




LLMs在股票投资组合崩溃中的时间关系推理
1. 引言
想象一下,你是一位投资经理,管理着一个多元化的股票投资组合。突然,一场前所未有的全球性事件发生了,比如2007年的金融危机或2020年的新冠疫情,这可能会对你的投资组合造成重大影响。传统的投资组合崩溃检测方法依赖于历史数据,但这些方法在面对前所未有的事件时往往无能为力。幸运的是,大型语言模型(LLMs)的出现为解决这一问题提供了新的思路。
LLMs具有零样本推理能力,能够将训练数据中学习到的知识泛化到新的事件上,从而在没有特定训练数据的情况下检测潜在的投资组合崩溃事件。然而,检测投资组合崩溃是一个复杂的问题,需要超越基本推理能力。投资者需要动态处理新闻文章中发现的每条新信息的影响,分析新闻事件和投资组合股票之间影响的关系网络,以及理解不同时间步之间影响的时间上下文,以获得对目标投资组合的整体聚合效应。
2. 相关工作
2.1 关系型股票预测
在股票市场中,关系型信息预测是一个重要的研究领域。早期的研究使用关系元组(例如(行动者,动作,对象,时间戳))来学习嵌入,以便相似事件或相似股票实体具有相似的代表性向量。后来的研究使用基于图的方法,通过在知识图谱中学习嵌入来表示股票实体。然而,这些模型主要依赖于从中心数据库检索到的静态关系信息,并未考虑新闻事件可能引起的股票之间连接性的变化。
最近的研究使用LLMs从新闻标题中推断股票之间的关系,从而获得更具动态性的关系数据。这些信息随后用于生成股票嵌入,用于训练深度学习模型进行股票预测。
2.2 大型语言模型的推理框架
