



一、引言
在当前人工智能的发展中,大型语言模型(LLMs)已成为NLP研究和应用的关键。Qwen2-7B模型作为领域的领先者,以其巨大的参数量和强大的功能获得了广泛注意,尤其是它在经过微调后能更好地完成特定任务。本文旨在详述如何运用LLaMA-Factory框架高效微调Qwen2-7B模型,以优化其在特定任务中的表现。
二、LLaMA-Factory简介
LLaMA-Factory是一个集多种微调技术于一身的高效框架,支持包括Qwen2-7B在内的多种大型语言模型。它通过集成如LoRA、QLoRA等先进的微调算法,以及提供丰富的实验监控工具,如LlamaBoard、TensorBoard等,为用户提供了一个便捷、高效的微调环境。此外,LLaMA-Factory还支持多模态训练方法和多硬件平台,包括GPU和Ascend NPU,进一步拓宽了其应用范围。

三、安装-modelscope
在国内,由于网络环境的特殊性,直接从国际知名的模型库如Hugging Face下载模型可能会遇到速度慢或连接不稳定的问题。为了解决这一问题,我们选择使用国内的ModelScope平台作为模型下载的渠道。ModelScope不仅提供了丰富的模型资源,还针对国内用户优化了下载速度。
修改模型库为modelscope

学术资源加速
source /etc/network_turbo
安装modelscope(用于下载modelscope的相关模型)
pip install modelscope
四、模型下载
在下载Qwen2-7B模型之前,我们首先需要设置modelscope的环境变量,确保模型能够被正确地缓存到指定的路径,避免因为默认路径导致的空间不足问题。接下来,通过编写一个简单的Python脚本,我们可以使用modelscope的API来下载所需的模型。
使用 modelscope 中的 snapshot_download 函数下载模型,第一个参数为模型名称,参数 cache_dir 为模型的下载路径。

运行python /root/autodl-tmp/d.py 执行下载;执行完成如下:
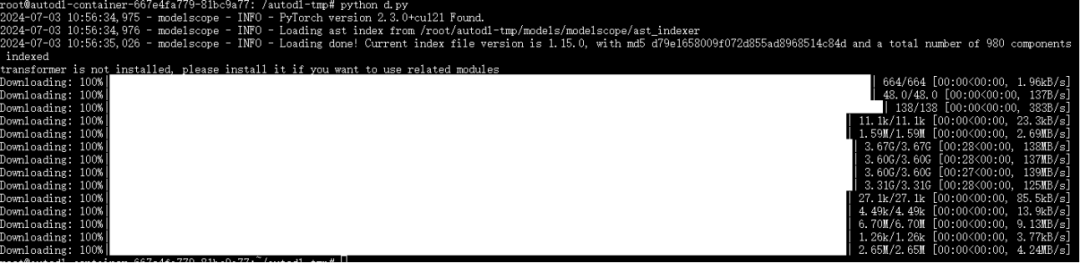
五、安装LLaMA-Factory
LLaMA-Factory的安装过程相对简单,通过Git克隆仓库后,使用pip安装即可。这一步骤是整个微调流程的基础,为后续的操作提供了必要的工具和库。

六、启动****LLaMA-Factory
在LLaMA-Factory安装完成后,我们可以通过简单的命令启动其Web UI界面。这一界面提供了一个用户友好的操作环境,使得微调过程更加直观和便捷。
修改gradio默认端口
export GRADIO_SERVER_PORT=6006
启动LLaMA-Factory
llamafactory-cli webui
启动如下:

七、LLaMA-Factory操作实践
1、访问UI界面
http://localhost:6006/
通过访问Web UI,用户可以进行模型的配置、训练参数的设置以及微调过程的监控。
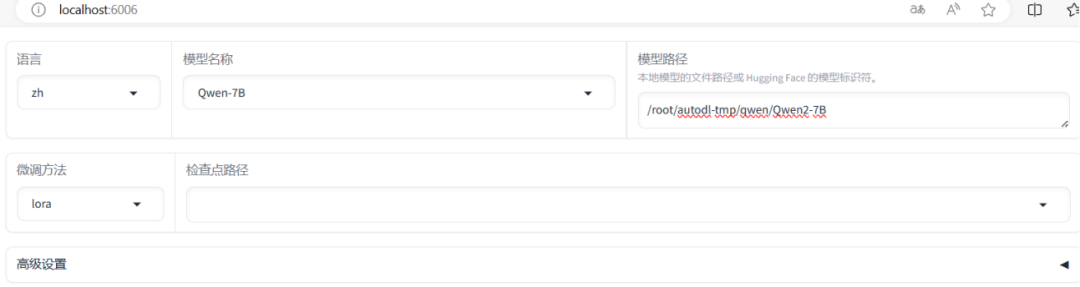
2、配置模型本地路径
在UI界面中,用户可以根据自己的需求选择模型来源,无论是直接使用Hugging Face模型库中的资源,还是加载本地下载的模型。
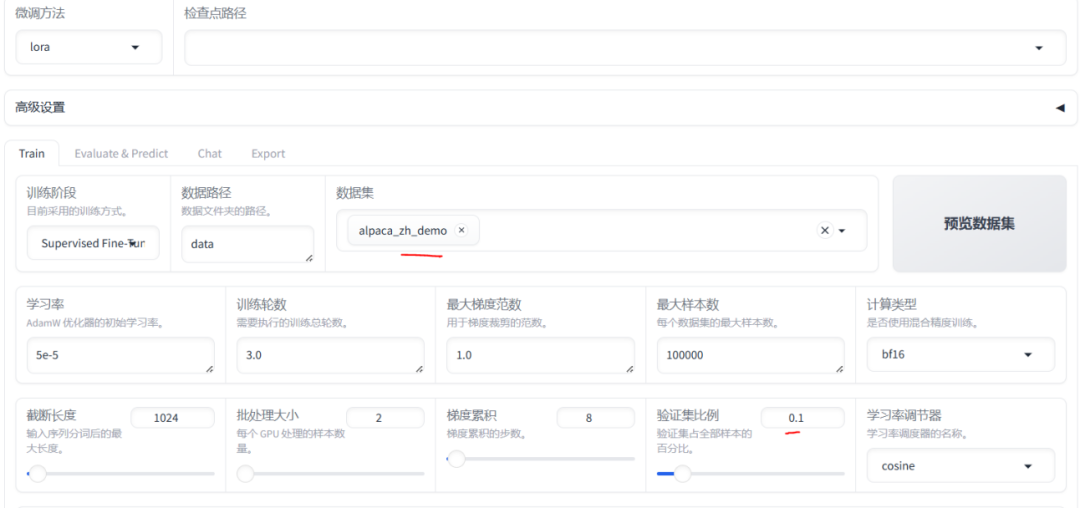
3、微调相关配置
微调配置是整个流程中至关重要的一步。用户需要根据具体的任务需求,设置训练阶段、数据集、学习率、批次大小等关键参数。
4、预览训练参数
在开始训练之前,用户可以预览所有的训练参数,确保配置无误。
点击“预览命令”按钮,查看训练的参数配置,可以进行手工修改调整


