







什么是大模型?
你是不是脑子里浮现的是 OpenAI、ChatGPT、DeepSeek?还有各式各样能跳个舞、可以翻个跟头的机器人?再深入点的,还能说出训练与推理。
有没有一种感觉:就是身边的信息都在声嘶力竭的鼓吹大模型正在改变世界?恍惚自己再不学习下大模型,就马上会被世界所抛弃的感觉?
如果你有这种感觉,那就对了。因为我曾经也有这个感觉,所以在某个时间、某个瞬间,我就下定决心要躬身入局,弄清楚它的概念与原理。
所以就有了这篇文章,弄懂了它们,就已经超过了很多人;如果还明白了其原理,就达到了“砖家”级别。即使是跟别人吹牛时,也不致于内心发虚。
专业词汇阅读与理解时,肯定没有娱乐新闻有趣,希望我们一起能沉下心来,完整阅读与理解,时间不会辜负每个努力学习的人,下面我们一起进步。
深度学习
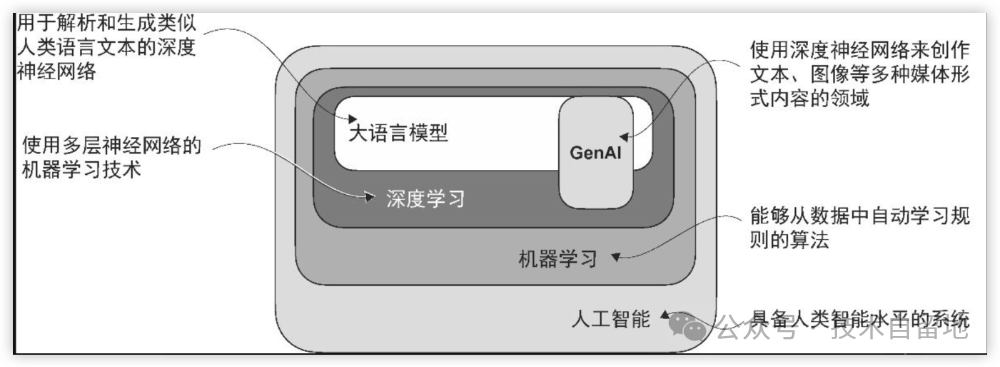
【人工智能】的英文单词是 artificial intelligence,即我们常说的 AI。跟它相关的还有两个专业词汇,一个是深度学习,一个是机器学习。【深度学习】英文单词是 deep learning;【机器学习】的英文单词是 machine learning。
深度学习是机器学习和人工智能领域的一个重要分支,主要聚焦于神经网络的研究。
深度学习的发展使得大语言模型能够利用海量的文本数据进行训练,从而相比于以往的方法能够捕获更深层次的上下文信息和人类语言的细微之处。因此,大语言模型在文本翻译、情感分析、问答等各类自然语言处理任务中都有显著的性能提升。
大语言模型的成功,一方面得益于为其提供支撑的 Transformer 架构,另一方面得益于用于训练这些模型的海量数据。这使得它们能够捕捉到语言中的各类细微差别、上下文信息和模式规律,而这些都是手动编码难以实现的。
LLM
大语言模型(large language model,LLM,简称大模型)是一种用于理解、生成和响应类似人类语言文本的神经网络。
这类模型属于深度神经网络(deep neural network),通过大规模文本数据训练而成,其训练资料甚至可能涵盖了互联网上大部分公开的文本。大语言模型在理解、生成和解释人类语言方面拥有出色的能力。当我们谈论语言模型的“理解”能力时,实际上是指它们能够处理和生成看似连贯且符合语境的文本,而这并不意味着它们真的拥有像人类一样的意识或理解能力。