LLMs以其零样本推理能力而闻名,这主要归功于其能够将其在训练数据中学到的知识泛化到新的数据上。为了增强这种能力,研究人员提出了各种推理框架,例如思维树(ToT)和思维图(GoT)。这些框架旨在模拟人类的推理过程,通过搜索组合问题空间来找到任务解决方案。
另一类研究则通过使用包含外部信息的知识图谱来增强LLMs的可靠性,例如StructGPT和Think-on-Graph(ToG)。这些研究的一个关键观察结果是LLMs能够对知识图谱输入进行推理,这些输入以知识元组的形式提供。
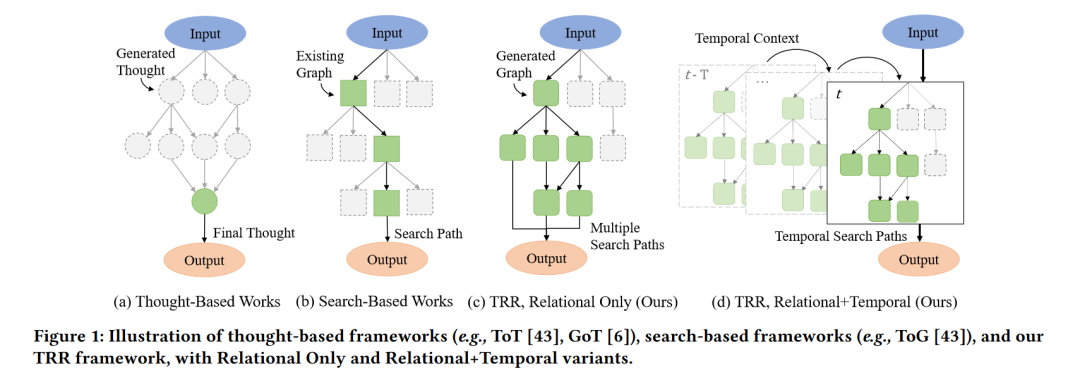
3. 时间关系推理
本文提出的TRR框架旨在模拟人类在解决复杂问题时使用的认知能力,包括头脑风暴、记忆、注意力和推理能力。
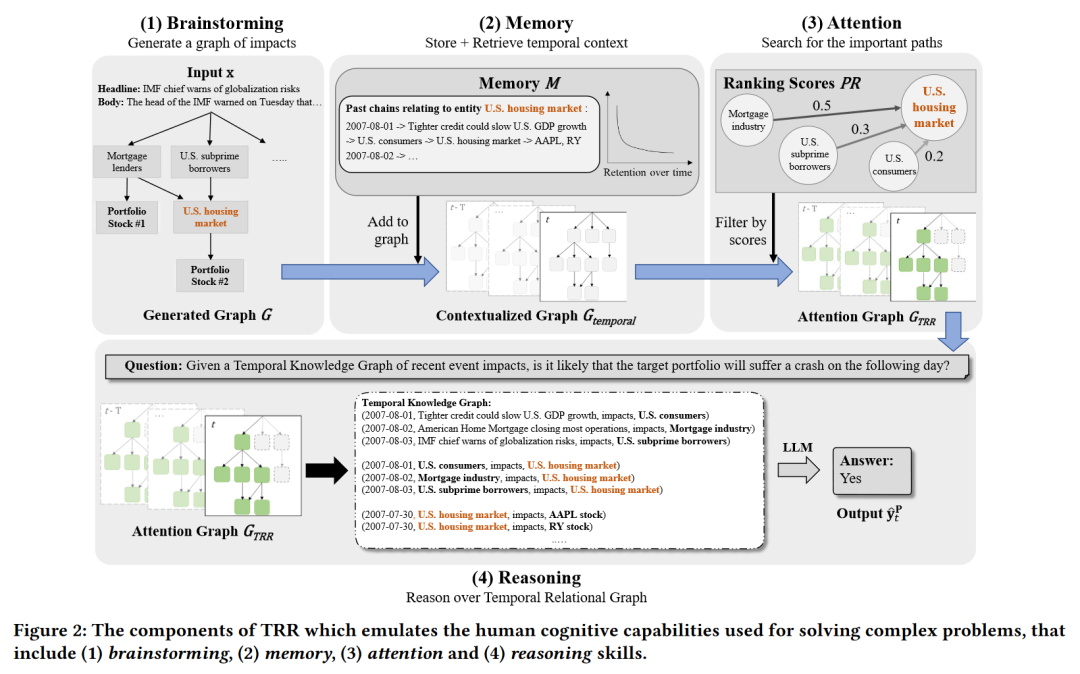
3.1 头脑风暴
为了获得每个新闻事件对选定投资组合的总体影响,TRR首先头脑风暴所有可能的子影响链,这些子影响链会导致其组成股票受到影响。该过程被建模为一个有向图G = (Z, A)。顶点集Z = {x1, …, xJ, e1, …, eH, s1, …, sN},从每个新闻文章xj开始,通过所有受影响的子实体en(其中h ≤ H),并以投资组合股票sn结束。边集A简单地表示顶点之间的影响力方向。
为了生成图的新顶点,TRR迭代地提示LLM根据每个新闻文章或先前受影响的子实体生成可能受影响的实体。因此,对于迭代i中的所有顶点zi ∈ Z,我们有zi → brainstorm(zi, k),其中k是生成的新顶点数量。这个过程迭代进行,直到影响链到达投资组合股票sn,或者达到最大迭代次数I。
3.2 记忆
