



通过数据要素建设推动人工智能大模型发 展,可以有效解决我国人工智能,特别是大模型研发所面临的数据瓶颈,进一步发挥大模型对于世界知识数据的汇 集和处理能力,创造更大的生产力,助力我国从数据经济走向智能经济新发展模式。
大模型是数据要素价值释放的最短路径,通过理解其训练所使用的数据类型,可以更好理解大模型发挥价值的 内在机制,破解对训练数据常见的迷思和误解。而促进高质量训练数据的建设,需要理解人工智能对数据的实际需 求,科学评价数据的规模和质量;需要综合利用政府、企业、社会等各方资源,构建共享、共创、共赢的合作生 态,以更务实、多元、开放的方式解决供给不足的问题;还需要为技术发展预留空间,构建更顺应模型发展的数据 治理体系,相信随着技术的日益成熟,相应的商业模式和制度设计也都会逐步完善。
训练数据对大模型发展的重要性
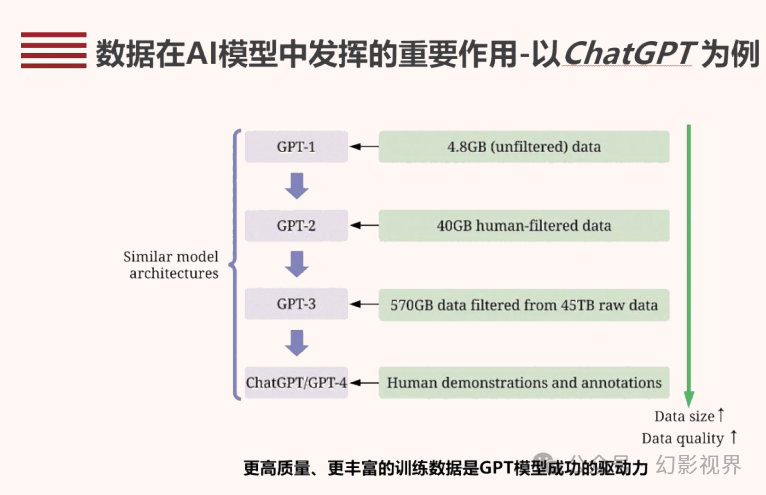
业界认为,算法、算力与数据,是支撑大模型发展的三大基石。更高质量、更丰富的数据是以GPT为例的生成式人工智能大模型成功的驱动力。GPT模型架构从第1代到第4代均较为相似,而用来训练数据的数据规模和质量却有很大的不同。GPT-1是由4.8G未过滤原始数据训练,GPT-2是由经人类过滤后的40G数据训练,GPT-3是由从45T原始数据中过滤的570G数据训练,而chatGPT/GPT-4则是在该基础上又加入了高质量人类标注。以吴恩达(AndrewNg)为代表的学者观点认为,人工智能是以数据为中心的,而不是以模型为中心。“有标注的高质量数据才能释放人工智能的价值,如果业界将更多精力放在数据质量上,人工智能的发展会更快”。
训练大语言模型的数据
大模型所需要的数据根据训练的阶段有所不同。以ChatGPT为代表的大语言模型(LLM)为例,其训练过程分为预训练(Pre-training)、监督微调(SFT)、基于人类反馈的强化学习(RLHF)三个阶段,后两部分又统称为“对齐”(Alignment)阶段。

训练多模态模型的数据
大语言模型迅速发展的同时,Transformer 开始迁移到图像、视频和语音等其他模态数据领域,并与大语言模 型融合,形成多模态大模型。多模态模型模拟人类大脑处理信息的方式,把各种感知模态结合起来,以更全面、综 合的方式理解和生成信息,最终实现更丰富的任务和应用。从以 Mid-journey 和 Sora 为例的多模态大模型看,在 训练阶段需要大量图像 - 文本对、视频 - 文本对等有标注数据集进行训练。图像 - 文本对是包含一张图像和一段描 述该图像内容的文本的数据,让模型学习组成图像的像素之间、文字与图像的关联。视频 - 文本对包括一个短视频 和一段描述视频中发生事件的文本,让模型不仅学习单个画面,还需要理解视频中的时间序列和动态变化。
报告原文节选如下:

下面这些都是我当初辛苦整理和花钱购买的资料,包括这本2024大模型训练数据白皮书,需要的小伙伴可以扫取。

















下面这些都是我当初辛苦整理和花钱购买的资料,包括这本2024大模型训练数据白皮书,需要的小伙伴可以扫取。

















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