5、开始训练
一旦确认配置无误,用户可以启动训练过程。LLaMA-Factory将根据用户的配置进行模型的微调。
点击“开始”按钮,开始训练
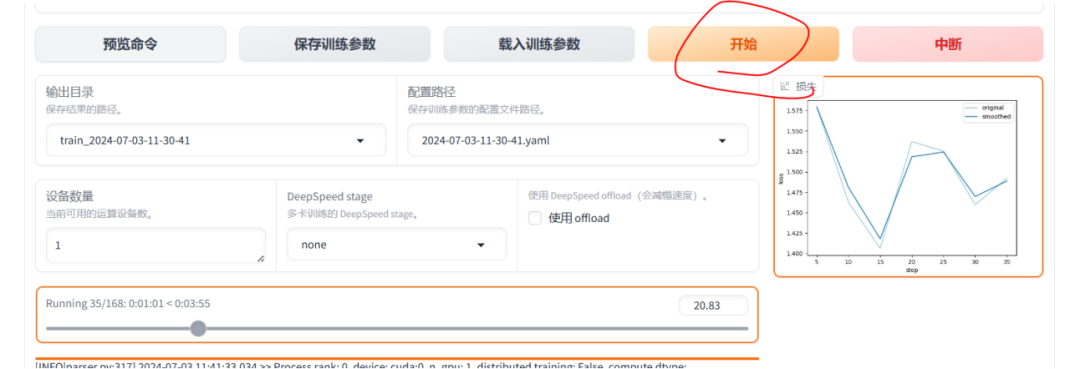
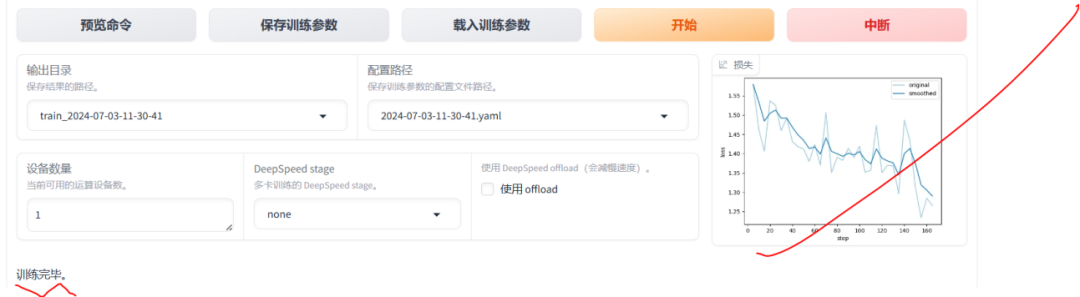
训练完成结果如下:
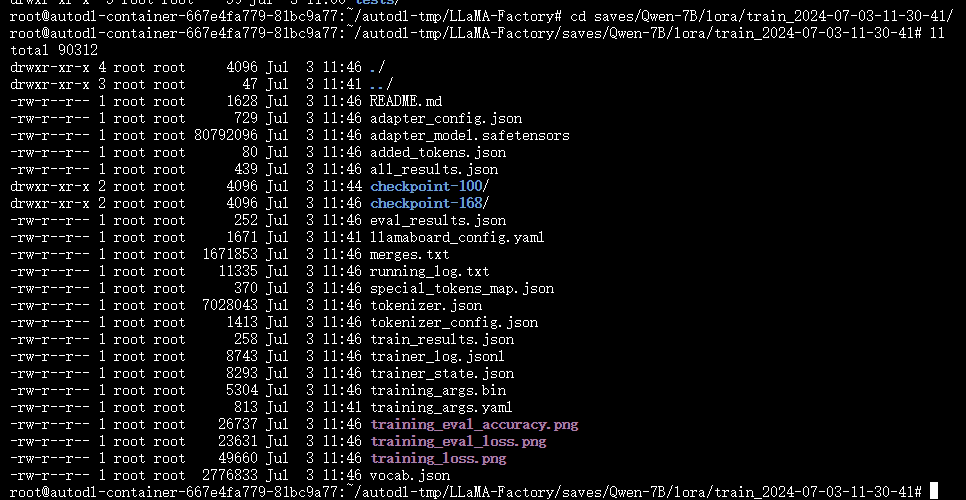
训练完成后,会在本地输出微调后的相关权重文件,Lora权重文件输出如下:
6、模型加载推理
在高级设置中有一个“Chat”页签,可用于模型推理对话
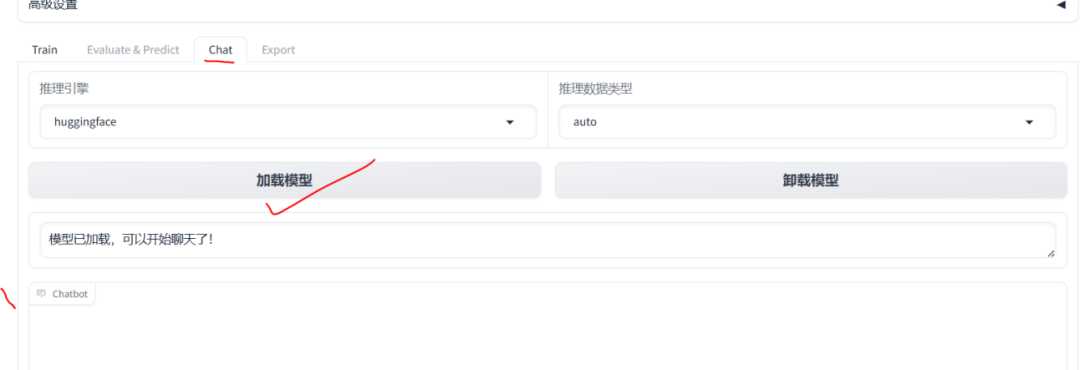
模型对话
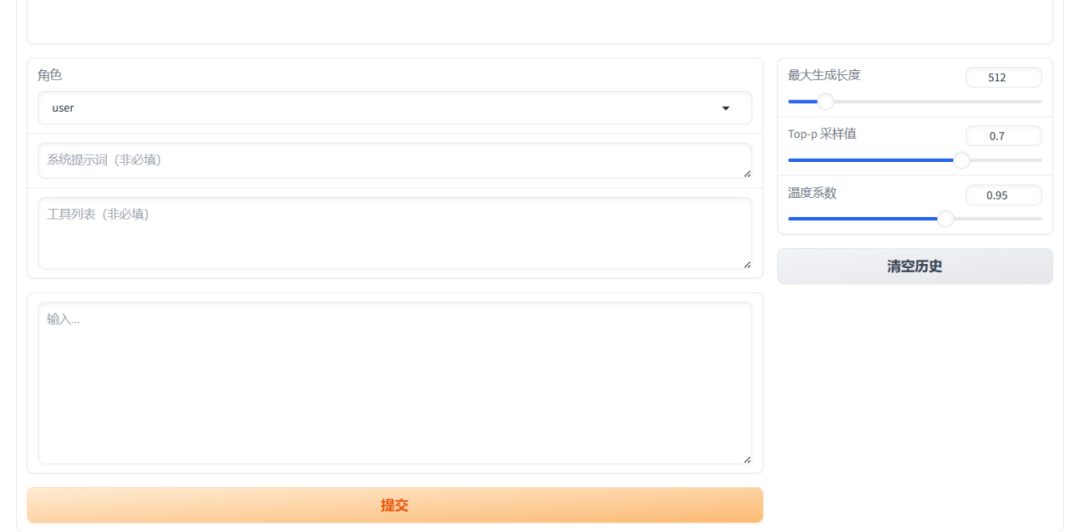
7、模型合并导出
