




突破RL微调稳定性瓶颈:FP16精度如何解决训练-推理不匹配问题?
本文将介绍一项关于大语言模型强化学习微调稳定性的重要研究。研究发现,当前广泛采用的BF16精度格式是导致训练-推理不匹配的根本原因,而简单切换到FP16精度就能有效解决这一问题,带来更稳定的优化、更快的收敛和更强的性能表现。
论文标题:Defeating the Training-Inference Mismatch via FP16
来源:arXiv:2510.26788 [cs.LG],链接:https://arxiv.org/abs/2510.26788
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景
强化学习(RL)已成为提升大语言模型(LLMs)推理性能的强大范式,但通过RL实现高性能模型的路径往往充满不稳定性。训练过程对超参数极其敏感,可能遭受训练崩溃,使得可靠提升模型性能成为重大挑战。这种不稳定性的一个关键来源源于现代RL框架中的根本差异:训练-推理不匹配。为加速训练,这些框架通常使用不同的计算引擎,一个用于快速推理(rollout),另一个用于训练(梯度计算),尽管数学上相同,但由于精度误差和硬件特定优化,这些引擎会产生数值不同的输出。
研究问题
- 现有算法修复方案(如基于重要性采样的方法)计算效率低,需要额外前向传播计算重要性采样比,增加约25%的训练成本。
- 部署差距持续存在,这些解决方案在训练期间纠正不匹配,但最终模型参数是相对于训练引擎的概率分布优化的,导致部署时性能下降。
- 工程尝试(如手动对齐训练和推理实现)需要深度领域知识和大量工程工作,难以跨不同框架或模型推广。