“大语言模型”这一名称中的“大”字,既体现了模型训练时所依赖的庞大数据集,也反映了模型本身庞大的参数规模。这类模型通常拥有数百亿甚至数千亿个参数(parameter)。
这些参数是神经网络中的可调整权重,在训练过程中不断被优化,以预测文本序列中的下一个词。下一单词预测(next-word prediction)任务合理地利用了语言本身具有顺序这一特性来训练模型,使得模型能够理解文本中的上下文、结构和各种关系。
由于大语言模型能够生成文本,因此它们通常也被归类为生成式人工智能(generative artificial intelligence,简称 generative AI 或GenAI)。
如今大多数大语言模型是使用 PyTorch 深度学习库实现的,针对特定领域或任务量身打造的大语言模型在性能上往往优于 ChatGPT 等为多种应用场景而设计的通用大语言模型。这样的例子包括专用于金融领域的模型和专用于医学问答的大语言模型。使用定制的大语言模型具有多个优势,尤其是在数据隐私方面。例如,出于机密性考虑,公司可能不愿将敏感数据共享给像 OpenAI 这样的第三方大语言模型提供商。此外,如果开发较小的定制的大语言模型,那么就可以将其直接部署到客户设备(笔记本电脑和智能手机)上。
这也是大模型企业落地正在探索的方向。本地部署可以显著减少延迟并降低与服务器相关的成本。
【预训练】与【微调】
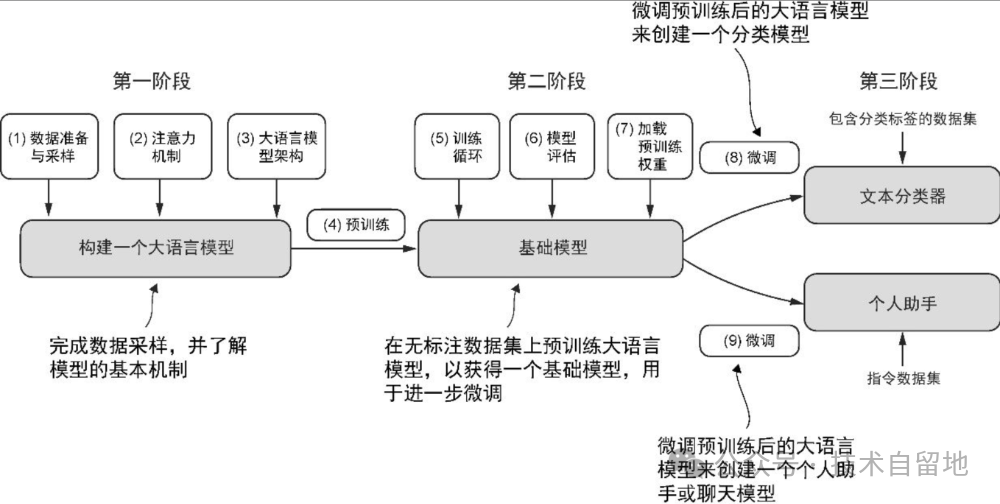
此外,定制的大语言模型使开发者拥有完全的自主权,能够根据需要控制模型的更新和修改。大语言模型的构建通常包括预训练(pre-training)和微调(fine-tuning)两个阶段。
预训练定义:预训练是利用大规模通用数据对模型进行初步训练,使其学习数据中的通用特征和规律,为后续特定任务学习奠定基础的过程。
“预训练”中的“预”表明它是模型训练的初始阶段,此时模型会在大规模、多样化的数据集上进行训练,以形成全面的语言理解能力。以预训练模型为基础,微调阶段会在规模较小的特定任务或领域数据集上对模型进行针对性训练,以进一步提升其特定能力。