为了理解新闻事件的时间上下文,TRR配备了一个记忆模块,该模块存储所有先前提到的受影响子实体。我们用M = {M0, M1, …}表示记忆模块,其中Men是包含实体eh的所有先前影响链Cen的集合。通过记忆模块,我们可以执行检索和存储功能:
- 每天,对于LLM生成的每个受影响实体,我们搜索记忆模块以查找其先前的提及,并将其添加到我们的每日图G中,从而得到一个新的时间上下文图Gtemporal。我们可以得到:Gtemporal = ∪ven∈Z (G ∪ Men)。
- 在每天结束时,我们用每日的影响链更新记忆模块,即Men = ∪ven∈Z (Men ∪ Cen),这为未来的时期存储了时间上下文。
此外,人类对新闻事件的集体记忆往往会随着时间的推移而逐渐淡忘,这会减少其对市场的影响。先前的研究使用指数衰减来模拟记忆的这种时间衰减。
3.3 注意力
总体上下文图Gtemporal太大,无法在LLMs中使用,因为它们的标记限制。虽然其他工作通过合并思想或找到单一回答路径来解决这个问题,但TRR希望保持信息的关系图,以向LLM提供市场概况。
Gtemporal包含一个影响链网络,对目标投资组合的影响强度不同。为了获得此网络上的最重要信息,TRR借鉴了PageRank算法,为每个实体分配排名分数。这是通过迭代地根据影响方向将分数传递给实体来完成的,直到分数收敛。此外,分数根据其在上一阶段的记忆中保留的权重进行加权。
使用排名分数PR(en),TRR过滤出包含得分最高的前q个实体的所有影响链C,其中q将被定义。这些用于形成一个新的子图GTRR,代表投资者每天关注的最重要信息。
3.4 推理
最后,为了确定是否会发生投资组合崩溃,TRR对生成的时间关系图GTRR进行推理。这模拟了投资者的推理过程,他们将通过考虑最相关的新闻影响以及组成股票之间的相互关联性来评估其投资组合风险。
