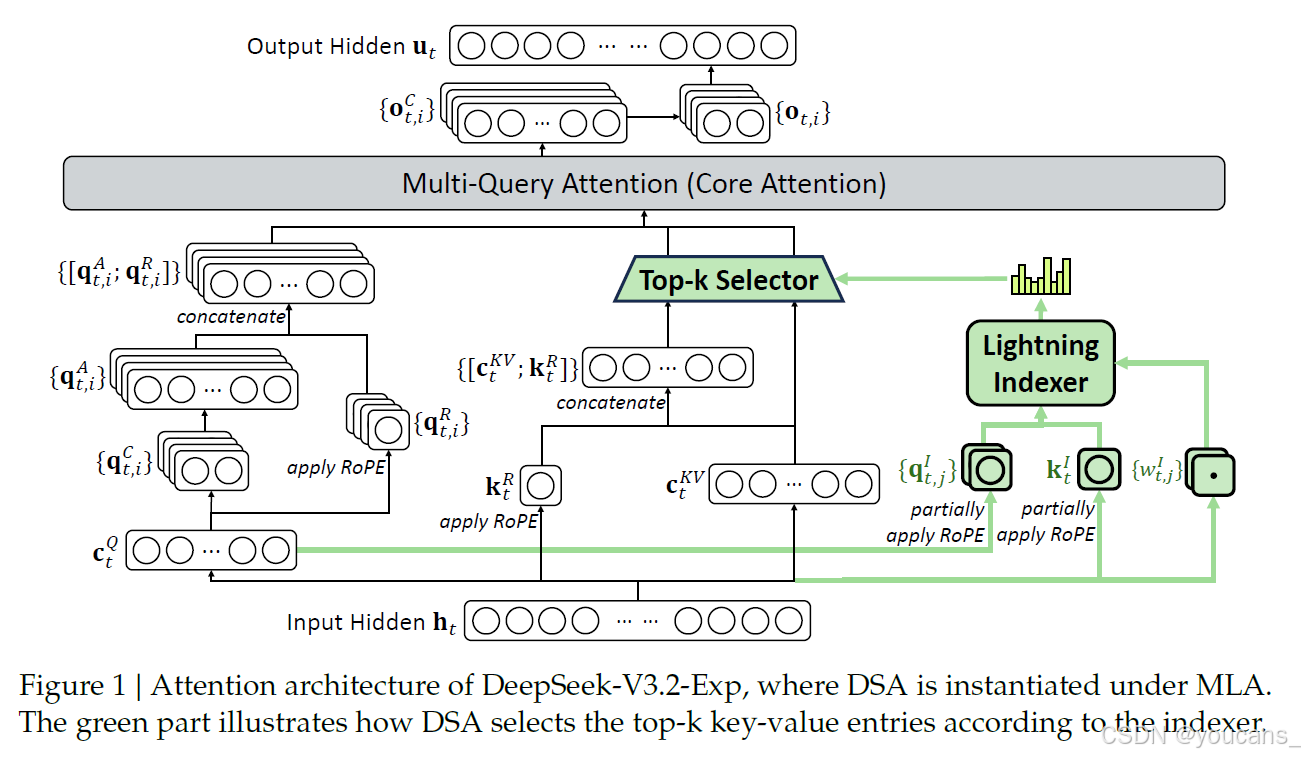
图1 | DeepSeek-V3.2-Exp的注意力架构示意图——其中DSA是在MLA框架下实例化实现的。绿色部分展示了DSA如何根据索引器选择top-k键值条目的过程。
DSA原型
DSA的原型主要包含两个组件:闪电索引器和细粒度token选择机制。
闪电索引器计算查询token h𝑡 ∈ R𝑑与前驱token h𝑠 ∈ R𝑑之间的索引得分𝐼𝑡,𝑠,以确定哪些token将被查询token选中:
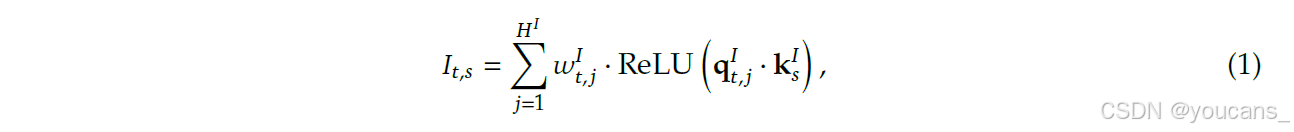
其中 HI 表示索引器头的数量;qI t, j ∈ RdI 和 wI t, j ∈ R 由查询词元 ht 推导得出;kI s ∈ RdI 则由前驱词元 hs 推导得出。出于计算吞吐量的考量,我们选择 ReLU 作为激活函数。鉴于闪电索引器的头数较少且可用 FP8 实现,其计算效率十分显著。
根据每个查询词元 ht 的索引分数 {It,s},我们的细粒度词元选择机制仅检索与前 k 个索引分数对应的键值条目 {cs}。随后,通过应用查询词元 ht 与稀疏选择的键值条目 {cs} 之间的注意力机制计算注意力输出 ut:
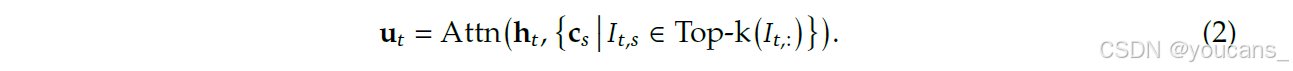
在多元线性注意力(MLA)框架下实例化DSA。
为了考虑从DeepSeek-V3.1-Terminus进行持续训练的需求,我们基于MLA(DeepSeek-AI,2024)为DeepSeek-V3.2-Exp实例化DSA。在内核层面,每个键值条目必须在多个查询间共享以保证计算效率(Yuan等,2025)。
因此,我们基于MLA的多查询注意力(MQA)模式(Shazeer,2019)实现DSA,其中每个潜在向量(MLA的键值条目)将在查询词元的所有查询头之间共享。基于MLA的DSA架构如图1所示。我们还提供了DeepSeek-V3.2-Exp的开源实现以明确说明具体细节。
2. 训练
从上下文长度已扩展至128K的DeepSeek-V3.1-Terminus基础检查点出发,我们通过持续预训练和后训练来构建DeepSeek-V3.2-Exp。
2.1 持续预训练
DeepSeek-V3.2-Exp的持续预训练包含两个训练阶段。在这两个阶段中,训练数据的分布均与DeepSeek-V3.1-Terminus的128K长上下文扩展数据完全对齐。
密集预热阶段