主要贡献
- 识别出BF16精度是训练-推理不匹配的根本原因,尽管其动态范围大,但引入的舍入误差破坏了训练和推理之间的一致性。
- 证明简单切换到FP16精度能有效消除这种不匹配,该改变简单,现代框架完全支持,只需几行代码更改,无需修改模型架构或学习算法。
- 通过广泛实验验证,使用FP16在多样化任务、算法和框架中统一产生更稳定的优化、更快的收敛和更强的性能。
方法论精要
浮点精度格式比较
FP16(IEEE 754半精度)和BF16都使用16位,但位分配不同:
- FP16:5位指数位 + 10位尾数位,提供更高数值精度,但动态范围较小
- BF16:8位指数位 + 7位尾数位,提供与FP32相当的动态范围,但精度较低
BF16的广泛采用是因为其抗溢出和下溢能力强,使LLM训练更稳定,但其低精度正是训练-推理不匹配的根源。

FP16稳定性技术
通过损失缩放技术解决FP16的有限范围问题:
- 反向传播前将损失乘以大缩放因子S
- 这将所有梯度按S缩放,使小梯度值移出下溢区域进入FP16可表示范围
- 更新权重前,将梯度按S缩放回
现代框架(PyTorch、Megatron、DeepSpeed)已内置动态损失缩放,使FP16训练既简单又稳健。
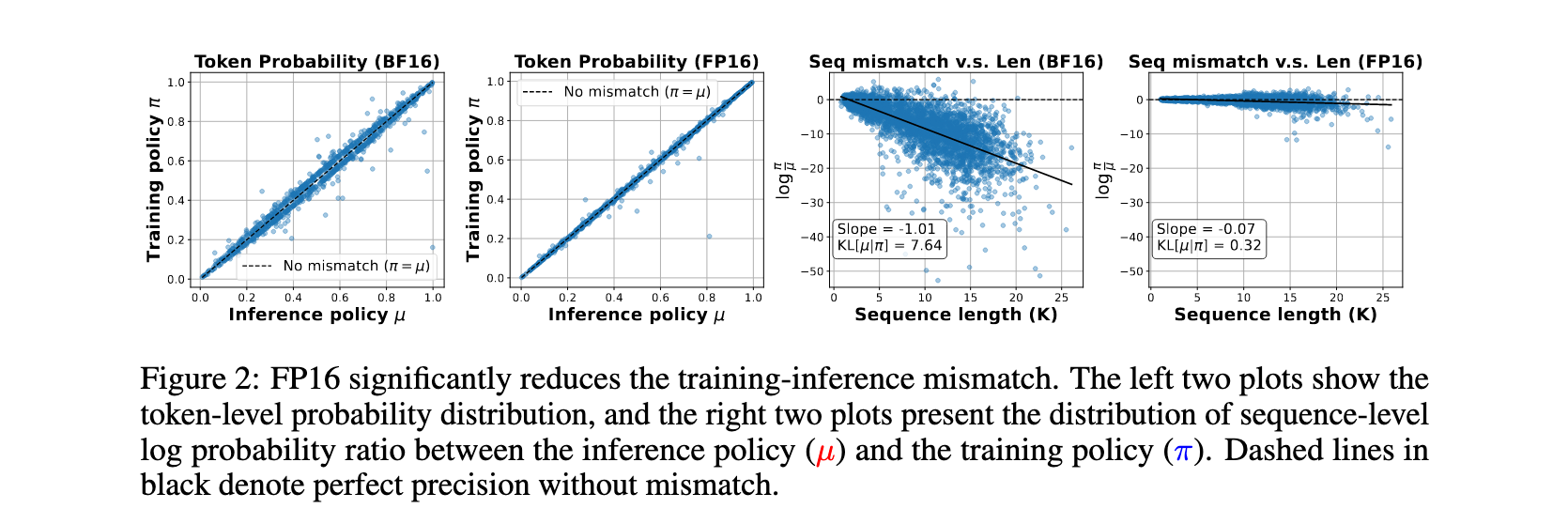
训练-推理不匹配分析
现代RL框架中不同引擎或优化内核用于训练和推理,即使都配置为BF16,实现上的细微差异(如CUDA内核优化、并行策略)会导致BF16上不同的舍入误差。当这些小差异在自回归采样过程中累积时,π和μ的最终概率分布可能显著分歧,这正是有偏梯度和部署差距的来源。