请点击图片放大仔细理解其完整过程
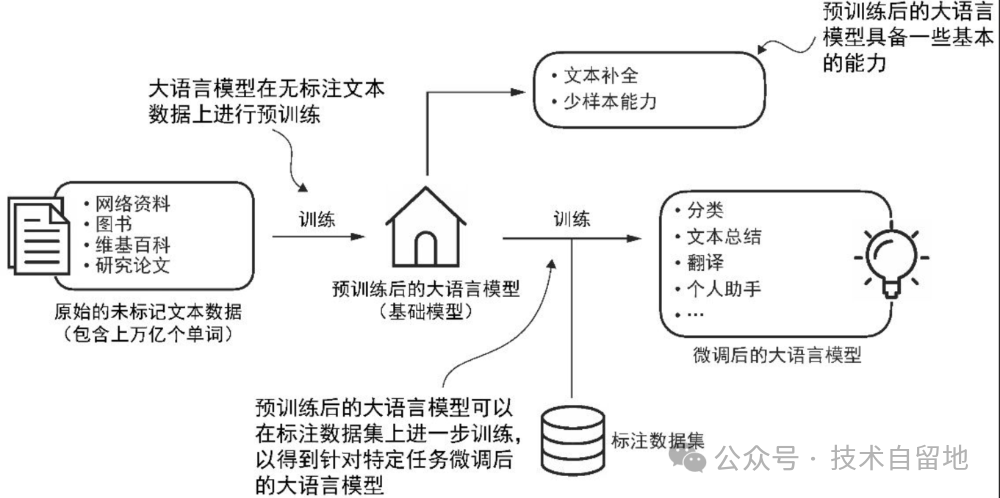
预训练是大语言模型的第一个训练阶段,预训练后的大语言模型通常称为基础模型(foundation model)。
一个典型例子是 ChatGPT的前身——GPT-3,这个模型能够完成文本补全任务,即根据用户的前半句话将句子补全。此外,它还展现了有限的少样本学习能力,这意味着它可以在没有大量训练数据的情况下,基于少量示例来学习并执行新任务。
【微调】的定义:微调是在预训练模型基础上,通过少量特定领域数据对模型参数进行针对性优化,使其更适配具体任务的过程。微调大语言模型最流行的两种方法是【指令微调】和【分类任务微调】。
在指令微调(instruction fine-tuning)中,标注数据集由“指令−答案”对(比如翻译任务中的“原文−正确翻译文本”)组成。在分类任务微调(classification fine-tuning)中,标注数据集由文本及其类别标签(比如已被标记为“垃圾邮件”或“非垃圾邮件”的电子邮件文本)组成。
Transformer 架构
该架构是在谷歌于 2017年发表的论文“Attention Is All You Need”中首次提出的。Transformer 最初是为机器翻译任务(比如将英文翻译成德语和法语)开发的。
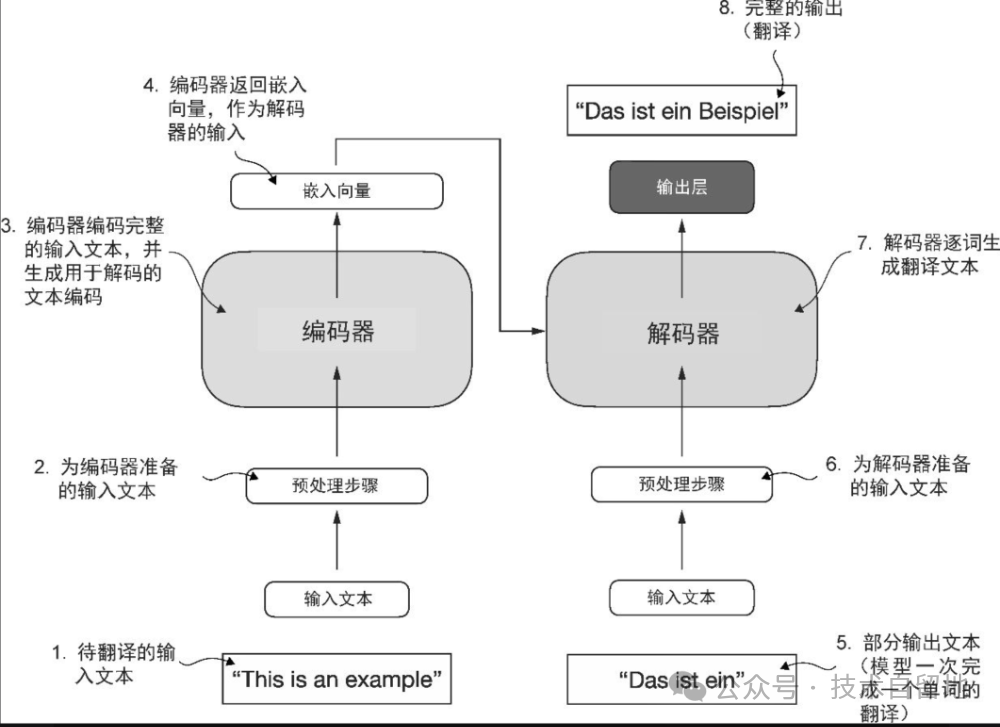
Transformer 架构由两个子模块构成:编码器和解码器。编码器(encoder)模块负责处理输入文本,将其编码为一系列数值表示或向量,以捕捉输入的上下文信息。然后,解码器(decoder)模块接收这些编码向量,并据此生成输出文本。以翻译任务为例,编码器将源语言的文本编码成向量,解码器则解码这些向量以生成目标语言的文本。编码器和解码器都是由多层组成,这些层通过自注意力机制连接。
Transformer 和大语言模型的一大关键组件是自注意力机制(self-attention mechanism),它允许模型衡量序列中不同单词或词元之间的相对重要性。这一机制使得模型能够捕捉到输入数据中长距离的依赖和上下文关系,从而提升其生成连贯且上下文相关的输出的能力。