我们首先采用一个简短的预热阶段来初始化Lightning索引器。在此阶段,我们保持稠密注意力(dense attention),并冻结除Lightning索引器之外的所有模型参数。为了使索引器输出与主要注意力分布对齐,对于第𝑡个查询标记,我们首先通过对所有注意力头的分数求和来聚合主要注意力分数。
该求和结果随后沿序列维度进行L1归一化,生成目标分布𝑝𝑡,: ∈ R𝑡。基于𝑝𝑡,:,我们设置KL散度损失作为索引器的训练目标:
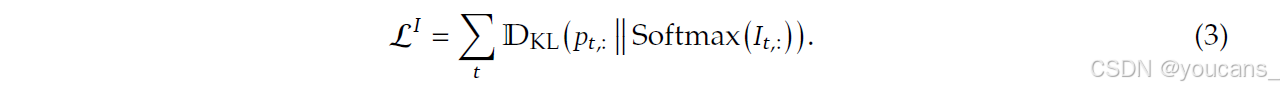
我们采用10^-3的学习率进行索引器预热训练,仅训练1000步。每步处理16条128K标记的序列,总计训练21亿标记(2.1B tokens)。
稀疏训练阶段
完成索引器预热后,我们引入细粒度标记选择机制,并优化所有模型参数以使模型适应DSA的稀疏模式。在本阶段,我们持续保持索引器输出与主要注意力分布的对齐,但仅考虑被选标记集合S_t = {s | I_t,s ∈ Top-k(I_t,:)}。

需要特别说明的是,我们将索引器的输入从计算图中分离以实现独立优化。索引器的训练信号仅来自L_I,而主模型的优化则仅基于语言建模损失。在此稀疏训练阶段,我们采用7.3×10^-6的学习率,并为每个查询标记选定2048个键值标记。我们对主模型和索引器进行15000步训练,每步处理480条128K标记的序列,总计训练9437亿标记(943.7B tokens)。
2.2 后训练阶段
在完成持续预训练后,我们通过后训练流程生成最终的DeepSeek-V3.2-Exp模型。该阶段沿用与稀疏持续预训练相同的动态稀疏注意力(DSA)机制。为严谨评估DSA的引入效果,DeepSeek-V3.2-Exp采用与DeepSeek-V3.1-Terminus完全一致的后训练流程、算法和数据配置,具体如下:
专家蒸馏
针对每类任务,我们首先基于统一的DeepSeek-V3.2基础检查点微调出领域专用模型(specialist)。除文本生成和通用问答外,框架涵盖五大专业领域:数学、竞赛编程、通用逻辑推理、智能体编码(agentic coding)及智能体搜索(agentic search)。所有专家模型均通过大规模强化学习(RL)进行训练,并分别构建长思维链推理(thinking mode)与直接响应生成(non-thinking mode)的专用训练数据。实验表明,基于蒸馏数据训练的模型性能与领域专家模型差距极小,后续RL训练可完全消除这一差异。
混合强化学习
DeepSeek-V3.2-Exp采用组相对策略优化(GRPO)算法(DeepSeek-AI, 2025; Shao et al., 2024)。与以往多阶段强化学习的DeepSeek模型不同,本次将推理、智能体任务与人类对齐训练合并为单一RL阶段。该方法在保证多领域性能平衡的同时,有效规避了多阶段训练常见的灾难性遗忘问题。