4. 实验
4.1 数据集和评估指标
本文使用路透社金融新闻数据集,并将其扩展到2020年以涵盖选定的时间段。数据集包含来自路透社的一般金融新闻,这些新闻没有经过任何股票或国家的过滤。这允许LLM自行决定每篇文章是否与目标投资组合相关。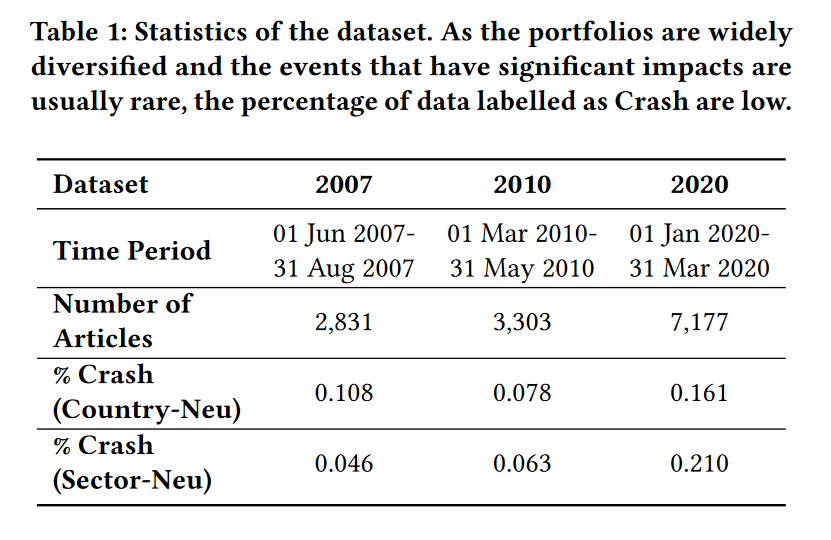
为了生成投资组合崩溃的标签,本文首先从雅虎财经检索每个组成股票的价格数据,并计算其每日百分比回报率。接下来,我们对这些数据进行平均,以获得每天的投资组合回报率。为了找到投资组合崩溃,本文设置了一个阈值来捕捉价值的急剧下降。我们将回报率≤ -2.0%标记为崩溃,这代表了整体回报率系列的第95百分位数。
由于这些崩溃的发生率很低,因此数据集在很大程度上是不平衡的,预测所有假(即没有崩溃)的模型将产生高准确率分数。本文使用接收者操作特征曲线下面积(AUROC)作为指标,该指标可以捕捉所有阈值下真阳性与假阳性的权衡。
4.2 基线
由于检测投资组合崩溃的任务目前尚未得到广泛探索,本文将其与多个零样本LLM框架进行比较,例如标准IO提示、思维链(CoT)、思维图(GoT)和基于图的思维(ToG)。此外,本文还与一个非零样本深度学习模型(BiGRU + Attention)进行了比较,该模型已在相同数据集的过去路透社新闻数据上进行了训练。
4.3 参数设置
对于所有LLM实验,本文使用OpenAI GPT-3.5-turbo生成响应,温度设置为0.0。对于最后一个推理阶段,每个模型重复预测提示5次,并报告平均AUROC和标准差。对于主要实验,本文将γ设置为1,将q设置为6。
5. 结果