FP16的10位尾数比BF16的7位尾数提供8倍更高精度,这种更高保真度意味着训练和推理引擎的输出更可能数值相同,增加的精度创建了一个缓冲区,吸收两个引擎之间的微小实现差异,防止舍入误差累积并导致策略分歧。
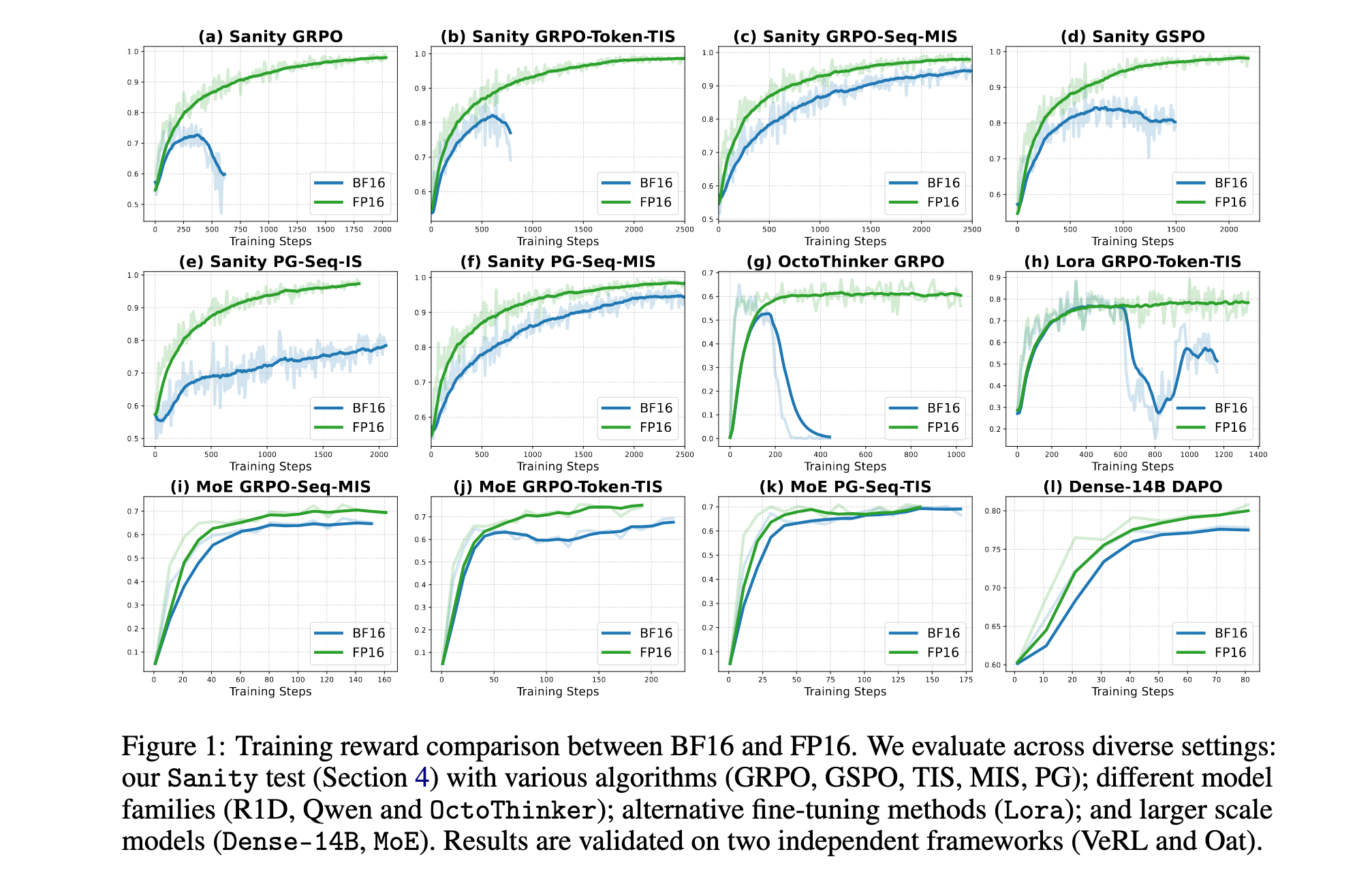
健全性测试设计
为严格评估RL算法的可靠性和鲁棒性,研究引入了新颖的健全性测试:
- 通过过滤过于平凡和无法解决的问题创建可完善数据集
- 对MATH数据集中的每个问题展开40个响应,仅保留初始准确率在20%到80%之间的问题
- 最终为DeepSeek-R1-Distill-Qwen-1.5B模型创建了包含1,460个问题的目标数据集
- 定义明确标准:RL算法如果在此可完善数据集上的训练准确率收敛到高阈值(如95%)以上,则通过测试
实验洞察
实验设置
使用DeepSeek-R1-Distill-Qwen-1.5B作为初始模型,上下文长度为8,000,每个实验在8个NVIDIA A100 80G GPU上运行。对于每个策略迭代,使用64个问题(每个问题8个rollout)的批量大小并执行4个梯度步骤。评估多种算法:
- 基础GRPO基线(Dr.GRPO变体)
- 带token级TIS校正的GRPO
- 带序列级MIS校正的GRPO
- 带重要性采样的标准策略梯度算法
- GSPO(主要用于解决MoE模型引入的不匹配)

算法校正比较
为确保鲁棒性并排除实现特定工件,在两个不同框架(VeRL和Oat)中进行实验:
- BF16精度下,基础GRPO基线早期崩溃,在VeRL中仅达到73%峰值准确率,在Oat中为84%
- Token级TIS校正略微延长训练但最终失败,在VeRL中崩溃前达到82%,在Oat中为88%