具体奖励机制设计如下:
- 推理与智能体任务:基于规则的结果奖励、长度惩罚及语言一致性奖励
- 通用任务:采用生成式奖励模型,每个提示(prompt)配有专属评估准则
奖励设计重点平衡两种权衡关系:
- 响应长度与准确性
- 语言一致性(language consistency)与准确性
3. 评估
- 模型能力
我们在多类基准测试中对DeepSeek-V3.2-Exp进行了评估,重点关注多样化能力,并与DeepSeek-V3.1-Terminus进行了对比(见表1)。结果显示,尽管DeepSeek-V3.2-Exp在长序列任务上的计算效率显著提升,但在短上下文和长上下文任务中,其性能均未出现明显下降。
此外,我们还比较了两个模型的强化学习训练曲线(见图2)。在整个训练过程中,DeepSeek-V3.2-Exp和DeepSeek-V3.1-Terminus在BrowseComp和SWE Verified任务上的表现均稳步提升,且二者的训练曲线高度吻合,反映出DSA(动态稀疏注意力)优异的训练稳定性。
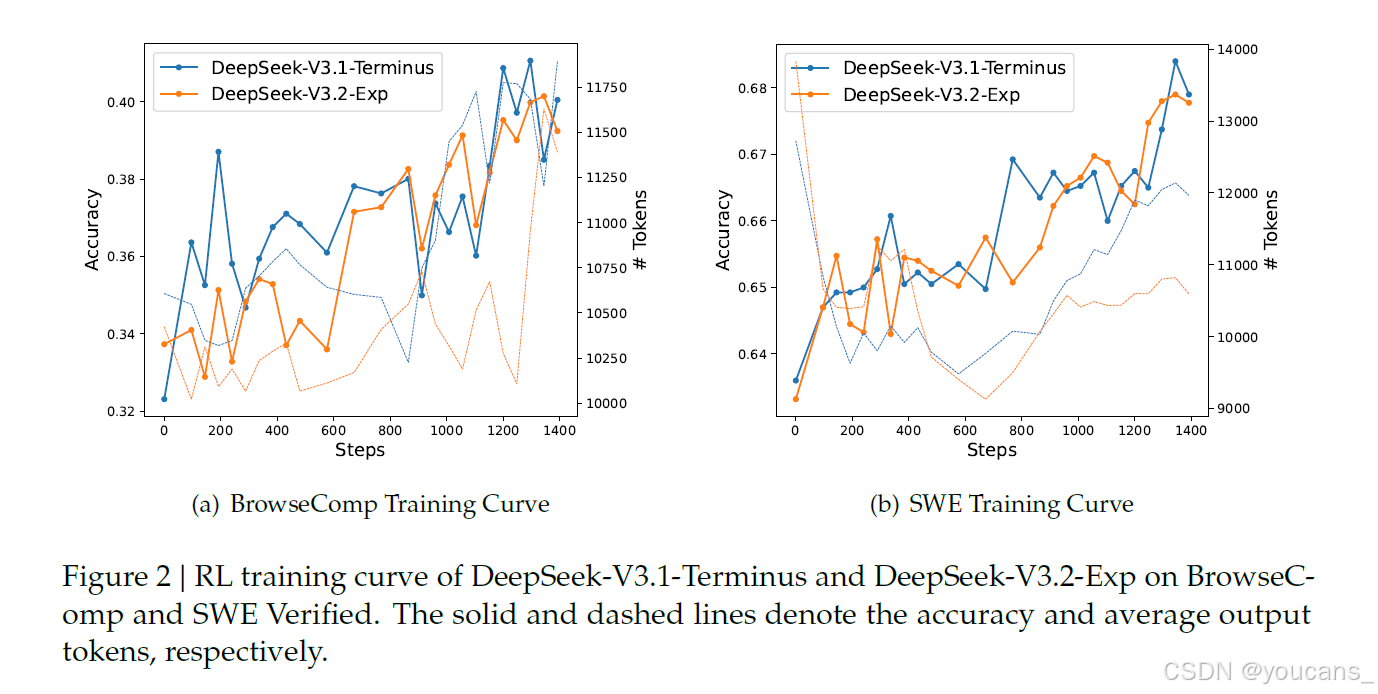
图2 | DeepSeek-V3.1-Terminus和DeepSeek-V3.2-Exp在BrowseComp及SWE Verified任务上的强化学习训练曲线。实线和虚线分别表示准确率和平均输出标记数量。
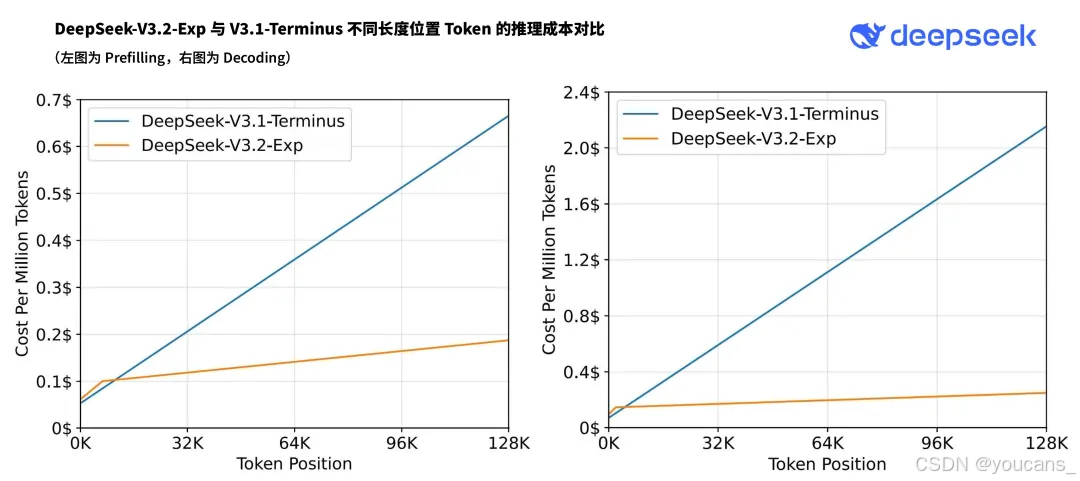
- 推理成本
DSA将主模型的核心注意力复杂度从O(L²) 降至O(Lk),其中k(≪ L)为所选标记的数量。虽然闪电索引器(lightning indexer)的复杂度仍为O(L²),但其计算量远低于DeepSeek-V3.1-Terminus中的MLA(多层注意力)。结合我们的优化实现,DSA在长上下文场景下实现了显著的端到端加速。图3展示了DeepSeek-V3.1-Terminus和DeepSeek-V3.2-Exp的标记成本随序列位置的变化情况。这些成本基于在H800 GPU(租用价格为每小时2美元)上实际部署服务的基准测试估算得出。需要注意的是,对于短序列预填充任务,我们专门采用了掩码多头注意力(masked MHA)模式来模拟DSA,从而在短上下文条件下实现更高效率。
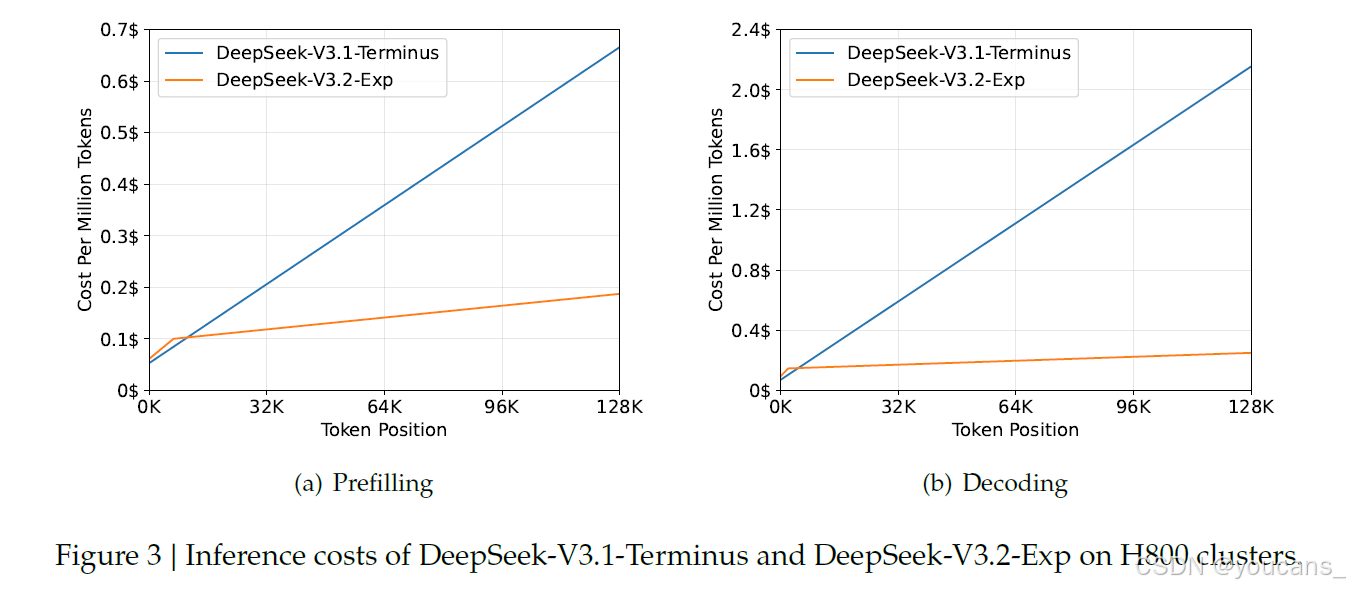
图3 | DeepSeek-V3.1-Terminus与DeepSeek-V3.2-Exp在H800计算集群上的推理成本分析。