并非所有的 Transformer 都是大语言模型,因为Transformer 也可用于计算机视觉领域。同样,并非所有的大语言模型都基于 Transformer 架构,因为还存在基于循环和卷积架构的大语言模型。
GPT 与 Bert
与原始 Transformer 架构相比,GPT的通用架构更为简洁。
请点击图片放大仔细理解其完整过程
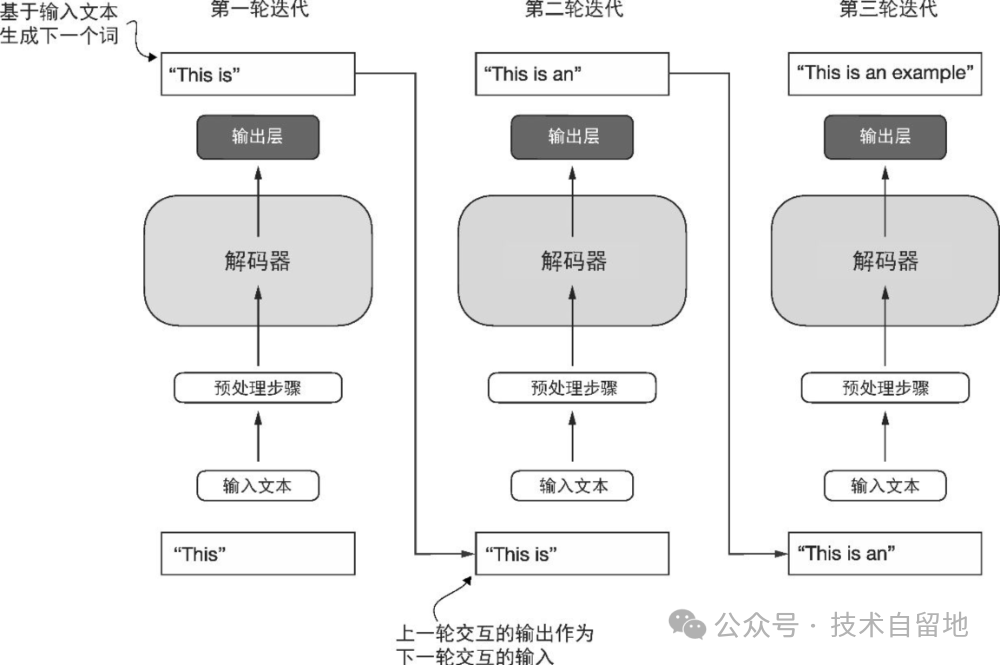
它只包含解码器部分,并不包含编码器。由于像 GPT 这样的解码器模型是通过逐词预测生成文本,因此它们被认为是一种自回归模型(autoregressive model)。自回归模型将之前的输出作为未来预测的输入。GPT-3 总共有 96 层 Transformer 和 1750 亿个参数虽然原始的 Transformer 模型(包含编码器模块和解码器模块)专门为语言翻译而设计,但 GPT 模型采用了更大且更简单的纯解码器架构,旨在预测下一个词,并且它们也能执行翻译任务。模型能够完成未经明确训练的任务的能力称为涌现(emergence)。这种能力并非模型在训练期间被明确教授所得,而是其广泛接触大量多语言数据和各种上下文的自然结果。
GPT 则侧重于原始 Transformer 架构的解码器部分,主要用于处理生成文本的任务,包括机器翻译、文本摘要、小说写作、代码编写等。零样本学习(zero-shot learning)是指在没有任何特定示例的情况下,泛化到从未见过的任务,而少样本学习(few-shot learning)是指从用户提供的少量示例中进行学习。
BERT 基于原始 Transformer的编码器模块构建,其训练方法与GPT 不同。GPT 主要用于生成任务,而 BERT 及其变体专注于掩码预测(masked word prediction),即预测给定句子中被掩码的词。
请点击图片放大仔细理解其完整过程
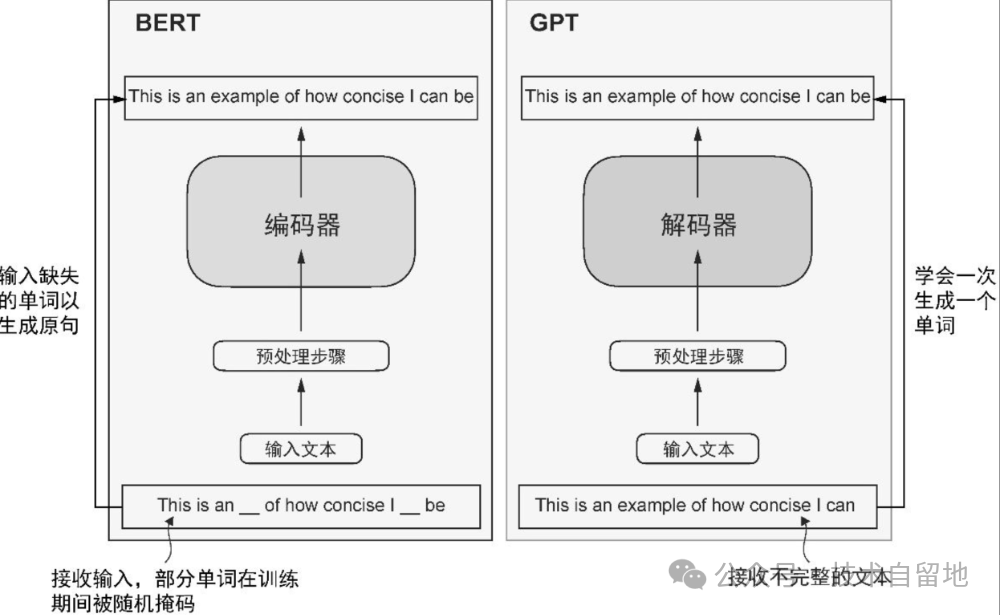
总而言之: GPT 是 Transformer的解码器部分,Bert 是 Transformer 的编码器部分。
Token
词元(token)是模型读取文本的基本单位。数据集中的词元数量大致等同于文本中的单词和标点符号的数量。