模型训练完成后,我们可以将训练完后的Lora相关权重文件,和基础模型进行合并导出生成新的模型
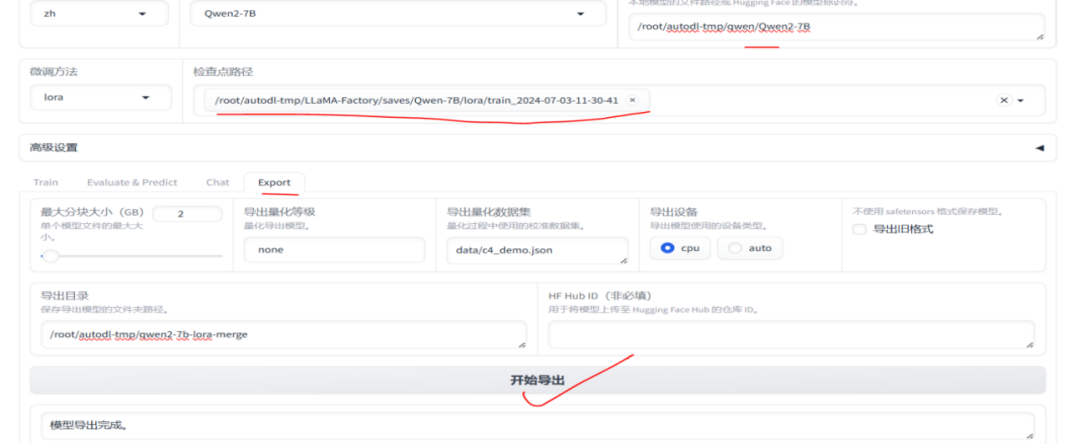
合并后模型文件如下:
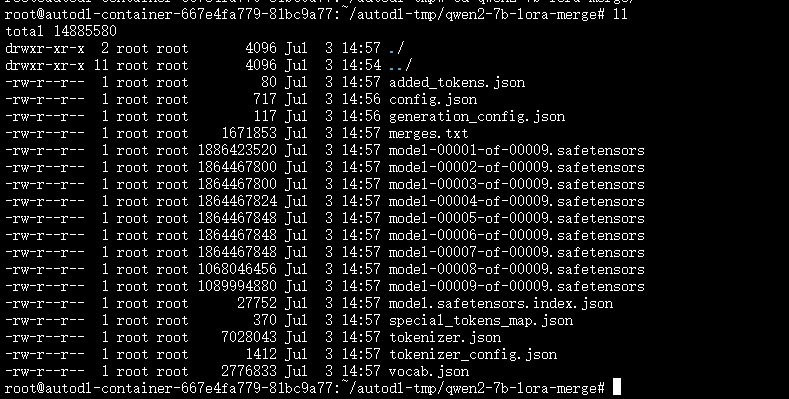
导出后我们可以基于导出后的新模型进行推理对话。
八、结语
通过本文的详细介绍,大家应该对如何使用LLaMA-Factory对Qwen2-7B进行微调有了清晰的认识。微调不仅能够提升模型在特定任务上的表现,还能够为模型赋予更加丰富的应用场景。希望本文能够为大家在大型语言模型的微调实践中提供有价值的参考和指导。随着技术的不断进步,我们期待LLaMA-Factory和Qwen2-7B能够在未来的AI领域发挥更大的作用。
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