- 实际场景验证
虽然内部评估显示DeepSeek-V3.2-Exp的结果令人鼓舞,但我们仍在积极寻求在实际场景中开展更大规模的测试,以揭示稀疏注意力架构潜在的限制。
4. DeepSeek-V3.2-Exp 部署方案与技术实现
4.1 本地部署方案
- HuggingFace原生部署
我们在 inference 文件夹中提供了一个更新的推理演示代码,以帮助社区快速开始使用我们的模型并了解其架构细节。
首先将 Hugging Face 模型权重转换为我们的推理演示所需的格式。设置 MP 以匹配您的可用 GPU 数量:
# 模型权重转换cd inference
exportEXPERTS=256
python convert.py --hf-ckpt-path ${HF_CKPT_PATH}\
--save-path ${SAVE_PATH}\
--n-experts ${EXPERTS}\
--model-parallel ${MP}
启动交互式聊天界面并开始探索 DeepSeek 的功能:
# 启动交互式界面exportCONFIG=config_671B_v3.2.json
torchrun --nproc-per-node ${MP} generate.py \
--ckpt-path ${SAVE_PATH}\
--config ${CONFIG}\
--interactive
- SGLang高性能部署
docker 安装
# H200
docker pull lmsysorg/sglang:dsv32
# MI350
docker pull lmsysorg/sglang:dsv32-rocm
# NPUs
docker pull lmsysorg/sglang:dsv32-a2
docker pull lmsysorg/sglang:dsv32-a3
命令行安装:
python -m sglang.launch_server \
--model deepseek-ai/DeepSeek-V3.2-Exp \
--tp 8 --dp 8 --page-size 64
- vLLM集成
vLLM提供day-0支持,详细配置可参考官方recipes。
wget https://wheels.vllm.ai/dsv32/vllm-0.10.2rc3.dev371%2Bgb215ed849.cu129-cp38-abi3-linux_x86_64.whl
git clone https://github.com/heheda12345/vllm.git
cd vllm