分词,即将文本转换为词元的过程。
预训练 GPT-3的云计算费用成本估计高达 460 万美元。该模型仅在 3000 亿个词元上进行了训练。好消息是,许多预训练的大语言模型是开源模型,可以作为通用工具,用于写作、摘要和编辑那些未包含在训练数据中的文本。
同时,这些大语言模型可以使用相对较小的数据集对特定任务进行微调,这不仅减少了模型所需的计算资源,还提升了它们在特定任务上的性能。下一单词预测任务采用的是自监督学习(self-supervised learning)模式,这是一种自我标记的方法。这意味着我们不需要专门为训练数据收集标签,而是可以利用数据本身的结构。也就是说,我们可以使用句子或文档中的下一个词作为模型的预测标签。由于该任务允许“动态”创建标签,因此我们可以利用大量的无标注文本数据集来训练大语言模型。
请点击图片放大仔细理解其完整过程
关键点总结
- \1. LLM(大语言模型):基于深度学习构建的超大规模语言模型,能理解、生成自然语言并执行复杂任务。
- \2. Transformer:一种基于自注意力机制的深度学习架构,是当前主流大模型(如 GPT、BERT)的核心框架。
- \3. GPT(生成式预训练 Transformer):基于 Transformer 的生成式预训练模型,擅长自然语言生成,如文本创作、对话交互。
- \4. Bert(双向编码器表示来自 Transformer):基于 Transformer 的双向预训练模型,侧重自然语言理解,常用于文本分类、命名实体识别等任务。
- \5. 预训练:在大规模无标注数据上训练模型,使其学习通用语言特征,为下游任务提供基础能力。
- \6. 微调(FineTuning):在预训练模型基础上,使用特定任务标注数据进一步训练,使其适配具体应用场景。
- \7. 深度学习:通过多层神经网络自动学习数据特征的机器学习领域,是当前大模型技术的基础
- \8. Token:自然语言处理中对文本的最小处理单元,如词语、子词或字符,用于将文本转换为模型可处理的数字序列。
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