5.1 主要结果
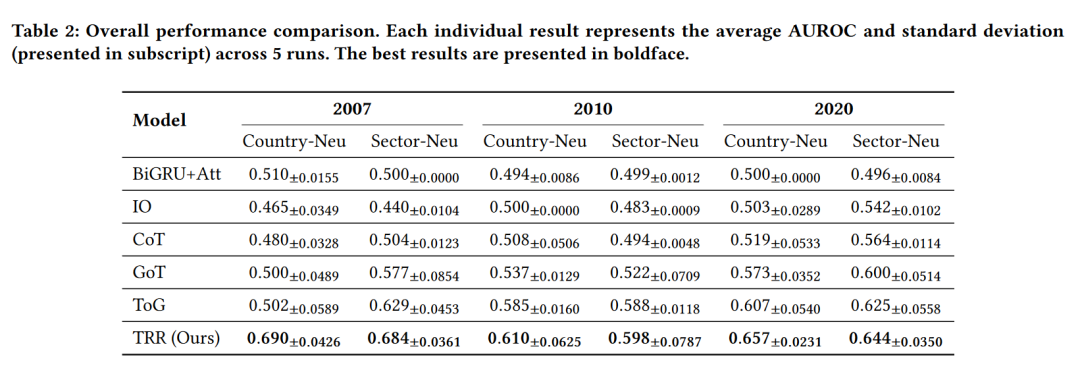
从表2可以看出,深度学习模型BiGRU + Attention的结果接近0.5。这是因为该模型主要预测假(注意,全真或全假预测的AUROC为0.5)。投资组合崩溃通常是罕见的,这会导致模型训练时对假预测产生很大的偏差。此外,该模型很可能无法处理训练集中以前未见过的事件,导致其对前所未有的崩溃事件预测假。
在基于思维的框架(即IO、CoT和GoT)中,我们可以看到AUROC指标的明显上升趋势。这表明将预测投资组合崩溃的任务分解为较小的思维过程是有益的。进一步观察,我们发现基于搜索的ToG能够胜过这些模型。由于输入数据集未经过手动过滤,因此可能存在许多包含与指定投资组合无关的噪声信息的新闻文章。通过首先从文章中搜索到投资组合的影响路径,ToG能够找到最相关的信息,以帮助其决定是否可能发生潜在的投资组合崩溃。
最后,TRR框架能够胜过所有模型,平均比最强的基线(ToG)高出10.6%。通过考虑与投资组合相关的多个影响路径以及这些路径之间的关系,TRR能够更全面地了解各种市场力量对投资组合的影响,从而更准确地检测潜在的崩溃。
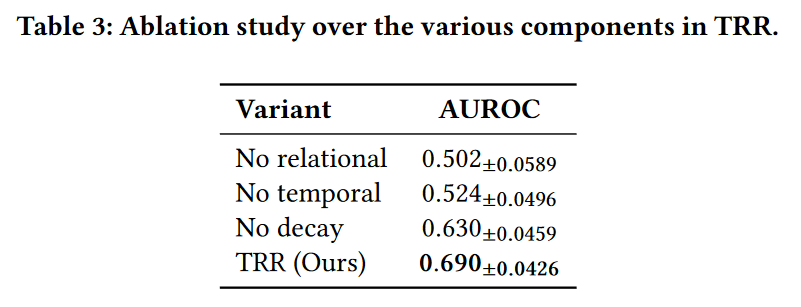
5.2 消融研究
消融研究的结果表明,TRR的每个组件都有助于提高模型的整体性能。关系和时间组件在推理阶段为LLM提供了额外的图路径,而不会降低性能,这表明从图中提取了有用的信息,而不是噪声数据。这些路径有助于提供有关每个新闻影响的额外上下文信息,从而使LLM能够更好地确定是否会发生崩溃。
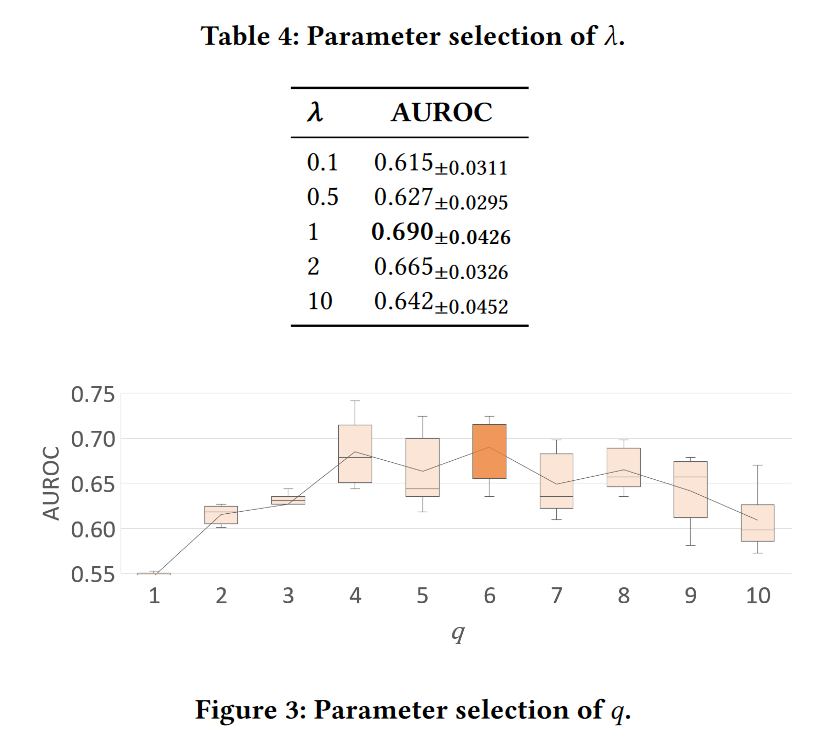
