



Google自己调优自己Transformer结构中的自注意力——分组自注意力机制
GQA分组自注意力也是google提出的
如今大模型都是基于transformer结构进行开发构建的,而提出transformer的鼻祖是google,虽然如今炒的大模型火热,google一度被认为不行了,但是从技术角度来看内行技术,google应该是一直引领人工智能发展的(当然比不上百度,人家可是提前几十年就布局人工智能了,google训练大模型都用百度数据毕竟),从tensorflow,到transformer,再到后续的一系列优化已经今天要讲的GQA分组注意力也是google提出,并被Meta等大模型广泛使用的。

GQA分组自注意力

论文地址:https://arxiv.org/abs/2305.13245
GQA(Grouped-Query Attention)技术在模型训练中提高效率的方式主要包括以下几个方面:
- 分组查询:GQA通过将查询(Query)向量分成多个组来工作,每组关注输入序列的不同部分。这种分组查询的方式减少了模型的计算复杂度,尤其是在处理长序列数据时。
- 减少计算量:由于每组查询向量可以并行处理,GQA可以减少模型的计算复杂度。在序列长度较大时,这种减少尤为明显。
- 提高内存效率:GQA通过减少每个注意力头需要处理的键(Key)和值(Value)的数量,有助于降低模型的内存占用。
- 保持性能:尽管减少了每个头的计算量,GQA仍然能够保持或甚至提高模型的性能,因为它允许模型以不同的“视角”关注输入的不同部分。
- 灵活性:GQA可以通过调整查询分组的数量来灵活地适应不同的计算预算和序列长度。
- 实现简化:在实现上,GQA通常涉及将查询矩阵分成多个较小的矩阵,并将它们与键和值矩阵相乘,然后对结果进行适当的组合以生成最终的输出,这样的实现相对简单。
- 与其他技术的结合:GQA可以与其他优化技术(如稀疏注意力模式、低秩近似等)结合使用,以进一步提高模型的效率。
- 减少KV Cache存储和读取次数:在MQA中,所有查询共享一个键值对,减少了KV Cache的存储和每次只需要读取一组KV,从而提高了模型效率。
- uptraining方法:GQA提出了从Multi-head模型快速微调得到GQA模型的方法,称为uptraining,这可以减少训练量同时保持模型性能。
GQA的计算原理图
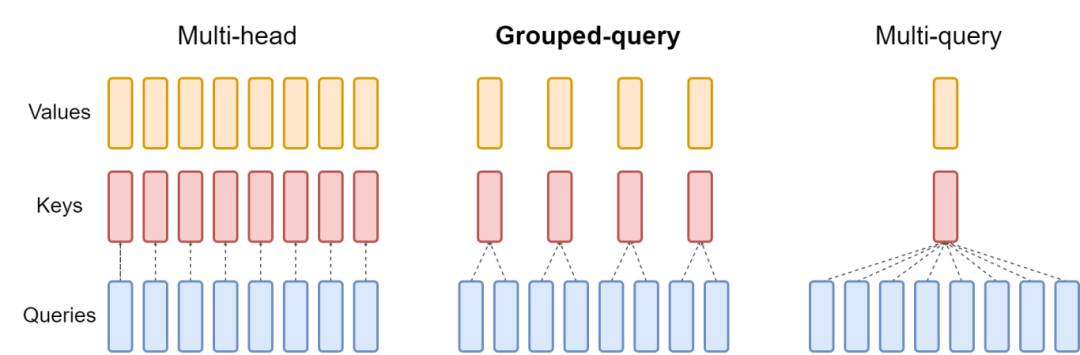
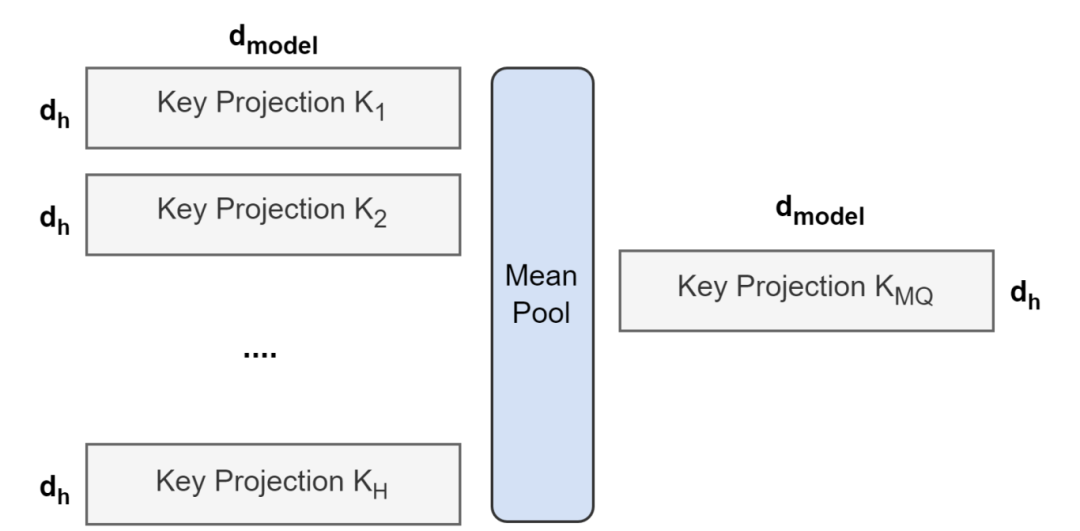
正常的多头自注意力会把qkv复制三份相同的,然后进行自注意力计算,这样浪费两倍空间。而GQA进行了分组,把q分为n组后,求均值作为k,v进行后续计算,这样就可以减少k,v的占用使用一组向量替代之前的多组向量进行计算,节省2*1/n空间了基本。此方法的妙处就在于减少了k,v的向量数据量,在矩阵计算的作用下(之前是一个向量乘一个向量,现在是n个向量乘一个向量)是不影响最终的输出结果的矩阵形状的,只是计算使用的矩阵减少了
另外说明一下:key取均值的方式也是官方论文说明的,一遍查询的资料都没讲明如何分组的细节额,其实官方文档已经说明了。
总结:Google在深度学习领域的深度和成就是巨大的,无可替代的,他提出的transformer结构真是的现在一切模型的基石,并且发展为了可以融合视觉,音频,文本的多模态模型重要结构,虽然在大模型浪潮下被openai等公司压过风头,但是其基础真的不可小觑,依然强劲。
本文讲述的分组注意力算是Transformer的一个巧思小优化了,极大节约了模型的空间。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 353
353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