- GSPO显示出比GRPO with token-level TIS更稳定的训练时间
- 在BF16的所有算法校正中,只有GRPO with sequence-level MIS保持稳定训练而不崩溃,但收敛缓慢且存在显著部署差距
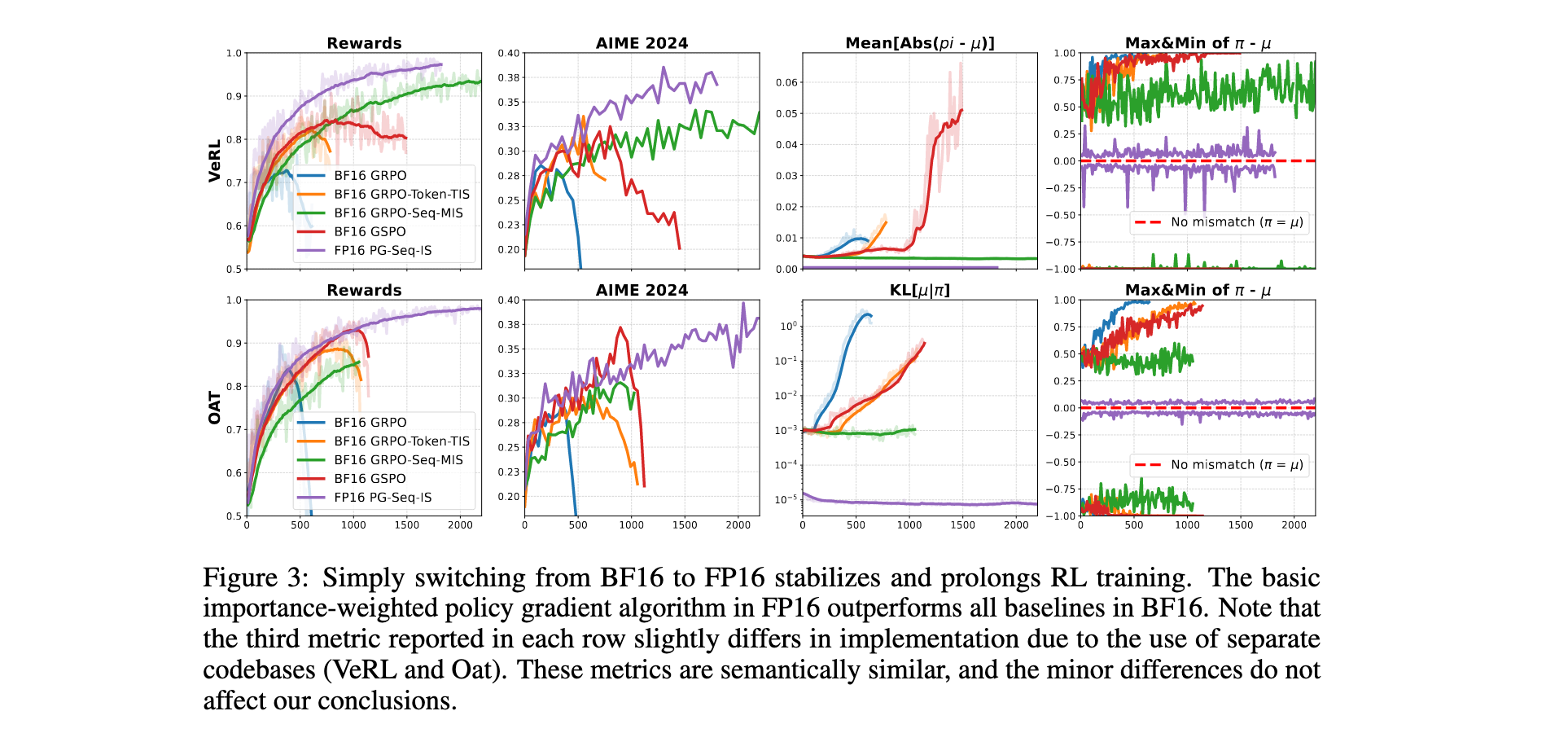
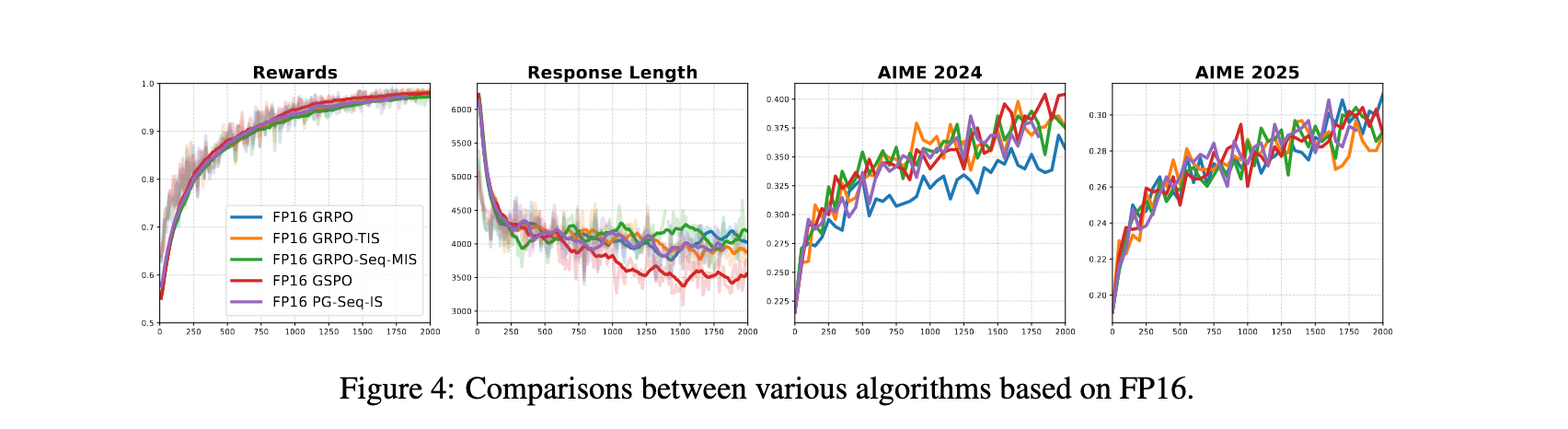
FP16精度的有效性
与这些算法方法相比,简单地将训练和推理精度从BF16切换到FP16提供了显著改进:
- FP16训练运行明显更稳定,收敛更快,在所有测试算法中实现更高的最终奖励和评估分数
- FP16精度从根本上改善了重要性采样的行为,序列级比率变得更加集中和稳定
- 简单的无偏策略梯度估计器在FP16驱动下显著优于BF16中所有现有算法校正
训练动态分析
实验结果揭示了一个有趣现象:最终崩溃的算法在之前始终表现出不断增长的训练-推理不匹配,使其成为潜在的早期预警信号。在此期间,策略差异π(·|θ’) - μ(·|θ’)也收敛到极端值,尽管使用相同权重副本,一个策略的概率接近1而另一个接近0。相比之下,稳定算法保持有界的不匹配。关键是,FP16训练显示出比任何BF16方法更低的不匹配水平。
多场景泛化验证
- MoE RL:在Qwen3-30B-A3B-Base上实验,FP16显示更大稳定性和一致更高的训练准确率以及验证奖励
- LoRA RL:在Qwen2.5-Math-1.5B模型上使用GRPO-Token-TIS,BF16-based LoRA训练在大约600步后崩溃,而FP16在整个过程中保持稳定训练