5.3 参数选择
通过消融研究,本文将γ设置为1,将q设置为6。
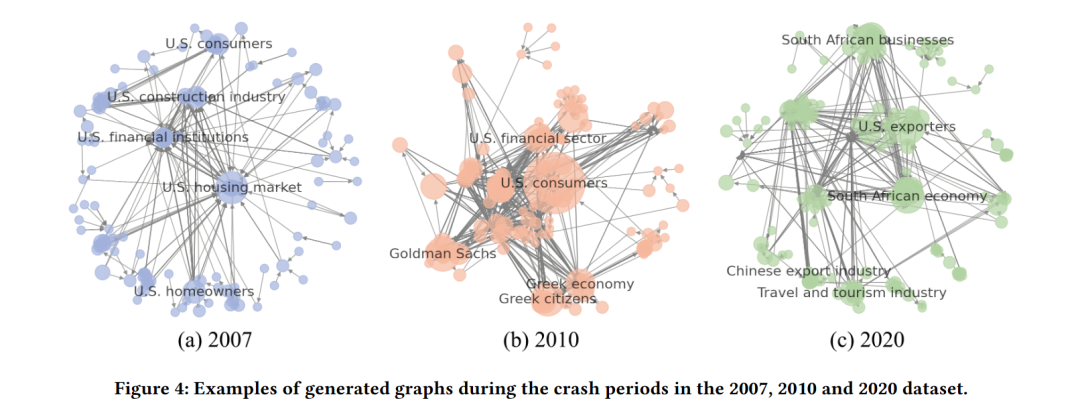
5.4 图分析
本文还通过可视化每个数据集在崩溃期间的示例来探索生成的图。从图中可以看出,TRR能够突出显示在现实生活中导致投资组合崩溃的最重要信息。
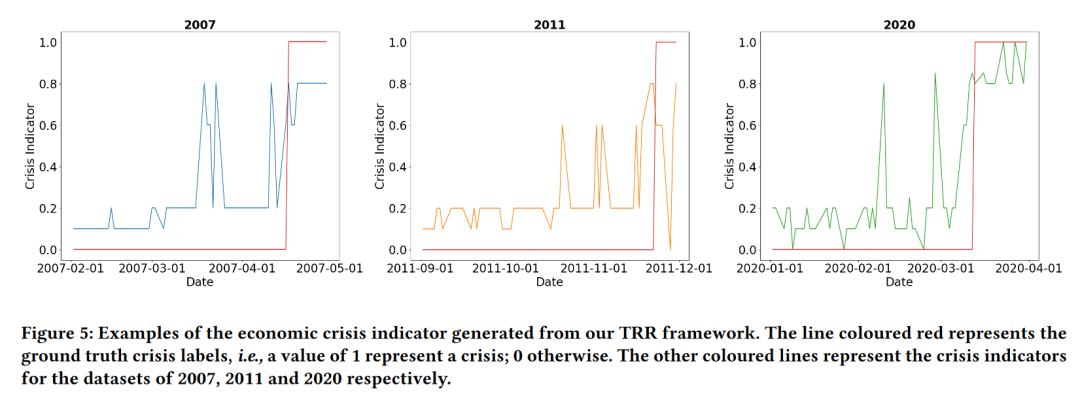
5.5 额外实验
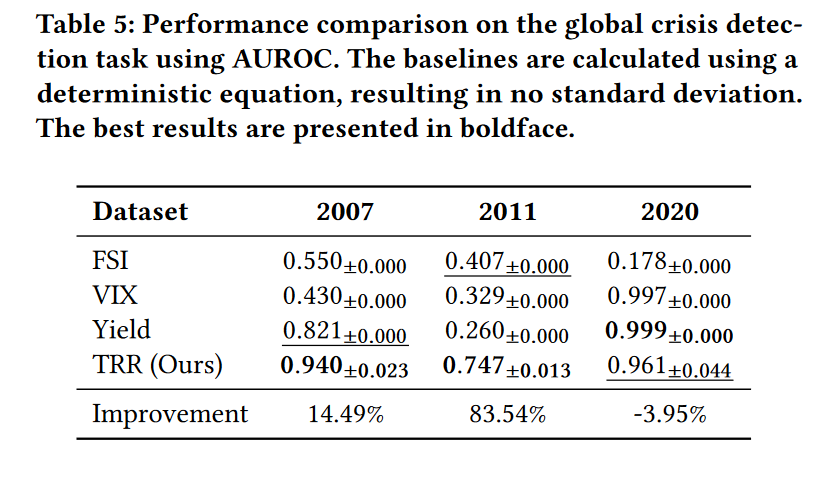
为了探索TRR对宏观经济中相关任务的泛化能力,本文将其应用于全球危机事件的检测。通过将全球经济视为区域经济网络,本文利用TRR追踪每个区域经济的影响,然后对这些影响进行推理,以检测可能的全球金融危机。
6. 结论与未来工作
本文探讨了投资组合崩溃检测的主要任务,这是在LLMs出现之前难以解决的问题,因为崩溃相关事件的前所未有性。本文提出了TRR框架,该框架能够通过一组人类认知能力对关系和时间信息进行零样本推理。通过广泛的实验,本文证明了TRR在检测投资组合崩溃方面优于最先进的框架。此外,本文还通过将其用于宏观经济中的危机预警指标,探索了TRR的泛化能力。
这项工作的结果为未来的研究开辟了一些可能的方向。首先,TRR中的每个单独组件都可以通过更专业的技术进行扩展。其次,对于危机检测任务,可以研究更多的基线,例如政府债务、对外贸易流动等。这些统计指标也可以与TRR方法一起用于集成系统,以帮助提高预警指标的预测能力。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