git checkout dsv32
VLLM_USE_PRECOMPILED=1VLLM_PRECOMPILED_WHEEL_LOCATION=$(pwd)/vllm-0.10.2rc3.dev371+gb215ed849.cu129-cp38-abi3-linux_x86_64.whl uv pip install -vvv -e .
pip install https://wheels.vllm.ai/dsv32/deep_gemm-2.1.0%2B594953a-cp312-cp312-linux_x86_64.whl
4.2 对比测试
作为一个实验性的版本,DeepSeek-V3.2-Exp 虽然已经在公开评测集上得到了有效性验证,但仍然需要在用户的真实使用场景中进行范围更广、规模更大的测试,以排除在某些场景下效果欠佳的可能。
为方便用户进行对比测试,我们为 DeepSeek-V3.1-Terminus 临时保留了额外的 API 访问接口。用户只需修改base_url=“https://api.deepseek.com/v3.1_terminus_expires_on_20251015” 即可访问 V3.1-Terminus,调用价格与 V3.2-Exp 相同。该接口将保留到北京时间 2025 年 10 月 15 日 23:59,更详细的使用方法请参考官方文档 https://api-docs.deepseek.com/zh-cn/guides/comparison_testing。
通过修改 base_url,您可以控制访问的模型版本:
- 当您使用原来的方式访问 API 时,访问到的是 DeepSeek-V3.2-Exp 模型
- 当您设置 base_url=“https://api.deepseek.com/v3.1_terminus_expires_on_20251015” 时,访问到的是 DeepSeek-V3.1-Terminus 模型
base_url 设置与具体模型的对应关系见下表:
| API 类型 | base_url 设置 | 模型版本 |
|---|---|---|
| OpenAI | https://api.deepseek.com | DeepSeek-V3.2-Exp |
| Anthropic | https://api.deepseek.com/anthropic | DeepSeek-V3.2-Exp |
| OpenAI | https://api.deepseek.com/v3.1_terminus_expires_on_20251015 | DeepSeek-V3.1-Terminus |
| Anthropic | https://api.deepseek.com/v3.1_terminus_expires_on_20251015/anthropic | DeepSeek-V3.1-Terminus |
使用示例
使用 OpenAI 兼容 API 访问 V3.1-Terminus
# Please install OpenAI SDK first: `pip3 install openai`import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get('DEEPSEEK_API_KEY'),
base_url="https://api.deepseek.com/v3.1_terminus_expires_on_20251015")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"Hello"},],
stream=False)print(f"Model is: {response.model}")print(f"Output is: {response.choices[0].message.content}")
样例输出
Model is: deepseek-v3.1-terminus
Output is: Hello! How can I help you today?
如样例输出所示,您可以通过 API 返回中的 model 字段,验证所调用的模型是否为 V3.1-Terminus。
引用
@misc{deepseekai2024deepseekv32,
title={DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention},
author={DeepSeek-AI},
year={2025},
}
引用
bash
@misc{deepseekai2024deepseekv32,
title={DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention},
author={DeepSeek-AI},
year={2025},
}
零基础如何高效学习大模型?
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

















 1186
1186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