- 大型密集模型RL:在Qwen3-14B-Base上实验DAPO算法,FP16的训练奖励比BF16增长快得多,在AIME2024上实现更高验证准确率
- 其他模型族:在OctoThinker-3B(从Llama3.2-3B中训练)上实验,BF16训练在大约150步后因数值不匹配而不稳定,而FP16继续平滑训练而不会崩溃
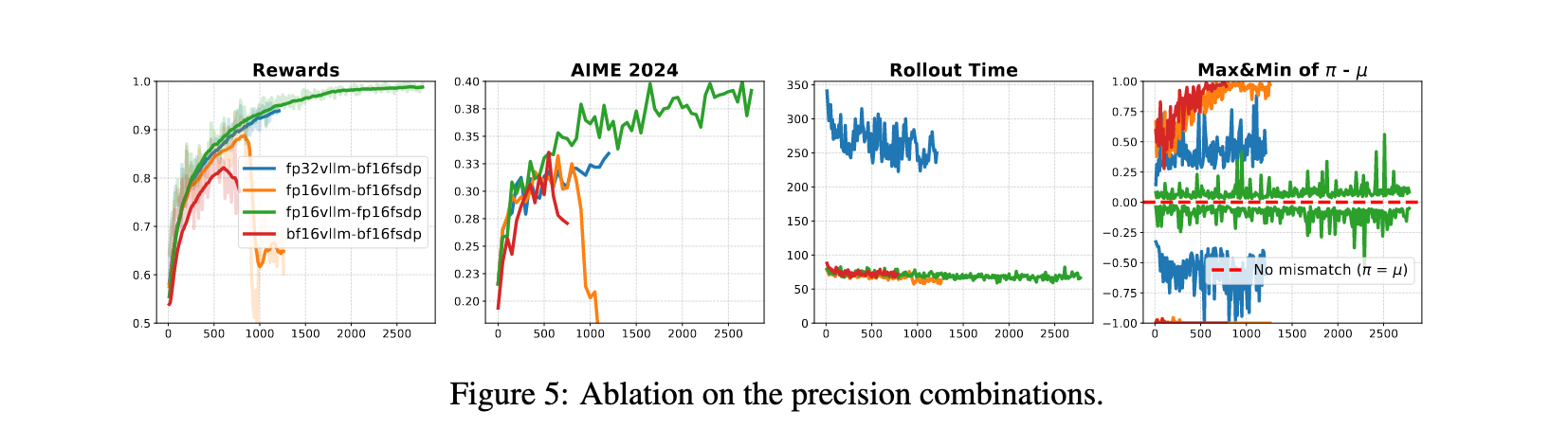
精度组合消融研究
为分离训练和推理精度的影响,在VeRL框架上进行了消融研究:
- 使用BF16精度训练时,增加推理精度始终延长训练稳定性并提高性能
- 当与FP32推理配对时,训练运行变得完全稳定,没有崩溃迹象,但成本巨大:FP32推理比FP16或BF16推理慢近三倍
- 使用FP16进行训练和推理产生最佳结果,不仅产生最低的训练-推理不匹配,而且导致最稳定的训练动态
结论与意义
这项工作证明,训练-推理不匹配(RL微调不稳定性的主要来源)根本上是数值精度问题。虽然现有的算法修复通常复杂且低效,但研究表明简单从标准BF16格式切换到更高精度的FP16格式可以几乎消除不匹配。这种单一、高效的改变导致更稳定的训练、更快的收敛和更优越的性能,证明在精度级别解决问题是更有效的策略。
研究结论是,应该重新考虑FP16作为LLM鲁棒RL微调的基础选择。这一发现对整个LLM训练栈具有重要意义,可能改变社区对精度权衡的默认认知,特别是在RL微调阶段。



















 243
243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









